
1
Ứng dụng xử lý ngôn ngữ tự nhiên trong hệ tìm kiếm thông tin trên
văn bản tiếng Việt
Đồng Thị Bích Thủy#, Hồ Bảo Quốc#*
#Khoa Công Nghệ Thông Tin - Đại học khoa học tự nhiên TP. HCM
227 Nguyễn Văn Cừ - Q5 – TP.HCM
*Laboratoire CLIP – IMAG, Grenoble France
thuy@hcmuns.edu.vn, Ho-Bao.Quoc@imag.fr
0. Dẫn nhập
Trong các hệ thống tìm kiếm thông tin văn bản (Text Information Retrieval System), tiến trình
quan trọng nhất là tiến trình phân tích nội dung văn bản để xác định tập chỉ mục biểu diễn tốt
nhất nội dung của văn bản (tiến trình lập chỉ mục - indexing). Để có thể phân tích và rút trích
được các chỉ mục (index term / term) tốt người ta thường ứng dụng các kết quả của lĩnh vực xử lý
ngôn ngữ tự nhiên vào tiến trình này.
Chỉ mục có thể là từ (word) hay là một cấu trúc phức tạp hơn như cụm danh từ (noun phrase),
khái niệm (concept)... Vấn đề xác định chỉ mục cho văn bản tiếng Việt phức tạp hơn đối với ngôn
ngữ châu Âu do việc xác định giới hạn của một từ (word segmentation) trong tiếng Việt không
đơn giản là chỉ dựa vào các khoảng trắng giữa chúng. Hơn nữa ngữ pháp tiếng Việt vẫn còn
nhiều vấn đề tranh luận giữa các nhà ngôn ngữ học nên cũng còn nhiều khó khăn trong việc tự
động hóa việc phân tích tiếng Việt.
Trong báo cáo này chúng tôi trình bày việc ứng dụng xử lý ngôn ngữ tự nhiên vào hệ thống
tìm kiến thông tin nói chung, tiếp theo chúng tôi trình bày một số đặc trưng của tiếng Việt dưới
góc nhìn của lĩnh vực tìm kiếm thông tin. Cuối cùng chúng tôi trình bày một số kết quả mà chúng
tôi đã đạt được trong việc xác định chỉ mục cho văn bản tiếng Việt.
Bài báo chia làm bốn phần, phần I giới thiệu tổng quát về việc ứng dụng xử lý ngôn ngữ tự
nhiên vào lĩnh vực tìm kiếm thông tin. Phần II chúng tôi trình bày một số đặc trưng của tiếng
Việt dưới góc nhìn của lĩnh vực tìm kiếm thông tin. Phần III một số kêt quả mà chúng tôi đã đạt
được trong việc lập chỉ mục cho văn bản tiếng Việt dựa trên uni-gram, bi-gram, cụm danh từ và
cuối cùng là phần kết luận.
2
I. Ứng dụng xử lý ngôn ngữ tự nhiên vào tìm kiếm thông tin
1.1 Giới thiệu tổng quan
Tìm kiếm thông tin (Information retrieval) là lĩnh vực nghiên cứu nhằm tìm ra các giải pháp
giúp người sử dụng có thể tìm thấy các thông tin mình cần trong một khối lượng lớn dữ liệu.
Nhiệm vụ của một hệ thống tìm kiếm thông tin tương tự như nhiệm vụ tổ chức phân loại tài liệu
và phục vụ việc tra cứu của một thư viện. Một hệ thống tìm kiếm thông tin có hai chức năng
chính : lập chỉ mục (indexing) và tra cứu (interrogation). Lập chỉ mục là giai đoạn phân tích tài
liệu (document) để xác định các chỉ mục (term / index term) biểu diễn nội dung của tài liệu. Việc
lập chỉ mục có thể dựa vào một cấu trúc phân lớp có sẵn (control vocabulary) như cách làm của
các nhân viên thư viện, phân loại tài liệu theo một bộ phân loại cho trước. Các chỉ mục trong
cách làm này là tồn tại trước và độc lập với tài liệu. Cách thứ hai để lập chỉ mục là rút trích các
chỉ mục từ chính nội dung của tài liệu (free text). Trong bài này chúng tôi chỉ đề cập đến cách thứ
hai này. Cuối giai đoạn lập chỉ mục nội dung của các tài liệu có trong kho tài liệu (corpus) được
biểu diễn bên trong bằng tập các chỉ mục.
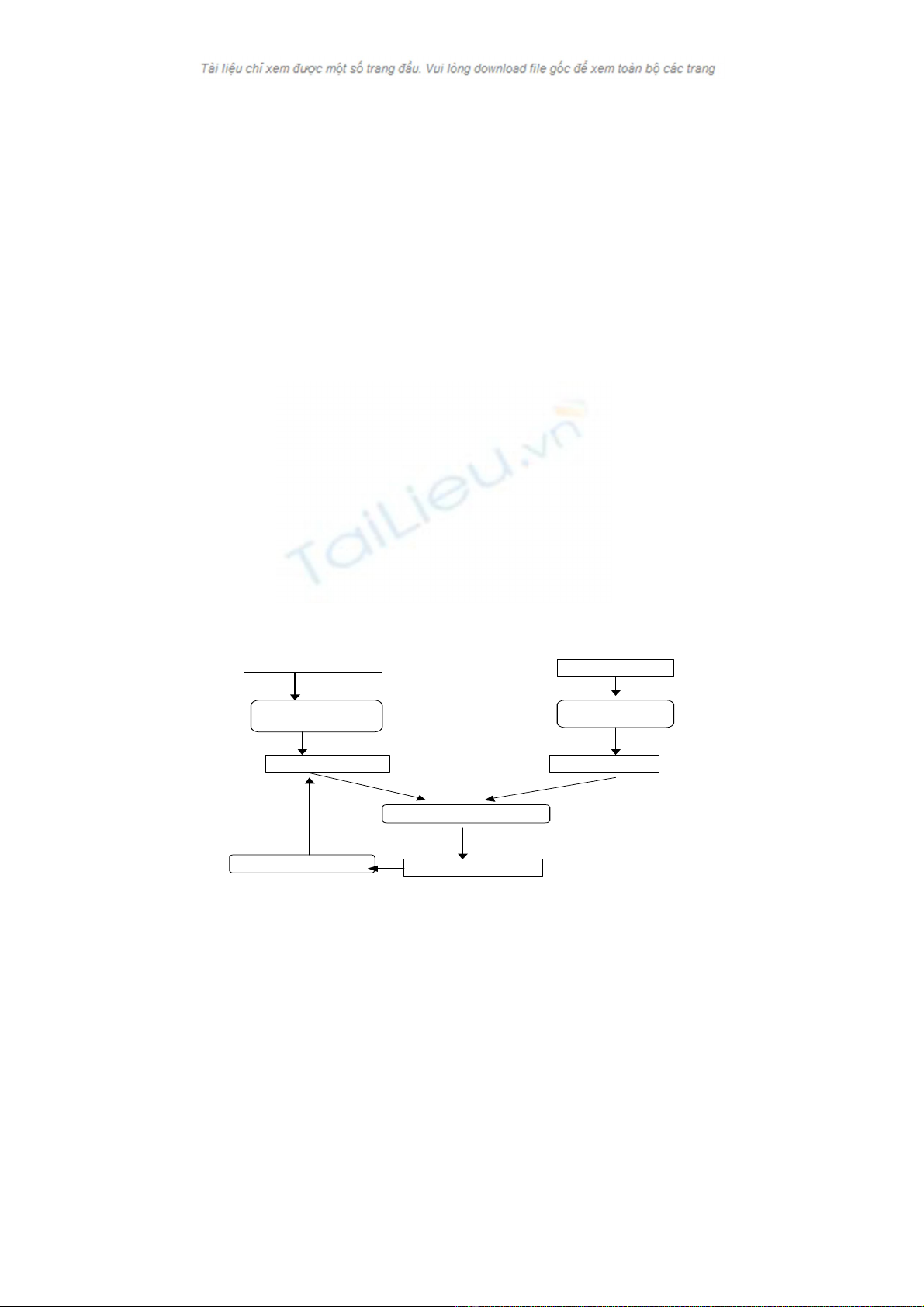
Trong giai đoạn tra cứu, nhu cầu thông tin của người sử dụng được đưa vào hệ thống dưới
dạng một câu hỏi (query) bằng ngôn ngữ tự nhiên hay một dạng thức qui ước nào đó, cũng sẽ
được phân tích và biểu diễn thành một dạng biểu diễn trong. Hệ thống sẽ sử dụng một hàm so
khớp (matching function) để so khớp biểu diễn của câu hỏi với các biểu diễn của các tài liệu để
tìm ra các tài liệu có liên quan (relevance). Một hệ thống tìm kiếm thông tin có thể được biểu
diễn như trong hình vẽ sau
Để đánh giá hiệu năng của một hệ thống tìm kiếm thông tin người ta dựa vào hai độ đo chính
là độ chính xác (presicion) và độ bao phủ (recall). Giả sử với một câu hỏi cho trước q, P là tập
các tài liệu mà hệ thống tìm được, R là tập các tài liệu thật sự liên quan đến câu hỏi q. Độ chính
xác là tỉ số giữa số tài liệu liên quan đến câu hỏi được tìm thầy trên toàn số tài liệu được tìm thấy
((P ∩ R) /P). Độ bao phủ là tỉ số giữa số tài liệu liên quan đến câu hỏi được tìm thấy trên tổng số
các tài liệu liên quan ((P∩R)/R).
Mặc dù lĩnh vực tìm kiếm thông tin đã được nghiên cứu từ mấy chục năm nay nhưng những
kỹ thuật mới vẫn chưa được áp dụng vào các hệ thống thương mại vì nhiều lý do khác nhau. Đa
số các hệ thống tìm kiếm thông tin văn bản vẫn dựa trên các kỹ thuật đơn giản dẫn đến các kết
quả chưa đáp ứng được mong đợi của người sử dụng. Như chúng ta vẫn thường gặp khi sử dụng
Nhu cầu thông tin Tài liệu
biểu diễnlập chỉ mục
Câu hỏi tập chỉ mục
So khớp
Tài liệu liên quan
Thay đổi câu hỏi

3
các công cụ tìm kiếm (search engine) trên Internet. Phần lớn các hệ thống tìm kiếm đều vẫn đang
dựa trên giả định nếu một câu hỏi và một tài liệu có chứa một số từ (từ khoá) chung, thì tài liệu là
liên quan đến câu hỏi, và dĩ nhiên là nếu số từ chung càng nhiều thì độ liên quan càng được cho
là cao [1]. Để đánh giá độ liên quan giữa tài liệu và câu hỏi tốt hơn là chỉ dựa vào số lượng từ
chung, người ta đánh trọng số (weight) cho các từ để biểu diễn mức độ quan trọng của từ trong
tài liệu. Với giả định như vậy hệ thống không thể cho một kết quả chính xác do chúng ta xem
như đã biểu diễn tài liệu và câu hỏi dưới dạng các tập hợp từ khoá độc lập nhau (được gọi là túi
các từ khoá) và việc so khớp là tiến hành so khớp cái ‘túi’ từ khóa này.
Cách biểu diễn đơn giản này không thể cho kết quả cao vì nếu nhìn dưới góc nhìn của ngôn
ngữ học nó đã không xử lý các biến thể về mặt ngôn ngữ học (linguistic variation) của các từ như
biến thể về hình thái học (morphological variation), biến thể về từ vựng học (lexical variation),
biến thể về ngữ nghĩa học (semantical variation) và biến thể về cú pháp học (syntax variation).
1.2 Các biến thể ngôn ngữ học
Biến thể về hình thái học là các dạng khác nhau về mặt cấu trúc (nôm na là hình dáng) của
một từ như vẫn hay thấy trong các ngôn ngữ châu Âu. Ví dụ trong tiếng Anh các từ computer,
computerize, computers là các biến thể về hình thái học của từ computer. Hệ thống sẽ cho kết quả
không chính xác nếu đối xử với các biến thể này như các từ độc lập nhau.
Biến thể về từ vựng học là các từ khác nhau mang cùng một nghĩa. Ví dụ như trong tiếng Anh
các từ: car, auto. Hệ thống sẽ không trả về các tài liệu có chứa từ auto mà không chứa từ car khi
câu hỏi chỉ chứa từ car.
Biến thể về ngữ nghĩa học là vấn đề một từ đa nghĩa tùy vào ngữ cảnh. Vi dụ như khi chúng ta
tìm từ ‘bands’ có thể chúng ta sẽ nhận được các tài liệu nói về ‘radio frequency bands’
Biến thể về cú pháp học là các các kết hợp khác nhau về mặt cú pháp của cùng một nhóm từ
sẽ mang các ý nghĩa khác nhau. Do đó nếu hệ thống không xử lý cấu trúc ngữ pháp của nhóm từ
sẽ dẫn đến việc giảm độ chính xác. Ví dụ một tài liệu chứa câu ‘near to the river, air pollution is a
major problem’ thì không liên quan gì đến ‘river pollution’ cả mặc dù cả hai từ đều có xuất hiện
trong tài liệu.
Do vậy để nâng cao hiệu quả của các hệ tìm kiếm thông tin, người ta phải có các giải thuật để
xử lý các biến thiên ngôn ngữ học như đã nêu
1.3 Các thuật toán xử lý ngôn ngữ tự nhiên
Đối với các biến thiên về hình thái học người ta có hai cách để xử lý: cách thứ nhất là mở rộng
câu hỏi (query expansion) bằng cách thêm vào câu hỏi tất cả các biến thể hình thái học của tất cả
các từ có trong câu hỏi, cách thứ hai là chuẩn hoá các biến thể hình thái học (stemming) của một
từ về một chuẩn chung (stem). Ví dụ như các từ computer, computed, computes, computerize sẽ
được chuẩn hoá thành một stem là compute. Hai thuật toán stemming được biết đến nhiều cho
tiếng Anh là Lovins và Porter.
Để xử lý các biến thể về từ vựng học người ta hoặc là mở rộng câu hỏi bằng cách thêm vào
câu hỏi tất cả các từ đồng nghĩa có thể có của tất cả các từ trong câu hỏi hoặc là xử lý ở giai đoạn
so khớp bằng cách đưa ra các độ đo khoảng cách của các khái niệm (conceptual distance
measures). Đối với cách thứ nhất chúng ta cần có một từ điển đồng nghĩa, đối với cách thứ hai
chúng ta phải xây dựng một tự điển từ vựng (thesaurus) trong đó có định nghĩa khoảng cách giữa
các từ như mạng ngữ nghĩa WORDNET.

4
Biến thể về ngữ nghĩa thường kết hợp chặt chẽ với biến thể về từ vựng học. Để xử lý các biến
thể này chúng ta cần một công đoạn xử lý sự đa nghĩa của từ (word sense disambiguiation), hiệu
năng của hệ thống tìm kiếm sẽ phụ thuộc vào kết quả của giai đoạn xử lý này.
Các kỹ thuật xử lý các biến thể về cú pháp học hay nói cụ thể hơn là xử lý cấu trúc của một
cụm từ (phrase) có thể được chia làm hai loại: kỹ thuật lập chỉ mục dựa vào các cụm từ (phase
based indexing) và kỹ thuật lập chỉ mục là các cấu trúc cây phân tích được từ các mệnh đề. Các
kỹ thuật lập chỉ mục dựa trên cụm từ nhằm tăng độ chính xác của hệ thống. Với giả định rằng khi
dùng các cụm từ như các chỉ mục thay cho các từ đơn thì độ chính xác sẽ tăng do cụm từ biểu
diễn chính xác hơn nội dung của tài liệu. Các hệ thống tìm kiếm dựa trên chỉ mục là các cụm từ
ngày càng thu hút nhiều nhóm nghiên cứu và vấn đề làm thế nào để rút trích được các cụm từ một
cách tự động từ tài liệu trở thành vấn đề chính trong các hệ này. Các giải pháp rút trích cụm từ
thường dựa vào hai cách tiếp cận: tiếp cận dùng thông tin thống kê tần suất đồng xuất hiện (co-
occurrence) hay cách tiếp cận dựa vào tri thức về ngôn ngữ học. Cách tiếp cận thứ hai đòi hỏi
phải áp dụng nhiều kỹ thuật của lĩnh vực xử lý ngôn ngữ tự nhiên.
Kỹ thuật lập chỉ mục cấu trúc dựa vào các cấu trúc cây có được từ việc phân tích các mệnh đề
trong câu của tài liệu và quá trình so khớp là so khớp các cấu trúc của câu hỏi với các cấu trúc
của tài liệu. Cách tiếp cận này không thu hút nhiều nhóm nghiên cứu do độ phức tạp của việc
phân tích mệnh đề để xây dựng cách cấu trúc cao nhưng lại không tăng được hiệu năng của hệ
thống tìm kiếm.
1.4 Hệ thống tra cứu thông tin ứng dụng xữ lý ngôn ngữ tự nhiên
Theo [1], quá trình lập chỉ mục của một hệ thống tìm kiếm thông tin có ứng dụng các kỹ thuật
xử lý ngôn ngữ tự nhiên phải bao gồm các chức năng như sau:
1. Xác định từ (tokenization/ word segmentation)
2. Xác định từ loại cho từ (Part-of-speech tagging)
3. Chuẩn hoá các biến thể về hình thái học của từ
4. Xác định các từ ghép
5. Chuẩn hoá các biến thể về từ vựng học và ngữ nghĩa học
6. Phân tích cú pháp
7. Chuẩn hoá các biến thể về cú pháp học
8. Đánh trọng số cho các biểu thức chỉ mục
Bước xác định từ thực hiện việc xác định các câu trong tài liệu và xác định các từ trong câu.
Đối với các ngôn ngữ châu Âu bước này có thể được cài đặt dựa vào các luật về viết hoa, khoảng
trắng và các ký tự phân cách khác. Đối với tiếng Việt đây là một bước khá phức tạp bởi vì các từ
tiếng Việt không thể xác định chỉ dựa theo cách này.
Sau khi đă xác định được các từ, hệ thống tiến hành gán từ loại (category) cho từng từ phụ
thuộc vào ngữ cảnh của từ. Đây cũng là một công đoạn rất phức tạp do một từ có thể mang nhiều
từ loại khác nhau tùy thuộc vào ngữ cảnh xuất hiện của từ. Việc xác định từ loại cho từ nhằm
phục vụ cho giai đoạn tiếp theo của tiến trình đó là xác định từ ghép, các cụm danh từ có trong
câu.
Bước tiếp theo của hệ thống là xác định các từ ghép (compound noun) ví dụ như từ ‘hot dog’
để xử lý chúng như một đơn vị duy nhất thay vì xử lý riêng rẽ các từ hot và dog trong trường hợp
này. Việc xác định các từ ghép thường dùng phương pháp thống kê tần suất đồng xuất hiện của

5
các từ trong tài liệu hoặc dùng các mẫu (patern) tổ hợp các từ loại, ví dụ như danh từ - tính từ,
danh từ - danh từ …
Tiếp theo là quá trình chuẩn hoá các biến thể và từ vựng học và ngữ nghĩa để xây dựng phân
nhóm các chỉ mục theo các nhóm ngữ nghĩa (semantical clustering)
Phân tích cú pháp là giai đoạn nhằm xác định các liên hệ về mặt cú pháp giữa các từ trong
cụm từ. Khi chúng ta đã xác định được các cụm từ và các liên hệ cú pháp giữa các từ trong cụm
từ, chúng ta tiến hành chuẩn hóa các cụm từ về một chuẩn chung và cuối cùng tiến hành đánh
trọng số cho các cụm từ chỉ mục.
Phần trên chúng tôi đã trình bày một kiến trúc của một hệ thống tìm kiếm thông tin có ứng
dụng các xử lý ngôn ngữ tự nhiên. Tuy nhiên ví các bước xử lý ngôn ngữ tự nhiên là rất phức tạp
với thời gian xử lý nhiều nên việc triển khai các hệ thống như vậy trong thực tế vẫn còn nhiều
hạn chế.
II. Một số đặc trưng của tiếng Việt
2.1. Từ tiếng Việt
Một vấn đề khó khăn đầu tiên trong xử lý tự động tiếng Việt là việc định nghĩa từ trong tiếng
Việt vẫn còn nhiều tranh luận. Để thuận tiện cho việc trình bày về sau chúng tôi theo quan điểm
của Đinh Điền [2] sau: một câu tiếng Việt bao gồm nhiều từ, mỗi từ bao gồm một hay nhiều
‘tiếng’, mỗi ‘tiếng’ là mỗi chuỗi ký tự liền nhau phân biệt với các tiếng khác bằng một hay nhiều
khoảng trắng. Ví dụ :
từ ‘học’ là một từ gồm một tiếng
từ ‘học sinh’ là một từ gồm hai tiếng
cụm từ ‘khoa học tự nhiên’ gồm 2 từ hay 4 tiếng
Chúng tôi đã sử dụng phương pháp học dựa vào các luật biến đổi (transformation based
learning) [3] để thực hiện công việc này và đạt được độ chính xác khoảng 80-85%.
Trong các hệ thống tìm kiếm thông tin văn bản trên các tiếng Châu âu, người ta có thể đơn
giản lấy xác định các từ nhờ vào các khoảng trắng phân cách từ và chọn các từ đặc trưng cho nội
dung văn bản (dựa vào tần suất xuất hiện của từ) làm chỉ mục mà hiệu quả tìm kiếm vẫn chấp
nhận được. Đối với tiếng Việt chúng ta không thể làm tương tự bởi nếu chúng ta xác định từ chỉ
dựa các khoảng trắng phân cách thì chúng ta có thể chỉ nhận được các ‘tiếng’ vô nghĩa và do đó
độ chính xác của hệ thống sẽ rất thấp. Theo các nhà ngôn ngữ học thì tiếng Việt có đến 80% là
các từ 2 ‘tiếng’ [6]. Chúng tôi sẽ trình bày các kết quả thực nghiệm chứng minh điều này ở phần
sau.
Một đặc điểm của tiếng Việt là từ tiếng Việt không có biến thể về hình thái học do đó công
đoạn chuẩn hóa về hình thái học là không hiệu quả đối với tiếng Việt. Dĩ nhiên tiếng Việt cũng
có một số hình thức biến thể về hình thái học như trường hợp thêm tiếng ‘sự’ trước một động từ
để biến nó thành danh từ tương đương ví dụ như: động từ ‘lựa chọn’ và danh từ ‘sự lựa chọn’ hay
việc thêm tiếng ‘hóa’ sau một danh từ để biến nó thành động từ tương đương như : danh từ ‘tin
học’ và động từ ‘tin học hóa’
2.2 Từ loại








![Từ điển: [Định nghĩa, Phân loại, Cách sử dụng] đầy đủ nhất](https://cdn.tailieu.vn/images/document/thumbnail/2010/20100726/kisiheo/135x160/dictionary_6403.jpg)

















%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23fff;%20}%20.st1%20{%20fill:%20%237800fa;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st1'%20d='M117.78,12.18H43.11c2.9,3.47,4.65,7.94,4.65,12.82,0,5.6-2.3,10.66-6.01,14.29h76.02l7.22-13.56-7.22-13.56Z'/%3e%3cg%3e%3cpath%20class='st0'%20d='M53.58,26.17h-.59v-1.46h.59v-4.96h2.83c1.78,0,2.67.94,2.67,2.82v5.76c0,1.87-.89,2.81-2.67,2.81h-2.83v-4.96ZM55.36,21.37v3.34h1.1v1.46h-1.1v3.34h1.01c.61,0,.91-.37.91-1.1v-5.93c0-.74-.3-1.1-.91-1.1h-1.01Z'/%3e%3cpath%20class='st0'%20d='M65.99,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM65.28,18.04c-.25.46-.51.77-.75.94-.21.15-.47.22-.79.22-.26,0-.57-.07-.92-.22l-.38-.15c-.14-.05-.26-.07-.37-.07-.3,0-.53.18-.71.54l-.91-.68c.25-.46.51-.77.75-.94.21-.14.48-.21.79-.21.26,0,.57.07.92.21l.38.15c.14.05.26.07.37.07.3,0,.53-.18.71-.54l.91.68ZM61.91,27.52h1.73l-.87-5.76-.87,5.76Z'/%3e%3cpath%20class='st0'%20d='M74.53,26.89v1.52c0,1.91-.89,2.86-2.67,2.86s-2.67-.95-2.67-2.86v-5.93c0-1.91.89-2.86,2.67-2.86s2.67.95,2.67,2.86v1.11h-1.69v-1.22c0-.75-.31-1.12-.93-1.12s-.93.37-.93,1.12v6.15c0,.74.31,1.11.93,1.11s.93-.37.93-1.11v-1.63h1.69Z'/%3e%3cpath%20class='st0'%20d='M81.4,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM75.9,19.2l1.52-1.91h1.71l1.51,1.91h-1.61l-.76-.95-.75.95h-1.61ZM77.32,27.52h1.73l-.87-5.76-.87,5.76ZM83.1,15.99l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M84.86,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM84.01,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M93.51,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM92.66,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M98.8,31.14h-1.79v-11.39h1.79v4.88h2.03v-4.88h1.83v11.39h-1.83v-4.88h-2.03v4.88Z'/%3e%3cpath%20class='st0'%20d='M105.36,24.55h2.46v1.62h-2.46v3.34h3.09v1.63h-4.88v-11.39h4.88v1.63h-3.09v3.18ZM108.17,17.29l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M112.2,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM111.35,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3c/g%3e%3ccircle%20class='st1'%20cx='25'%20cy='25'%20r='20'/%3e%3cpath%20class='st0'%20d='M32.78,19.27c2.92,0,4.43,2.55,5.28,5.33l.71,2.17c.14.38-.33.75-.71.75h-5.61c.19-.33.24-.71.09-1.08l-.75-2.45c-.43-1.32-.99-2.64-1.79-3.77.75-.57,1.65-.94,2.78-.94h0ZM25,18.38c3.25,0,4.9,2.78,5.89,5.89l.76,2.45c.14.42-.33.8-.8.8h-11.69c-.42,0-.94-.38-.8-.8l.75-2.45c.99-3.11,2.64-5.89,5.89-5.89h0ZM25,11.35c1.74,0,3.11,1.37,3.11,3.11s-1.37,3.11-3.11,3.11-3.11-1.41-3.11-3.11,1.41-3.11,3.11-3.11h0ZM17.27,19.27c1.08,0,1.98.38,2.73.94-.8,1.13-1.37,2.45-1.74,3.77l-.8,2.45c-.14.38-.05.75.09,1.08h-5.56c-.42,0-.9-.38-.75-.75l.71-2.17c.9-2.78,2.41-5.33,5.33-5.33h0ZM17.27,12.91c1.51,0,2.78,1.27,2.78,2.83s-1.27,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM32.78,12.91c1.56,0,2.78,1.27,2.78,2.83s-1.23,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM27.07,28.56v.09c0,.57-.24,1.08-.61,1.46h0v.05c-.38.33-.9.57-1.46.57s-1.08-.24-1.46-.61h0c-.38-.38-.61-.9-.61-1.46v-.09h1.41v.09c0,.19.05.38.19.47v.05c.09.09.28.19.47.19s.38-.09.47-.19v-.05c.14-.09.24-.28.24-.47t-.05-.09h1.41ZM30.99,28.56v.09c0,1.65-.66,3.16-1.74,4.24-1.08,1.08-2.59,1.79-4.24,1.79s-3.16-.71-4.24-1.79l-.05-.05c-1.04-1.08-1.7-2.55-1.7-4.2v-.09h1.41v.09c0,1.27.47,2.4,1.27,3.25h.05c.85.85,1.98,1.37,3.25,1.37s2.4-.52,3.25-1.37c.85-.8,1.37-1.98,1.37-3.25v-.09h1.37ZM34.99,28.56v.09c0,2.78-1.13,5.28-2.92,7.07-1.79,1.79-4.29,2.92-7.07,2.92s-5.23-1.13-7.07-2.92c-1.79-1.79-2.92-4.29-2.92-7.07v-.09h1.41v.09c0,2.4.94,4.53,2.5,6.08,1.56,1.56,3.72,2.5,6.08,2.5s4.52-.94,6.08-2.5c1.56-1.56,2.5-3.68,2.5-6.08v-.09h1.41Z'/%3e%3c/svg%3e)