CHƯƠNG I
GIỚI THIỆU VỀ SỰ BIÊN DỊCH
Nội dung chính:
Để máy tính có thể hiểu và thực thi một chương trình được viết bằng ngôn ngữ cấp
cao, ta cần phải có một trình biên dịch thực hiện việc chuyển đổi chương trình đó sang
chương trình ở dạng ngôn ngữ đích. Chương này trình bày một cách tổng quan về cấu
trúc của một trình biên dịch và mối liên hệ giữa nó với các thành phần khác - “họ
hàng” của nó - như bộ tiền xử lý, bộ tải và soạn thảo liên kết,v.v. Cấu trúc của trình
biên dịch được mô tả trong chương là một cấu trúc mức quan niệm bao gồm các giai
đoạn: Phân tích từ vựng, Phân tích cú pháp, Phân tích ngữ nghĩa, Sinh mã trung gian,
Tối ưu mã và Sinh mã đích.
Mục tiêu cần đạt:
Sau khi học xong chương này, sinh viên phải nắm được một cách tổng quan về nhiệm
vụ của các thành phần của một trình biên dịch, mối liên hệ giữa các thành phần đó và
môi trường nơi trình biên dịch thực hiện công việc của nó.
Tài liệu tham khảo:
[1] Trình Biên Dịch - Phan Thị Tươi (Trường Ðại học kỹ thuật Tp.HCM) - NXB
Giáo dục, 1998.
[2] Compilers : Principles, Technique and Tools - Alfred V.Aho, Jeffrey
D.Ullman - Addison - Wesley Publishing Company, 1986.
[3] Compiler Design – Reinhard Wilhelm, Dieter Maurer - Addison - Wesley
Publishing Company, 1996.
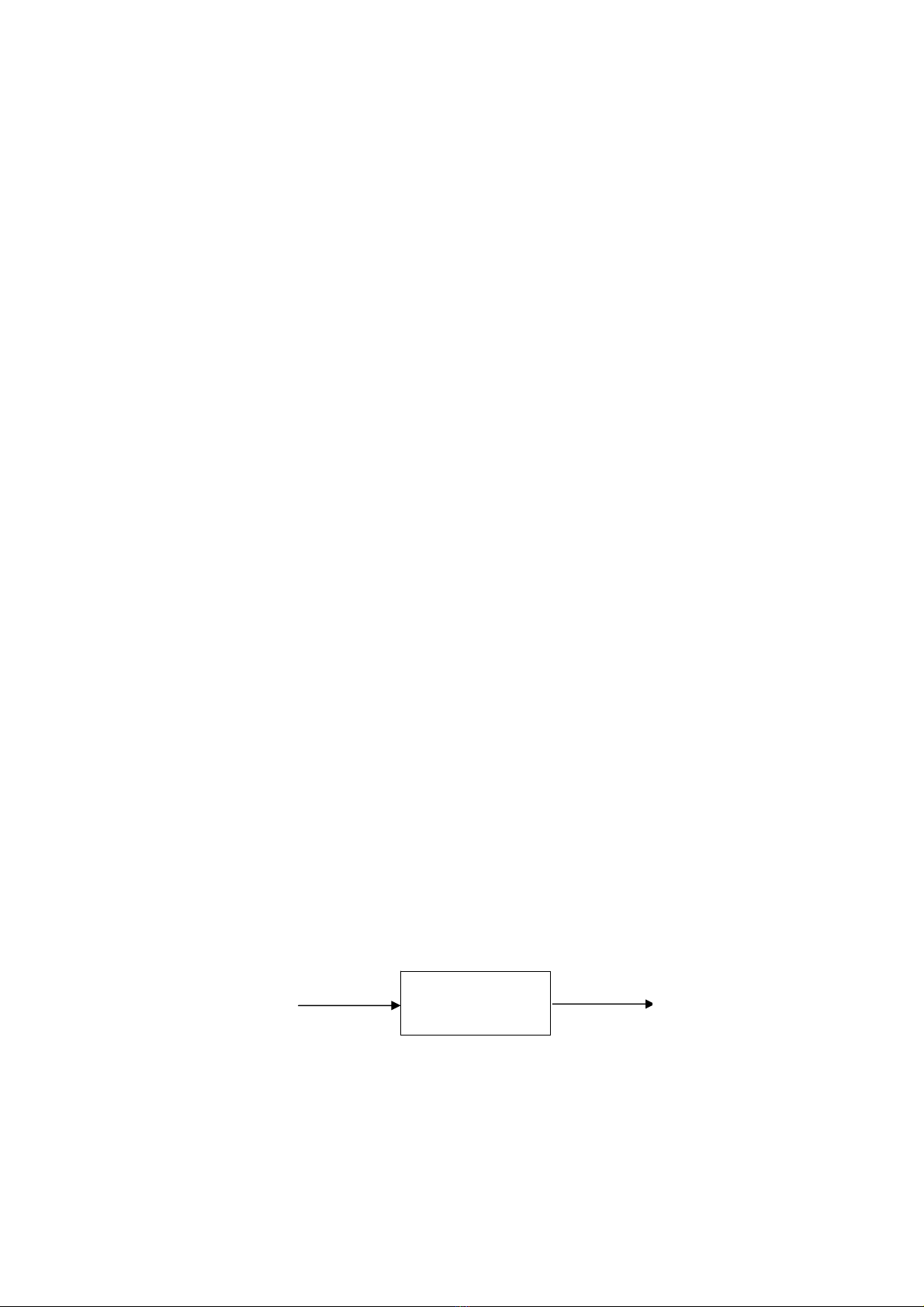
I. TRÌNH BIÊN DỊCH
Nói một cách đơn giản, trình biên dịch là một chương trình làm nhiệm vụ đọc một
chương trình được viết bằng một ngôn ngữ - ngôn ngữ nguồn (source language) - rồi
dịch nó thành một chương trình tương đương ở một ngôn ngữ khác - ngôn ngữ đích
(target languague). Một phần quan trọng trong quá trình dịch là ghi nhận lại các lỗi có
trong chương trình nguồn để thông báo lại cho người viết chương trình.
Trình biên
dịch
Chương trình
đích
Chương trình
nguồn
Hình 1.1 - Một trình biên dịch
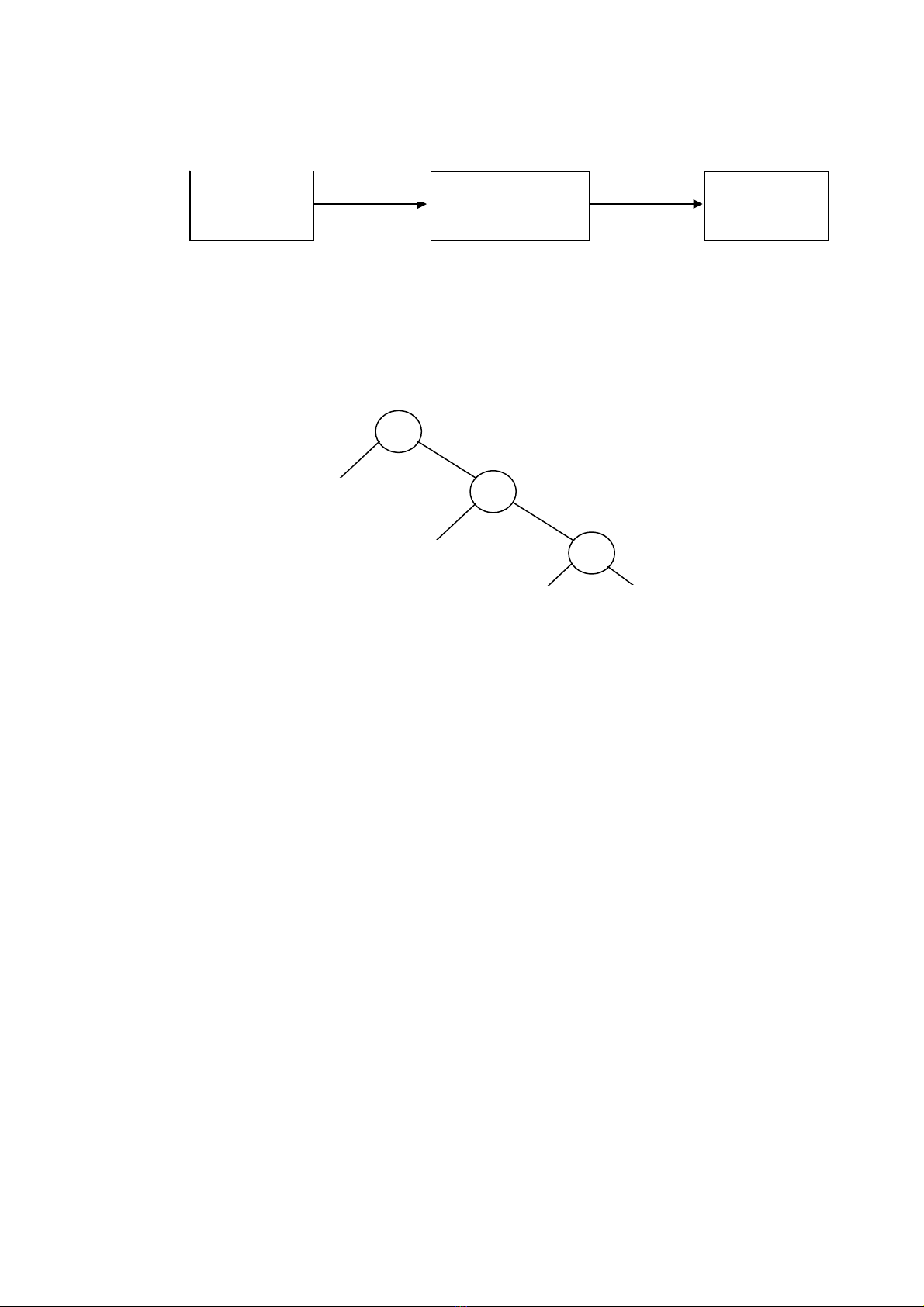
1. Mô hình phân tích - tổng hợp của một trình biên dịch
Chương trình dịch thường bao gồm hai quá trình : phân tích và tổng hợp
- Phân tích → đặc tả trung gian
- Tổng hợp → chương trình đích
1
Chương
trình nguồn
Phán
têch
Đặc tả trung
gian
Phán
têch
Tổng hợp
Phân tích Chương
trình đích
Hình 1.2 - Mô hình phân tích - tổng hợp
Trong quá trình phân tích chương trình nguồn sẽ được phân rã thành một cấu trúc
phân cấp, thường là dạng cây - cây cú pháp (syntax tree) mà trong đó có mỗi nút là
một toán tử và các nhánh con là các toán hạng.
Ví dụ 1.1: Cây cú pháp cho câu lệnh gán position := initial + rate * 60
:=
position
+
initial *
rate 60
2. Môi trường của trình biên dịch
Ngoài trình biên dịch, chúng ta có thể cần dùng nhiều chương trình khác nữa để
tạo ra một chương trình đích có thể thực thi được (executable). Các chương trình đó
gồm: Bộ tiền xử lý, Trình dịch hợp ngữ, Bộ tải và soạn thảo liên kết.
Một chương trình nguồn có thể được phân thành các module và được lưu trong các
tập tin riêng rẻ. Công việc tập hợp lại các tập tin này thường được giao cho một
chương trình riêng biệt gọi là bộ tiền xử lý (preprocessor). Bộ tiền xử lý có thể "bung"
các ký hiệu tắt được gọi là các macro thành các câu lệnh của ngôn ngữ nguồn.
Ngoài ra, chương trình đích được tạo ra bởi trình biên dịch có thể cần phải được
xử lý thêm trước khi chúng có thể chạy được. Thông thường, trình biên dịch chỉ tạo ra
mã lệnh hợp ngữ (assembly code) để trình dịch hợp ngữ (assembler) dịch thành dạng
mã máy rồi được liên kết với một số thủ tục trong thư viện hệ thống thành các mã thực
thi được trên máy.
Hình sau trình bày một quá trình biên dịch điển hình :
2
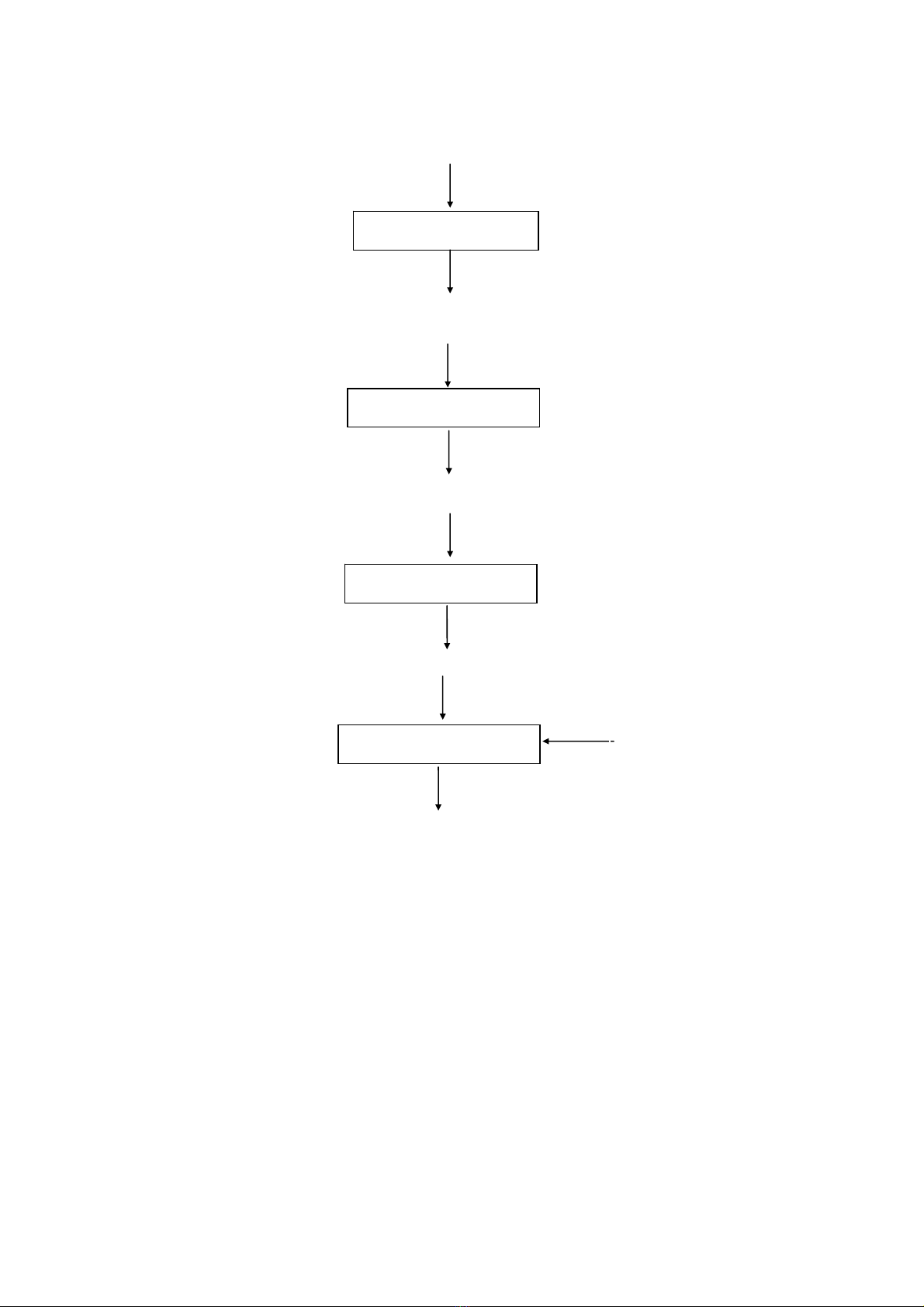
Hình 1.3 - Một trình xử lý ngôn ngữ điển hình
Chương trình nguồn khung
Chương trình nguồn
Bộ tiền xử lý
Trình biên dịch
Trình dịch hợp ngữ
Chương trình đích hợp ngữ
Mã máy khả tái định vị
Trình tải / Liên kết
Mã máy tuyệt đối
Thư viện,
Tập tin đối tượng
khả tái định vị
II. SỰ PHÂN TÍCH CHƯƠNG TRÌNH NGUỒN
Phần này giới thiệu về các quá trình phân tích và cách dùng nó thông qua một số
ngôn ngữ định dạng văn bản.
1. Phân tích từ vựng (Lexical Analysis)
Trong một trình biên dịch, giai đọan phân tích từ vựng sẽ đọc chương trình nguồn
từ trái sang phải (quét nguyên liệu - scanning) để tách ra thành các thẻ từ (token).
Ví dụ 1.2: Quá trình phân tích từ vựng cho câu lệnh gán position := initial + rate *
60 sẽ tách thành các token như sau:
1. Danh biểu position
2. Ký hiệu phép gán :=
3. Danh biểu initial
3

4. Ký hiệu phép cộng (+)
5. Danh biểu rate
6. Ký hiệu phép nhân (*)
7. Số 60
Trong quá trình phân tích từ vựng các khoảng trắng (blank) sẽ bị bỏ qua.
2. Phân tích cú pháp (Syntax Analysis)
Giai đoạn phân tích cú pháp thực hiện công việc nhóm các thẻ từ của chương trình
nguồn thành các ngữ đoạn văn phạm (grammatical phrase), mà sau đó sẽ được trình
biên dịch tổng hợp ra thành phẩm. Thông thường, các ngữ đoạn văn phạm này được
biểu diễn bằng dạng cây phân tích cú pháp (parse tree) với :
- Ngôn ngữ được đặc tả bởi các luật sinh.
- Phân tích cú pháp dựa vào luật sinh để xây dựng cây phân tích cú pháp.
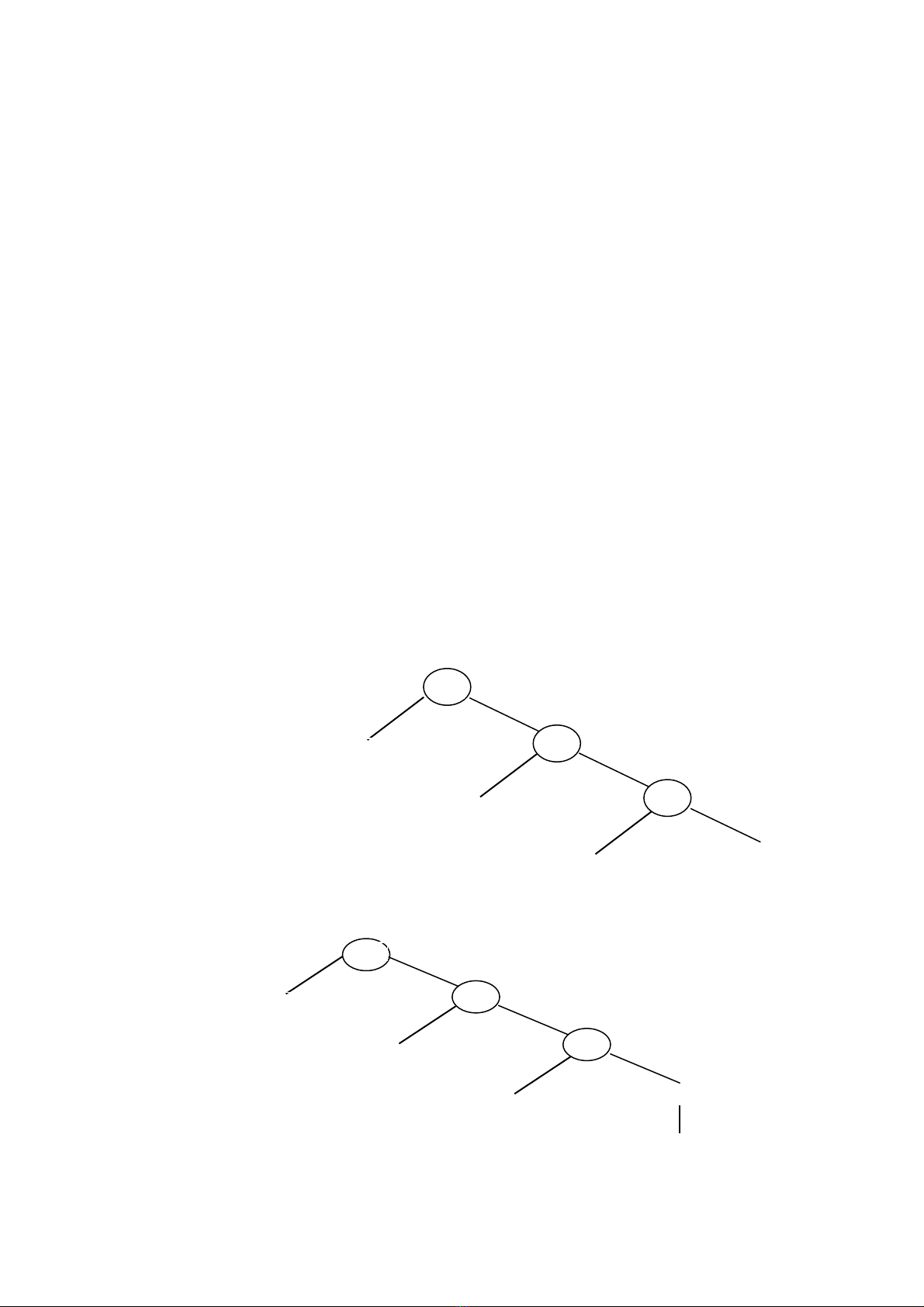
Ví dụ 1.3: Giả sử ngôn ngữ đặc tả bởi các luật sinh sau :
Stmt → id := expr
expr → expr + expr | expr * expr | id | number
Với câu nhập: position := initial + rate * 60, cây phân tích cú pháp được xây dựng
như sau :
Stmt
expr
expr
expr
expr
:=
+
id
id
number
id
60
rate
initial
expr
position
Hình 1.4 - Một cây phân tích cú pháp
Cấu trúc phân cấp của một chương trình thường được diễn tả bởi quy luật đệ qui.
Ví dụ 1.4:
1) Danh biểu (identifier) là một biểu thức (expr).
2) Số (number) là một biểu thức.
3) Nếu expr1 và expr2 là các biểu thức thì:
expr1 + expr2
expr1 * expr2
(expr)
4
cũng là những biểu thức.
Câu lệnh (statement) cũng có thể định nghĩa đệ qui :
1) Nếu id1 là một danh biểu và expr2 là một biểu thức thì id1 := expr2 là một
lệnh (stmt).
2) Nếu expr1 là một biểu thức và stmt2 là một lệnh thì
while (expr1) do stmt2
if (expr1) then stmt2
đều là các lệnh.
Người ta dùng các qui tắc đệ qui như trên để đặc tả luật sinh (production) cho
ngôn ngữ. Sự phân chia giữa quá trình phân tích từ vựng và phân tích cú pháp cũng
tuỳ theo công việc thực hiện.
3. Phân tích ngữ nghĩa (Semantic Analysis)
Giai đoạn phân tích ngữ nghĩa sẽ thực hiện việc kiểm tra xem chương trình nguồn
có chứa lỗi về ngữ nghĩa hay không và tập hợp thông tin về kiểu cho giai đoạn sinh mã
về sau. Một phần quan trọng trong giai đoạn phân tích ngữ nghĩa là kiểm tra kiểu (type
checking) và ép chuyển đổi kiểu.
Ví dụ 1.5: Trong biểu thức position := initial + rate * 60
Các danh biểu (tên biến) được khai báo là real, 60 là số integer vì vậy trình biên
dịch đổi số nguyên 60 thành số thực 60.0
+
*
position
initial
60
rate
:
=
thành
:=
+
*
p
osition
initial
inttoreal
rate
60.0
Hình 1.5 - Chuyển đổi kiểu trên cây phân tích cú pháp
5













![Bài giảng Tin học đại cương Trường Đại học Lâm Nghiệp [Năm mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260514/hoahongxanh0906/135x160/85781779160272.jpg)
![Giáo trình Cấu trúc dữ liệu và giải thuật - TS. Đào Thị Hường [Mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260514/hoahongxanh0906/135x160/49281779160273.jpg)




![Câu hỏi ôn tập Đồ hoạ máy tính [năm/khóa/chương trình]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260514/hoahongxanh0906/135x160/48771779155952.jpg)






%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23fff;%20}%20.st1%20{%20fill:%20%237800fa;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st1'%20d='M117.78,12.18H43.11c2.9,3.47,4.65,7.94,4.65,12.82,0,5.6-2.3,10.66-6.01,14.29h76.02l7.22-13.56-7.22-13.56Z'/%3e%3cg%3e%3cpath%20class='st0'%20d='M53.58,26.17h-.59v-1.46h.59v-4.96h2.83c1.78,0,2.67.94,2.67,2.82v5.76c0,1.87-.89,2.81-2.67,2.81h-2.83v-4.96ZM55.36,21.37v3.34h1.1v1.46h-1.1v3.34h1.01c.61,0,.91-.37.91-1.1v-5.93c0-.74-.3-1.1-.91-1.1h-1.01Z'/%3e%3cpath%20class='st0'%20d='M65.99,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM65.28,18.04c-.25.46-.51.77-.75.94-.21.15-.47.22-.79.22-.26,0-.57-.07-.92-.22l-.38-.15c-.14-.05-.26-.07-.37-.07-.3,0-.53.18-.71.54l-.91-.68c.25-.46.51-.77.75-.94.21-.14.48-.21.79-.21.26,0,.57.07.92.21l.38.15c.14.05.26.07.37.07.3,0,.53-.18.71-.54l.91.68ZM61.91,27.52h1.73l-.87-5.76-.87,5.76Z'/%3e%3cpath%20class='st0'%20d='M74.53,26.89v1.52c0,1.91-.89,2.86-2.67,2.86s-2.67-.95-2.67-2.86v-5.93c0-1.91.89-2.86,2.67-2.86s2.67.95,2.67,2.86v1.11h-1.69v-1.22c0-.75-.31-1.12-.93-1.12s-.93.37-.93,1.12v6.15c0,.74.31,1.11.93,1.11s.93-.37.93-1.11v-1.63h1.69Z'/%3e%3cpath%20class='st0'%20d='M81.4,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM75.9,19.2l1.52-1.91h1.71l1.51,1.91h-1.61l-.76-.95-.75.95h-1.61ZM77.32,27.52h1.73l-.87-5.76-.87,5.76ZM83.1,15.99l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M84.86,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM84.01,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M93.51,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM92.66,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M98.8,31.14h-1.79v-11.39h1.79v4.88h2.03v-4.88h1.83v11.39h-1.83v-4.88h-2.03v4.88Z'/%3e%3cpath%20class='st0'%20d='M105.36,24.55h2.46v1.62h-2.46v3.34h3.09v1.63h-4.88v-11.39h4.88v1.63h-3.09v3.18ZM108.17,17.29l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M112.2,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM111.35,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3c/g%3e%3ccircle%20class='st1'%20cx='25'%20cy='25'%20r='20'/%3e%3cpath%20class='st0'%20d='M32.78,19.27c2.92,0,4.43,2.55,5.28,5.33l.71,2.17c.14.38-.33.75-.71.75h-5.61c.19-.33.24-.71.09-1.08l-.75-2.45c-.43-1.32-.99-2.64-1.79-3.77.75-.57,1.65-.94,2.78-.94h0ZM25,18.38c3.25,0,4.9,2.78,5.89,5.89l.76,2.45c.14.42-.33.8-.8.8h-11.69c-.42,0-.94-.38-.8-.8l.75-2.45c.99-3.11,2.64-5.89,5.89-5.89h0ZM25,11.35c1.74,0,3.11,1.37,3.11,3.11s-1.37,3.11-3.11,3.11-3.11-1.41-3.11-3.11,1.41-3.11,3.11-3.11h0ZM17.27,19.27c1.08,0,1.98.38,2.73.94-.8,1.13-1.37,2.45-1.74,3.77l-.8,2.45c-.14.38-.05.75.09,1.08h-5.56c-.42,0-.9-.38-.75-.75l.71-2.17c.9-2.78,2.41-5.33,5.33-5.33h0ZM17.27,12.91c1.51,0,2.78,1.27,2.78,2.83s-1.27,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM32.78,12.91c1.56,0,2.78,1.27,2.78,2.83s-1.23,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM27.07,28.56v.09c0,.57-.24,1.08-.61,1.46h0v.05c-.38.33-.9.57-1.46.57s-1.08-.24-1.46-.61h0c-.38-.38-.61-.9-.61-1.46v-.09h1.41v.09c0,.19.05.38.19.47v.05c.09.09.28.19.47.19s.38-.09.47-.19v-.05c.14-.09.24-.28.24-.47t-.05-.09h1.41ZM30.99,28.56v.09c0,1.65-.66,3.16-1.74,4.24-1.08,1.08-2.59,1.79-4.24,1.79s-3.16-.71-4.24-1.79l-.05-.05c-1.04-1.08-1.7-2.55-1.7-4.2v-.09h1.41v.09c0,1.27.47,2.4,1.27,3.25h.05c.85.85,1.98,1.37,3.25,1.37s2.4-.52,3.25-1.37c.85-.8,1.37-1.98,1.37-3.25v-.09h1.37ZM34.99,28.56v.09c0,2.78-1.13,5.28-2.92,7.07-1.79,1.79-4.29,2.92-7.07,2.92s-5.23-1.13-7.07-2.92c-1.79-1.79-2.92-4.29-2.92-7.07v-.09h1.41v.09c0,2.4.94,4.53,2.5,6.08,1.56,1.56,3.72,2.5,6.08,2.5s4.52-.94,6.08-2.5c1.56-1.56,2.5-3.68,2.5-6.08v-.09h1.41Z'/%3e%3c/svg%3e)