





Tích hợp khai phá dữ liệu trong InfoSphere Warehouse với việc tạo báo cáo Cognos của IBM, Phần 2: Phát hiện sai lệch với InfoSphere Warehouse và Cognos
lượt xem 23
download
 Download
Vui lòng tải xuống để xem tài liệu đầy đủ
Download
Vui lòng tải xuống để xem tài liệu đầy đủ
Phổ biến kết quả khai phá dữ liệu của bạn có hiệu quả Benjamin G. Leonhardi, Kỹ sư phần mềm, IBM Christoph Sieb, Kỹ sư phần mềm cao cấp, IBM Dr. Michael J. Wurst, Kỹ sư phần mềm cao cấp, IBM Tóm tắt: Trong phần trước của loạt bài này, bạn đã tìm hiểu cách hiển thị hóa các kết quả khai phá dữ liệu đơn giản trong IBM® Cognos®. Trong bài viết này, hãy tìm hiểu một số kỹ thuật tiên tiến, như hoạt động truy vấn ngược (drill-down) và trích xuất thông tin có cấu trúc từ các...
Bình luận(0) Đăng nhập để gửi bình luận!
Nội dung Text: Tích hợp khai phá dữ liệu trong InfoSphere Warehouse với việc tạo báo cáo Cognos của IBM, Phần 2: Phát hiện sai lệch với InfoSphere Warehouse và Cognos
- Tích hợp khai phá dữ liệu trong InfoSphere Warehouse với việc tạo báo cáo Cognos của IBM, Phần 2: Phát hiện sai lệch với InfoSphere Warehouse và Cognos Phổ biến kết quả khai phá dữ liệu của bạn có hiệu quả Benjamin G. Leonhardi, Kỹ sư phần mềm, IBM Christoph Sieb, Kỹ sư phần mềm cao cấp, IBM Dr. Michael J. Wurst, Kỹ sư phần mềm cao cấp, IBM Tóm tắt: Trong phần trước của loạt bài này, bạn đã tìm hiểu cách hiển thị hóa các kết quả khai phá dữ liệu đơn giản trong IBM® Cognos®. Trong bài viết này, hãy tìm hiểu một số kỹ thuật tiên tiến, như hoạt động truy vấn ngược (drill-down) và trích xuất thông tin có cấu trúc từ các mô hình khai phá dữ liệu với Cognos. Khi sử dụng kịch bản nghiệp vụ và ví dụ hoạt động đi kèm, cần hiểu nhiệm vụ khai phá dữ liệu về phát hiện sai lệch, đó là, nhiệm vụ nhận biết các bản ghi dữ liệu khác thường. Xem cách tìm các bản ghi như vậy với khai phá dữ liệu IBM InfoSphere™ Warehouse (Kho dữ liệu InfoSphere của IBM) và tạo các báo cáo tương tác cho phép thăm dò tương tác. Mở đầu Phát hiện hành vi đáng ngờ đúng lúc là một nhiệm vụ quan trọng trong nhiều ứng dụng CNTT hiện nay. Ví dụ, hãy tưởng tượng các giao dịch thẻ tín dụng. Nếu một người dùng cho thấy có hành vi mua sắm cao bất thường (ví dụ, mua sắm tại một cửa hàng giảm giá thường xuyên và sau đó mua đồ trang sức đắt tiền), thì thật là tốt để có thể kiểm tra các giao dịch tương ứng có dấu hiệu gian lận. Tuy nhiên, có thể sử dụng các sai lệch trong nhiều tình huống khác hơn là chỉ để phát hiện gian lận và giả mạo. Các cơ quan về nguồn nhân lực sử dụng việc phát hiện sai lệch để
- tìm ra các nhân viên hoặc các ứng cử viên không phù hợp với các phạm trù thông thường và có thể bỏ qua khi áp dụng các quy tắc cố định để xác định các tiềm năng cao. Các bản ghi dữ liệu lệch khỏi toàn bộ phân bố các bản ghi dữ liệu được gọi là các ngoại lệ. Việc xử lý ngoại lệ thường không phải là một nhiệm vụ hoàn toàn được tự động hóa. Đúng hơn là, sử dụng việc khai phá dữ liệu để chỉ ra các bản ghi dữ liệu đáng được xem xét kỹ hơn bởi một nhà phân tích hoặc một chuyên gia về con người, là người sau đó phải quyết định xem có hành động hay không. Vì thế, một giao diện người dùng và mô hình tương tác tinh vi là một điều kiện tiên quyết để xử lý thành công các ngoại lệ. Cognos rất thích hợp cho công việc này. Trên thực tế, một bản ghi tương tự như bản ghi được tạo ra trong bài viết đầu tiên của loạt bài này có thể được sử dụng để hiển thị trực quan các ngoại lệ. Hãy tận dụng toàn bộ tiềm năng của Cognos để hiển thị các ngoại lệ, tuy nhiên, bạn cần sử dụng một số tính năng cao cấp hơn. Trước tiên, hãy xem cách sử dụng "truy vấn ngược-drill- through" (ND: drill-through là một tính năng cho phép người dùng từ báo cáo tổng hợp tìm ngược về tận bản ghi dữ liệu gốc. Sau đây gọi là truy vấn ngược) để tạo các báo cáo Cognos tương tác và cách liên kết các bản ghi. Điều này sẽ giúp tóm tắt thông tin và vẫn dành chỗ để truy cập nhanh đến các bản ghi dữ liệu ngoại lệ có liên quan. Thứ hai, tìm hiểu cách có thể trích xuất thông tin bổ xung từ các mô hình khai phá dữ liệu giúp các chuyên gia về con người hiểu bản chất của một ngoại lệ. Ví dụ đang chạy trong bài viết này là một ứng dụng giúp các nhân viên của một ngân hàng nhận biết các khách hàng tỏ ra có hành vi bất thường. Có thể sử dụng việc này để tránh gian lận hoặc để phát hiện khách hàng đáng được quan tâm đặc biệt. Trong phần sau, trình bày một tổng quan về phát hiện sai lệch và xem cách có thể sử dụng InfoSphere Warehouse để tìm ra các ngoại lệ trong các tập dữ liệu lớn. Các phần tiếp theo trình bày các vấn đề cơ bản về truy vấn ngược (drill-through)
- và trích xuất thông tin từ các mô hình khai phá dữ liệu và cho thấy cách có thể sử dụng để cả hai kỹ thuật này để tạo ra các kết quả phát hiện sai lệch dễ hiểu và dễ sử dụng hơn. Phát hiện sai lệch với InfoSphere Warehouse Phát hiện sai lệch là gì? Phát hiện sai lệch được định nghĩa như là nhiệm vụ tìm các bản ghi dữ liệu bất thường trong các tập dữ liệu lớn. Các bản ghi này được gọi là các bản ghi ngoại lệ. Làm thế nào để định nghĩa chính xác "bất thường" là chủ đề tranh luận học thuật và cũng có thể phụ thuộc vào lĩnh vực áp dụng phát hiện sai lệch. Ở một mức chung, phát hiện sai lệch nhằm để tìm các bản ghi dữ liệu có các đặc tính không tuân theo sự phân bố thống kê của đa số các bản ghi dữ liệu. Tùy thuộc vào lĩnh vực của ứng dụng, các sai lệch có thể là: 1. Dữ liệu không đúng (ví dụ, nếu một người có tuổi là 300, đây có lẽ là do nhập không đúng vào cơ sở dữ liệu). 2. Hành vi bất thường của các quá trình phía dưới (ví dụ, các giao dịch thẻ tín dụng không thực hiện theo các quy trình thông thường). Do đó, có thể sử dụng việc phát hiện sai lệch cho các nhiệm vụ khác nhau. Nếu bạn giả định rằng dữ liệu của bạn có chứa dữ liệu không đúng, th ì bạn có thể áp dụng việc phát hiện sai lệch để làm sạch dữ liệu, vì thế hãy tìm kiếm các mục nhập không đúng trong cơ sở dữ liệu của bạn. Trong trường hợp thứ hai, dữ liệu đúng, nhưng cho biết rằng một số các quy trình được phản ánh trong các dữ liệu cho thấy có hành vi bất thường. Cùng với việc làm sạch dữ liệu, ứng dụng phát hiện sai lệch
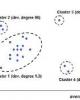
- chính thứ hai có thể được sử dụng để phát hiện gian lận. Như đã chỉ ra ở trên, hành vi bất thường không nhất thiết là gian lận. Ví dụ, nó cũng có thể cho biết các quá trình mới đang nổi lên, tức là "các khách hàng cao tuổi thực hiện quá nhiều các cuộc đấu giá trực tuyến". Việc phát hiện từ rất sớm các các quá tr ình đang nổi lên như vậy, cho phép các công ty cung cấp rất sớm các sản phẩm hay dịch vụ mới, tạo cho họ một lợi thế quan trọng so với đối thủ cạnh tranh. Một ứng dụ ng tương tự có thể có trong lĩnh vực tài chính. Việc phát hiện sai lệch được sử dụng để tìm các khoản đầu tư đầy hứa hẹn không phù hợp với các quá trình thông thường và vì thế cho đến nay vẫn chưa được công nhận. Trong mọi trường hợp, một nhà phân tích về con người phải kiểm tra các các bản ghi ngoại lệ để xem liệu các giá trị số liệu không đúng hay không hoặc liệu có phải thực hiện một số h ành động để tránh gian lận hoặc để tận dụng một số cơ hội cho đến nay vẫn chưa được công nhận không. Trong phần sau, hãy tìm hiểu cách InfoSphere Warehouse phát hiện các ngoại lệ và cách bạn có thể áp dụng việc phát hiện sai lệch cho dữ liệu của bạn. Phần còn lại của bài viết này thảo luận cách hiển thị trực quan các ngoại lệ tương tác trong Cognos. Phát hiện sai lệch trong InfoSphere Warehouse Trong những năm gần đây, người ta đã đề xuất nhiều phương pháp khác nhau để phát hiện sai lệch. InfoSphere Warehouse sử dụng một phương pháp đặc biệt mạnh mẽ dùng để phát hiện sai lệch đó là dựa trên phân cụm dữ liệu. Phân cụm biểu thị một kỹ thuật khai phá dữ liệu để phân nhóm các bản ghi dữ liệu th ành các cụm (cluster) có cặp bản ghi giống nhau theo các đặc tính của chúng. Chúng ta hãy xem Hình 1. Mỗi điểm trong biểu đồ đại diện cho một khách hàng. Trong trường hợp đơn giản này, các khách hàng chỉ được mô tả theo độ tuổi và số dư trung bình. InfoSphere Warehouse sử dụng một thuật toán phân cụm thống kê để phân nhóm các khách hàng giống nhau theo cả hai chiều thành đó thành các cụm. Như bạn thấy, có một số các cụm lớn hơn và tập trung nhiều hơn những cụm khác
- (Cluster 1 trái với Cluster 3). InfoSphere Warehouse kết hợp một số đặc tính để gán cho mỗi cụm một mức "độ lệch". Nếu mức độ lệch này cao hơn, nhiều khả năng các bản ghi trong cụm đó có thể được coi là các ngoại lệ. Hình 1. Phát hiện sai lệch bằng phân cụm Vì vậy, không có một sự phân biệt rõ ràng giữa ngoại lệ và không ngoại lệ. Do đó, người sử dụng phải xác định một ngưỡng cho các ngoại lệ. Tất cả các cụm có một mức ngoại lệ ở trên ngưỡng này được đánh dấu là các cụm ngoại lệ và tất cả các thành viên của chúng là các ngoại lệ. Ngưỡng này có thể được thiết lập theo hai cách. Thứ nhất, nếu bạn chỉ có một số lượng hạn chế các chuyên gia có khả năng kiểm tra các ngoại lệ, thì bạn chỉ cần sử dụng các bản ghi dữ liệu thuộc về các cụm có mức độ lệch cao nhất. Nếu bạn đang tìm kiếm các công ty hứa hẹn để đầu tư, bạn có thể sẽ bắt đầu với các cụm có mức độ lệch cao nhất và sau đó hạ dần mức của bạn xuống, miễn là bạn có các nguồn lực. Thứ hai, có thể cố định ngưỡng. Đây sẽ là trường hợp trong các kịch bản cảnh báo yêu cầu thực hiện hành động đó
- nếu có bất kỳ bản ghi dữ liệu mới nào được gán cho một cụm có một mức độ lệch trên ngưỡng cụ thể. InfoSphere Warehouse cho phép bạn thực hiện cả hai cách bằng cách chỉ cần gán một mã định danh cụm (id cluster) và một mức độ lệch tương ứng cho mỗi bản ghi dữ liệu. Bạn có thể hoặc lọc các bản ghi hoặc sắp xếp chúng để có được các ngoại lệ mà bạn muốn xem lại hoặc là bạn phải kiểm tra. Phần sau đây cung cấp một ví dụ từng bước một về cách tìm ra các ngoại lệ bằng InfoSphere Warehouse và cách gán các mức độ lệch cho các bản ghi dữ liệu riêng rẽ. Một ví dụ thực tế Trong ví dụ sau đây, việc phát hiện sai lệch được áp dụng cho các mục nhập về các khách hàng của ngân hàng. Dữ liệu mẫu của bảng tương ứng được chỉ trong Hình 2. Bảng BANK.BANKCUSTOMERS đi kèm với các mẫu của InfoSphere Warehouse. Hình 2. Dữ liệu mẫu trong bảng BANK.BANKCUSTOMERS Để phát hiện các ngoại lệ trong bài viết này: 1. Tạo một luồng khai phá mới, như đã thấy trong bài viết trước. 2. Ngoài ra, như đã thấy trong bài viết trước, bạn phải kéo một toán tử nguồn bảng vào trình soạn thảo.
- 3. Nhấn đúp vào toán tử để mở nó, chỉ rõ BANK.BANKCUSTOMERS làm bảng cơ sở dữ liệu nguồn và nhấn OK để xác nhận. 4. Bây giờ, kéo một toán tử "Find Deviations" (Các sai lệch tìm thấy) vào vùng bên cạnh nguồn bảng và nối chân đầu ra của nguồn bảng với chân đầu vào của "Find deviations". Thay đổi tên mô hình của mô hình cụm được toán tử "Find deviations" tạo ra thành IDMMX.OUTLIERMODEL. Nhấn đúp vào toán tử đó để mở các đặc tính và thay đổi tên mô hình trên trang trình thủ thuật thứ hai. 5. Cuối cùng, tạo ra một bảng đích phù hợp bằng cách chọn "Create Suitable Table..." (Tạo bảng thích hợp...) từ trình đơn ngữ cảnh nhấn chuột phải của cổng đầu ra của toán tử "Find Deviations". Trên trang trình thủ thuật đầu tiên, chọn lược đồ BANK (Ngân hàng) và nhập tên bảng là CUSTOMERS_OL. Nhấn chuột vào Finish. (Kết thúc). Một toán tử "Table Target" (Đích bảng) sẽ được nối tới luồng này. Nếu bạn muốn chạy luồng này nhiều lần, thì nên đánh dấu chọn hộp kiểm tra "Delete Previous Content" (Xóa nội dung trước) trong các đặc tính của các toán tử "Table Target". Luồng này chỉ cần nạp bảng khách hàng, chuyển nó tới thuật toán phát hiện sai lệch và viết các kết quả vào một bảng mới (xem Hình 3). Có thể được thấy trích xuất các kết quả trong Hình 4.
- Hình 3. Sử dụng luồng khai phá để phát hiện sai lệch. Như bạn thấy, có hai cột bổ sung, cụ thể là cột DEV_DEGREE và cột CLUSTER_ID. Cột Mức độ lệch đầu tiên chỉ rõ làm thế nào để coi bản ghi này là một ngoại lệ. Cột mã định danh cụm là mã định danh của cụm "ngoại lệ" có bản ghi này thuộc về nó. Có thể trích xuất thông tin bổ sung về các cụm n ày nhờ phân tích mô hình cụm đã được toán tử sai lệch tìm thấy tạo ra bên trong. (Bài viết này thảo luận về điều này sau).
- Hình 4. Dữ liệu mẫu từ bảng kết quả, BANK.CUSTOMER_OL Tạo một báo cáo Cognos tương tác để phát hiện sai lệch Trong phần này, hãy tìm hiểu cách để tạo ra một báo cáo Cognos cho phép bạn kiểm tra các ngoại lệ theo cách tương tác. Đầu tiên, bạn có thể sử dụng một báo cáo tương tự như trong bài viết đầu tiên của loạt bài này. Thay cho một bảng các bệnh nhân với một bộ chỉ báo cho biết những ai trong số họ đ ược đề xuất khám sức khỏe, bây giờ bạn có một danh sách các khách hàng với một bộ chỉ báo cho biết các khách hàng nào cần được kiểm tra về hành động gian lận hoặc khả nghi. Trong khi cách tiếp cận này hoạt động tốt với một lượng các khách hàng nhỏ hơn, nên một danh sách có hàng ngàn mục nhập sẽ không thuận tiện. Ngoài ra, một nhà phân tích có thể muốn xem cái gì làm cho một khách hàng cụ thể trở thành một "ngoại lệ". Bạn cần một số thông tin bổ sung để đưa ra một lời giải thích như vậy. Vì thế, chúng ta hãy mở rộng phương pháp đơn giản này theo hai cách: Nhóm các khách hàng theo nghề và đưa ra một tổng quan về có bao nhiêu các ngoại lệ có thể có theo từng thể loại nghề. Việc dùng loại phân nhóm này là một cách hay để đối phó với số lượng lớn thông tin. Ví dụ, người ta có thể cho rằng mỗi thể loại được xem xét và phân tích bởi một nhân viên
- cụ thể chịu trách nhiệm về thể loại này. Thay vì theo nghề nghiệp, cũng có khả năng theo các lĩnh vực khác (chẳng hạn theo vị trí). Làm giàu cho mỗi bản ghi ngoại lệ bằng thông tin về lý do tại sao coi bản ghi cụ thể là một ngoại lệ. Như đã nói ở trên, mỗi bản ghi được gán cho một cụm và tất cả các thành viên của một cụm chia sẻ cùng một mức độ lệch. Bạn có thể sử dụng các đặc tính của một cụm để mô tả các ngoại lệ. Ví dụ, nếu một cụm chứa hầu hết nhưng người rất trẻ có số dư trung bình cao thì điều này có thể là một lời giải thích tốt về lý do tại sao cụm này được xác định là một ngoại lệ. Phần sau đây trước tiên cho thấy cách làm giàu các ngoại lệ bằng thông tin bổ sung. Sau đó, bạn sẽ tạo ra một bản ghi tương tác để phân nhóm các khách hàng theo nghề của họ và cho phép bạn chọn các ngoại lệ một cách tương tác theo một thể loại cụ thể bằng cách sử dụng tính năng "truy vấn ngược" (drill-through) của Cognos. Trích xuất thông tin bổ sung từ các mô hình khai phá dữ liệu Bảng CUSTOMER_OL chứa thông tin có liên quan về các ngoại lệ. Như đã nói ở trên, mỗi bản ghi được gán cho một cụm. Toán tử "Find Deviations" tạo ra một mô hình cụm trên nền tảng lưu trữ thông tin chi tiết về các cụm này. Thông tin này được lưu trữ theo định dạng PMML (Predictive Model Markup Language-Ngôn ngữ đánh dấu mô hình dự báo) trong cơ sở dữ liệu. Nó chứa thông tin về: Sự phân bố các giá trị trong một cụm. Số lượng bản ghi trong một cụm. Tầm quan trọng của các biến cho mỗi cụm. Tính đồng nhất của các cụm.
- Nhiều thông tin hơn nữa. Bạn có thể sử dụng các thủ tục lưu sẵn có trong InfoSphere Warehouse để trích xuất thông tin này vào các bộ kết quả có thể được sử dụng trong Cognos. Các tập kết quả này có thể được coi là "các khung nhìn" không chỉ được tạo rõ ràng trong cơ sở dữ liệu nhưng còn được tạo ra trong lúc đang chạy bằng các thủ tục lưu sẵn. Nếu bạn muốn trích xuất thông tin nguyên văn về các cụm, bạn có thể sử dụng lệnh sau đây: SELECT ID, DESCRIPTION FROM TABLE(IDMMX.DM_GETCLUSTERS((SELECT MODEL FROM IDMMX.CLUSTERMODELS WHERE MODELNAME='IDMMX.OUTLIERMODEL'))) AS CT Lệnh này sẽ cung cấp cho bạn một bảng chứa các cột sau: ID: mã định danh của cụm (tương ứng với ID trong bảng CUSTOMER_OL). DESCRIPTION (Mô tả): Mô tả nguyên văn của cụm này. Các tập kết quả như vậy có thể được Cognos sử dụng như là các khung nhìn hoặc các bảng chính quy. Điều duy nhất bạn phải nhận biết l à các thủ tục đã lưu trữ này không chỉ được bao gồm trong DB2 mà còn được InfoSphere Warehouse thêm vào. Hãy quay lại phần này sau một lát nữa. Hình 5 tóm tắt hai cách lấy thông tin từ InfoSphere đến Cognos: theo các khung nhìn/các bảng cơ sở dữ liệu đơn giản hoặc theo các trích xuất từ các mô hình khai phá đang sử dụng các thủ tục đã lưu trữ. Các thủ tục đã lưu trữ này không chỉ tồn tại với các mô hình cụm mà còn với nhiều mô hình khai phá khác. Với một danh sách đầy đủ các hàm trích xuất mô hình có sẵn, hãy xem tài liệu InfoSphere Warehouse (xem phần Tài nguyên).
- Trong phần sau đây, chúng tôi sẽ cho bạn thấy có thể sử dụng Nh à quản lý khung công tác Cognos (Cognos framework mana ger) để kết hợp cả hai loại thông tin như thế nào. Hình 5. Hai cách truy cập thông tin liên quan đến khai phá trong Cognos Nhập khẩu và kết hợp các kết quả khai phá trong Cognos Framework Manager Với báo cáo của mình, bạn cần hai chủ thể truy vấn trong dự án Cognos mà sau đó bạn nối vào để có được một sự mô tả nguyên văn cho mỗi ngoại lệ: Một chủ thể truy vấn đơn giản truy cập vào bảng ngoại lệ BANK.CUSTOMER_OL được tạo trong phần đầu tiên. Chủ thể truy vấn này chứa bản ghi khách hàng cùng với mức độ lệch và mã định danh cụm. Một chủ thể truy vấn có sử dụng một thủ tục đã lưu để truy cập thông tin cụm của mô hình phân cụm do thuật toán khai phá tạo ra. Như mô tả ở trên, trong số các thông tin khác, thông tin cụm chứa một mô tả văn bản ngắn của cụm (trong trường hợp này, đó là một mô tả tất cả bản ghi ngoại lệ trong cụm này).
- Trước tiên, bạn phải tạo ra một dự án Cognos Framework Manager được kết nối đến cơ sở dữ liệu mẫu DWESAMP của InfoSphere Warehouse và có bảng BANK.CUSTOMERS_OL, được tạo ra ở trên. Trong bài viết đầu tiên của loạt bài này đã cung cấp hướng dẫn chi tiết về cách đạt được điều này. Đó là cách làm tốt để tạo ra một chủ thể truy vấn trong vùng tên PresentationView (Khung nhìn trình diễn) có chứa thông tin bạn cần từ cơ sở dữ liệu để có một tầng trừu tượng trên các chủ thể truy vấn, được tạo ra từ các câu lệnh SQL. Điều này cũng cho phép bạn thay đổi các tên cột theo các văn bản có tính mô tả hơn và thêm các cột bổ sung. Bạn cần một mục truy vấn cờ-ngoại lệ để cho biết liệu một bản ghi đã được coi là một ngoại lệ chưa. Hãy tính toán điều này từ mục truy vấn mức độ lệch DEV_DEGREE. Để tạo chủ thể truy vấn bảng ngoại lệ được báo cáo này sử dụng: 1. Tạo một chủ thể truy vấn mới "OutlierTable" (Bảng ngoại lệ) trong vùng tên PresentationView từ mô hình (các chủ thể truy vấn và các mục truy vấn hiện có). 2. Thêm tất cả các mục truy vấn từ chủ thể truy vấn CUSTOMER_OL và thay đổi các tên cho các nhãn có tính mô tả hơn. 3. Thêm một mục truy vấn mới với định nghĩa biểu thức sau đây: IF ([PresentationView].[OutlierTable].[Deviation factor] > 1000) then (1) else (0) 4. Mục truy vấn này sẽ bằng "1" nếu độ lệch cao hơn 1000; nếu không nó sẽ bằng "0". Tham số độ lệch 1000 đã được chọn làm một tham số ngưỡng độ nhạy cho tập dữ liệu của chúng ta. Thật có ích để làm cho độ nhạy sai lệch này được tham số hóa để trả về nhiều hay ít các bản ghi là các ngoại lệ.
- Định nghĩa chủ thể truy vấn của bạn sẽ trông giống nh ư Hình 6: Hình 6. Định nghĩa chủ thể truy vấn của bảng ngoại lệ Mục truy vấn thứ hai là một bảng có thông tin về các cụm của mô hình phân cụm đã được tạo ra trong quá trình chạy độ lệch tìm thấy. Mô tả dạng bảng này của mô hình phân cụm có thể được trích xuất trong Khai phá dữ liệu InfoSphere Warehouse bằng hàm do người sử dụng định nghĩa IDMMX.DM_GETCLUSTERS trả về một bảng các cụm trong mô hình cùng với một mô tả văn bản ngắn về phân bố trường trong cụm này. Các mô hình phân cụm được lưu như CLOBS trong bảng IDMMX.CLUSTERMODELS cùng với một cột "MODELNAME" có thể được dùng để chọn mô hình đúng. Hàm do người dùng định nghĩa cần được bao bọc trong một câu lệnh SELECT do Cognos sử dụng. Do các hàm bảng Khai phá InfoSphere Warehouse không phải là các hàm DB2 chuẩn, nên cần thay đổi một số tùy chọn Cognos trước khi có thể tạo chủ thể truy vấn này.
- Để tạo chủ thể truy vấn mô tả cụm từ hàm bảng DB2: 1. Chọn cơ sở dữ liệu DWESAMP trong thư mục Data Sources (Các nguồn dữ liệu) của Project Viewer và thay đổi đặc tính "Query Processing" (Xử lý truy vấn) trong khung nhìn các đặc tính thành "Limited Locale" (Vị trí giới hạn). Điều này cho phép các chủ thể truy vấn từ SQL mà Cognos vẫn chưa biết. 2. Tạo một chủ thể truy vấn mới "OutlierClusters" (Các cụm ngoại lệ) trong vùng tên PresentationView và lựa chọn để mô hình hóa chủ thể truy vấn từ một nguồn dữ liệu. Việc mô hình hóa nó từ một thủ tục đã lưu sẽ chỉ hỗ trợ cho các thủ tục đã lưu trữ mà Cognos đã biết. 3. Trên trang "Select a data source" (Chọn một nguồn dữ liệu), chọn DWESAMP và xóa dấu chọn hộp kiểm tra Run database query subject wizard (Chạy trình thủ thuật chủ thể truy vấn cơ sở dữ liệu). Trình thủ thuật chủ thể truy vấn chỉ làm việc cho SQL chuẩn. Nhấn Finish. 4. Sau khi đã tạo ra chủ thể truy vấn, trình thủ thuật Query Subject Definition (Định nghĩa chủ thể truy vấn) sẽ mở ra. Nhập mã SQL để trả về các cụm trong mô hình đó, ở đây IDMMX.OUTLIERMODEL là tên của mô hình phân cụm được tạo ra trong quá trình chạy "các độ lệch tìm thấy". SELECT * FROM TABLE(IDMMX.DM_GETCLUSTERS((SELECT MODEL FROM IDMMX.CLUSTERMODELS WHERE MODELNAME='IDMMX.OUTLIERMODEL'))) AS CT
- 5. 6. Do lúc này không có Cognos nào phù hợp với SQL, nên kiểu truy vấn SQL cần phải được thiết lập tới "Native" (Nguyên gốc), để nói cho Cognos biết chuyển SQL tới cơ sở dữ liệu, thay vì giải thích nó. Để thay đổi thiết lập này, hãy mở thẻ "Query Information" (Truy vấn thông tin) của các đặc tính các chủ thể truy vấn. Chọn "Options" (Các tùy chọn) và thay đổi "SQL type" trong thẻ "SQL settings" (Các giá trị cài đặt SQL) thành "Native". 7. Việc chạy "Test Sample" (Kiểm tra mẫu) cần trả về một bảng có các cụm của mô hình đó, như cho thấy trong Hình 7: Hình 7. Các kết quả kiểm tra của chủ thể truy vấn cụm ngoại lệ Việc sử dụng một thủ tục đã lưu trữ làm đầu vào chủ thể truy vấn có lợi thế là không tạo ra các bảng hoặc các khung nhìn không cần thiết trong cơ sở dữ liệu.
- Quan trọng hơn, thủ tục đã lưu trữ sẽ được thực hiện trong việc tạo báo cáo. Điều này làm cho có khả năng thực hiện động các tính toán khai phá tại thời điểm tạo báo cáo. Chủ thể này được trình bày nhiều hơn trong các bài viết sắp tới của loạt bài này. Để tạo các bản ghi đã nối các bảng các chủ thể truy vấn OutlierTable (Bảng ngoại lệ) và OutlierClusters (Các cụm ngoại lệ), bạn phải tạo ra một mối quan hệ giữa mã định danh cụm đã cho điểm của các bản ghi ngoại lệ và mã định danh cụm của bảng cụm. Để tạo một mối quan hệ giữa các chủ thể truy vấn OutlierTable và OutlierClusters: 1. Chọn Create Relationship (Tạo mối quan hệ) từ trình đơn ngữ cảnh của OutlierTable này. 2. Với chủ thể truy vấn bên trái, chọn mã định danh cụm của OutlierTable và thiết lập cardinality (số các tham số trong một tập) là 1..n do có quá nhiều bản ghi thuộc cùng một cụm. 3. Với chủ thể truy vấn bên phải, thêm chủ thể truy vấn OutlierClusters, chọn cột ID và thiết lập cardinality là 1..1 do chỉ có một hàng cho mỗi cụm. 4. Chọn OK. Hình 8. Mối quan hệ giữa các chủ thể truy vấn OutlierTable và
- OutlierClusters Bây giờ bạn đã tạo ra các chủ thể truy vấn cần thiết cho báo cáo Cognos và có thể triển khai một "OutliersPackage" (Gói các ngoại lệ) có chứa các Presentati onView của dự án cho Cognos Content Store (Kho lưu trữ nội dung Cognos). Việc tạo và triển khai gói đạt được đúng như đã mô tả trong bài viết trước của loạt bài này.
- Hình 9. Các tài nguyên được tạo trong Framework Manager Liên kết các báo cáo Cognos bằng truy vấn ngược (drill-through) Khái niệm ban đầu của "drill-through" nói đến nhiệm vụ chuyển hướng từ các giá trị tổng hợp đến các bản ghi riêng biệt. Đây là một nhiệm vụ phổ biến trong các ứng dụng OLAP. Trong Cognos, khái niệm này được dùng theo nghĩa rộng hơn như là bất kỳ loại "liên kết" các báo cáo nào với nhau. Như vậy, các định nghĩa truy vấn ngược (drill-through) phù hợp với một mục đích tương tự như các siêu liên kết trong HTML. Liên kết các báo cáo tự nó sẽ không phải là một tính năng rất mạnh mẽ. Điều làm cho các định nghĩa truy vấn ngược (drill-through) trở thành một công cụ mạnh là sử dụng các tham số. Ví dụ, mỗi báo cáo trong Cognos có thể chứa các tham số có thể được sử dụng để tạo các truy vấn dễ tham số hóa. Nếu các tham số này không được thiết lập, người dùng sẽ được nhắc nhở về chúng. Trong một định nghĩa truy vấn ngược (drill-through), các tham số này có thể được định nghĩa như là một phần của siêu liên kết (giống như trong các yêu cầu HTTP GET). Các giá trị cho các tham số này có thể được rút ra từ ngữ cảnh liên kết.
- Phần sau đây đưa ra ví dụ minh họa cho khái niệm này bằng cách sử dụng hai báo cáo được liên kết. Tạo một bản ghi ngoại lệ bằng Cognos Report Studio (Công cụ tạo báo cáo Cognos) Trong phần này, hãy tạo một dự án có hai trang báo cáo dựa vào OutliersPackage đã triển khai: Trang chính cho thấy một tổng quan về các bản ghi khách hàng được nhóm lại theo nghề với số lượng các ngoại lệ tương ứng cho mỗi nghề. Một trang báo cáo cho thấy các báo cáo sai lệch thực sự với một nghề nhất định. Cả hai báo cáo sẽ được kết hợp sao cho có khả năng truy vấn ngược (drill-through) đến các bản ghi sai lệch so với trang tổng quan chính. Do trang tổng quan có các liên kết đến các trang chi tiết, nên hãy tạo nó trước tiên. Trang các chi tiết ngoại lệ chứa các bản ghi khách hàng được gắn cờ như là các ngoại lệ, thuộc về nghề được lựa chọn trong trang báo cáo chính. Để tạo sự tương tác này, bạn cần phải thêm một tham số cho nghề đó vào bản ghi và sử dụng nó trong một bộ lọc các bản ghi. Bạn cũng cần thêm một điều kiện cho bộ lọc để chỉ trả về các bản ghi có một mục truy vấn Outlier Flag (Cờ truy vấn) bằng "1" (tất cả các bản ghi có mức độ lệch vượt ngưỡng). Để tạo ra trang báo cáo "Outlier Details" (Các thông tin chi tiết), h ãy làm như sau: 1. Tạo một Report (báo cáo) mới trong Cognos Report Studio bằng cách sử dụng OutliersPackage. 2. Thêm một đối tượng danh sách vào báo cáo.
CÓ THỂ BẠN MUỐN DOWNLOAD
-

Tích hợp khai phá dữ liệu trong InfoSphere Warehouse với việc tạo báo cáo Cognos của IBM, Phần 1: Tổng quan về kiến trúc tích hợp InfoSphere Warehouse và Cognos
 29 p |
29 p |  144
|
144
|  33
33
-

Tích hợp khai phá dữ liệu trong InfoSphere Warehouse với việc tạo báo cáo Cognos của IBM
132 p | 102
| 25
-

Bài giảng Khai phá dữ liệu (Data mining): Chương 6 - ĐH Bách khoa TP.HCM
 67 p | 263
| 22
67 p | 263
| 22
-

Tích hợp khai phá dữ liệu trong InfoSphere Warehouse với việc tạo báo cáo Cognos của IBM, Phần 4: Phân đoạn khách hàng với InfoSphere Warehouse và Cognos
37 p | 115
| 19
-

Bài giảng Kho dữ liệu và khai phá dữ liệu: Chương 2 - Tiền xử lý dữ liệu
77 p | 146
| 13
-

Bài giảng Kho dữ liệu và khai phá dữ liệu (2014): Phần 1
79 p | 56
| 12
-

Bài giảng môn học Khai phá dữ liệu: Chương 1
40 p | 127
| 10
-

Tích hợp khai phá dữ liệu trong InfoSphere Warehouse với việc tạo báo cáo Cognos của IBM Phần 3: Gọi khai phá động từ Cognos khi sử dụng một ví dụ phân tích giỏ thị trường
23 p | 113
| 9
-

Bài giảng Khai phá dữ liệu: Chương 2 - TS. Võ Thị Ngọc Châu
58 p | 102
| 9
-

Bài giảng Kho dữ liệu và khai phá dữ liệu (2014): Phần 2
97 p | 38
| 8
-

Tích hợp khai phá dữ liệu trong InfoSphere Warehouse với việc tạo báo cáo Cognos của IBM Phần 4: Phân đoạn khách hàng với InfoSphere Warehouse và Cognos
22 p | 102
| 7
-

Tích hợp khai phá dữ liệu trong InfoSphere Warehouse với việc tạo báo cáo Cognos của IBM Phần 1: Tổng quan về kiến trúc tích hợp InfoSphere Warehouse và Cognos
17 p | 98
| 7
-
Tích hợp khai phá dữ liệu trong InfoSphere Warehouse với việc tạo báo cáo Cognos của IBM Phần 2: Phát hiện sai lệch với InfoSphere Warehouse và Cognos
19 p | 80
| 6
-

Ứng dụng khai phá dữ liệu trong giáo dục: Nghiên cứu trường hợp về dự báo kết quả học tập của sinh viên đại học năm thứ nhất
13 p | 18
| 5
-

Nghiên cứu và ứng dụng luật kết hợp trong khai phá dữ liệu phân tích áp lực của sinh viên Đại học
6 p | 45
| 3
-

Bài giảng Kho dữ liệu và khai phá dữ liệu: Chương 1 - Nguyễn Ngọc Duy
30 p | 33
| 3
-

Bài giảng Kho dữ liệu và khai phá dữ liệu: Chương 2 - Nguyễn Ngọc Duy
125 p | 42
| 3



Chịu trách nhiệm nội dung:
Nguyễn Công Hà - Giám đốc Công ty TNHH TÀI LIỆU TRỰC TUYẾN VI NA
LIÊN HỆ
Địa chỉ: P402, 54A Nơ Trang Long, Phường 14, Q.Bình Thạnh, TP.HCM
Hotline: 093 303 0098
Email: support@tailieu.vn
Giấy phép Mạng Xã Hội số: 670/GP-BTTTT cấp ngày 30/11/2015 Copyright © 2022-2032 TaiLieu.VN. All rights reserved.

