
ĐẠI HỌC QUỐC GIA HÀ NỘI
TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
Nguyễn Văn Sáu
NGHIÊN CỨU SỰ PHÁT TRIỂN CỦA VIRUT CÚM
KHOÁ LUẬN TỐT NGHIỆP ĐẠI HỌC HỆ CHÍNH QUY
Ngành: khoa học máy tính
HÀ NỘI – 2009

1
Mục lục
Mục lục..................................................................................................................... 1
Lời nói đầu................................................................................................................ 3
Chương I. Giới thiệu vềsinh học phân tửvà tin-sinh học ....................................... 4
1. Giới thiệu vềsinh học phân tử.............................................................................. 4
2. Giới thiệu vềtin-sinh học ..................................................................................... 5
2.1. Sắp hàng đa chuỗi ......................................................................................... 5
2.2. Cây tiến hóa ................................................................................................... 7
Chương II. Virut cúm ............................................................................................... 8
1.Sơ lược vềvirut cúm ............................................................................................. 8
2. Các loại virut cúm ................................................................................................ 8
3. Cấu trúc và tính chất............................................................................................ 9
4. Một sốthống kê và sựlây lan của virut cúm...................................................... 10
4.1. Một sốthống kê vềdịch cúm ...................................................................... 10
4.2. Sựlây lan của virut cúm ............................................................................. 12
Chương III. Ngân hàng gene virut cúm.................................................................. 13
1. Giới thiệu tổng quan ........................................................................................... 13
2. Các chức năng đã xây dựng................................................................................ 13
2.1. Quá trình xây dựng ngân hàng gene ............................................................ 14
2.1.1. Quá trình thu thập dữliệu chi tiết cho Việt Nam .................................. 15

Nghiên cứu sự phát triển của virut cúm
2
2.1.2. Xây dựng cơ sở dữliệu.......................................................................... 16
2.2. Tìm kiếm các chuỗi...................................................................................... 21
2.3. Tiện ích tải chuỗi.......................................................................................... 23
2.4. Tiện ích sắp hàng đa chuỗi........................................................................... 23
2.5. Tiện ích xây dựng cây tiến hóa .................................................................... 24
2.6. Bản đồ phân bốcủa virut cúm ..................................................................... 25
2.6. Biểu đồ thống kê vềvirut cúm ..................................................................... 28
Tài liệu tham khảo .................................................................................................. 31
Các hình ảnh tham khảo ......................................................................................... 33
Các bảng tham khảo ............................................................................................... 35

Nghiên cứu sự phát triển của virut cúm
3
Lời nói đầu
Tin-sinh học (Bioinformatics) là một lĩnh vực nghiên cứu đang phát triển rất
mạnh mẽ. Tin-sinh học áp dụng những phương pháp trong tin học để giải quyết
các bài toán trong sinh học phân tử. Với sựphát triển mạnh mẽcủa công nghệsinh
học, một khối lượng lớn dữliệu sinh học phân tử(gene, protein, genome) đã được
thu thập, lưu trữ và chia sẻtại các ngân hàng dữliệu thếgiới như NCBI (National
Center for Biotechnology Information). Tin sinh học hiện đang được ứng dụng
phổbiến trong sinh học phân tử, y-dược học, nông nghiệp, công nghệthực phẩm,
môi trường và kiểm soát bệnh.
Hiện nay, tin-sinh học đang được ứng dụng rộng trong việc phát hiện và
kiểm soát bệnh. Một trong các ứng dụng cụthểlà kiểm soát bệnh cúm, với các
dịch bệnh đang lây lan như cúm gia cầm H5N1, cúm H1N1. Để góp phần vào việc
cung cấp thông tin, cũng như các công cụ phân tích cho việc kiểm soát bệnh cúm ở
Việt Nam, đề tài tập trung vào những mục tiêu chính sau: (1) cung cấp dữliệu về
cúm trên thếgiới và Việt Nam, (2) cung cấp các công cụ phân tích cơ bản như tìm
kiếm, sắp hàng đa chuỗi, xây dựng cây tiến hóa, (3) cung cấp dữliệu vềvirut cúm
chi tiết tới từng tỉnh thành của Việt Nam, (4) cung cấp bản đồ phân tán của virut
cúm trên thếgiới và cho các tỉnh thành ởViệt Nam, (5) cung cấp biểu đồ thống kê
virut cúm cho các vùng của Việt Nam, và trên thếgiới”.
Đề tài hy vọng sẽgóp phần vào việc nghiên cứu và kiểm soát các dịch bệnh
liên quan đến virut cúm ởViệt Nam.
Nghiên cứu sự phát triển của virut cúm
4
Chương I. Giới thiệu về sinh học phân tử và tin-sinh học
1. Giới thiệu về sinh học phân tử
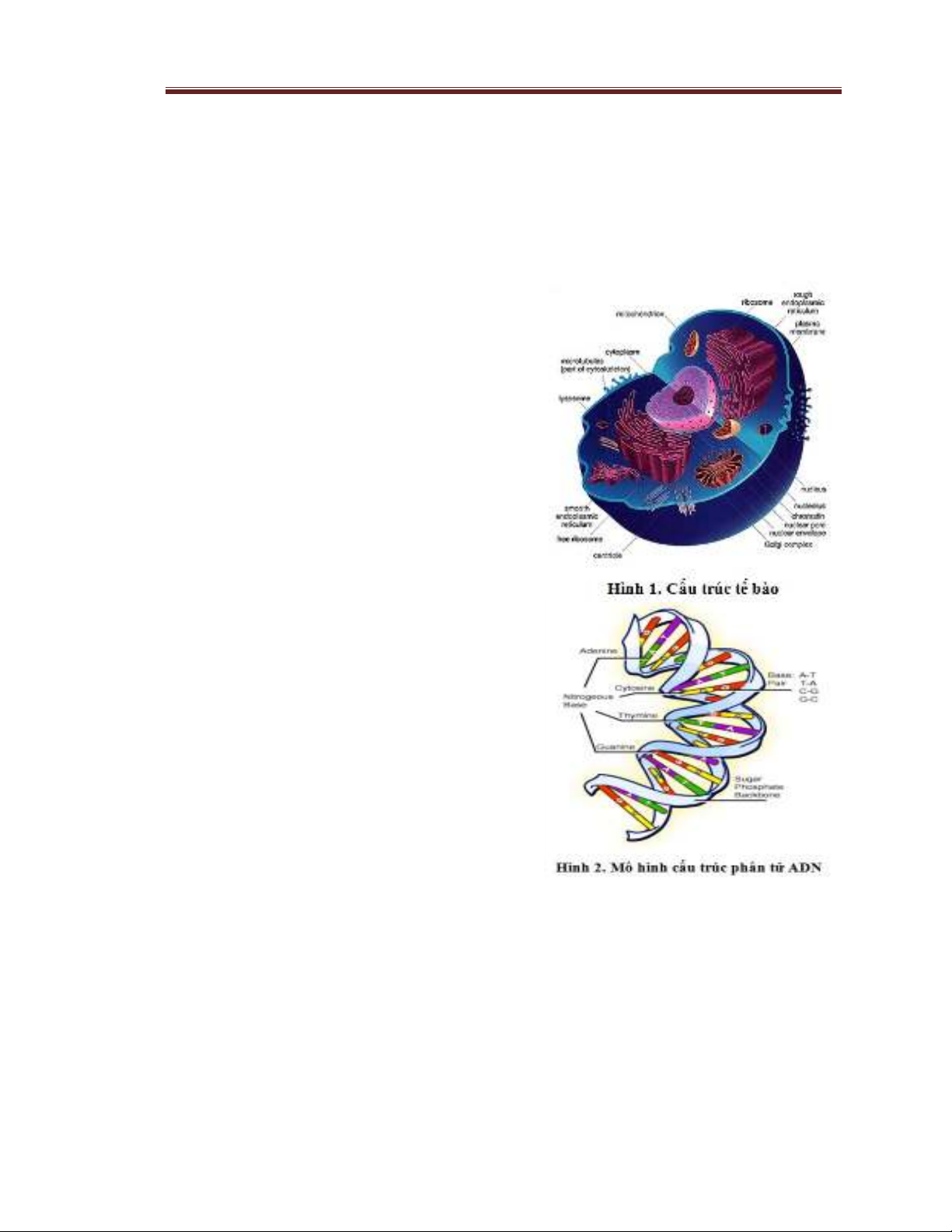
Mọi cơ thể sống đều cấu tạo từcác tếbào.
Tếbào có cấu tạo gồm vỏ và nhân, trong đó
nhân tếbào chứa ADN (hoặc ARN). Hình
1 mô tảcấu tạo của tếbào.
ADN (acid deoxyribo nucleic) mang
thông tin di truyền, được cấu tạo từ4 thành
phầncơ bản (gọi là các nucleotide –
Brown, 2000) Adenine (A), Cytosine (C),
Guanine (G), Thymine (T) như hình 2.
Trong các chuỗi ADN, một số đoạn được
gọi là gene mang thông tin di truyền của các
loài sinh vật. Các nucleotide trong gene sẽ
kết hợp với nhau để tổng hợp ra protein. Cụ
thểlà, một bộba nucleotide liên tiếp sẽtạo
ra 1 axit amin. Có 20 loại axit amin khác
nhau (Brown, 2002) là Phe (Phenylalanine),
Leu (Leucine), Ser (Serine), Tyr (Tyrosine),
Cys (Cysteine), Trp (Tryptophan), Pro (Pro-
line), His (Histidine), Gln (Glutamine), Arg
(Arginine), Ile (Isoleucine), Thr (Threonine), Asn (Asparagine), Lys (Lysine), Val
(Valine), Ala (Alanine), Asp (Aspartic Acid), Glu (Glutamic Acid), Gly (Glycine).
Hình 3 mô tảsựkết hợp của các ADN để tạo ra các axit amin. Từcác axit amin
này tạo nên các protein bằng cách liên kết với nhau. Sựsắp xếp khác nhau và số
lượng khác nhau của các axit amin tạo thành vô sốcác protein khác nhau.

























