Tuyển tập Hội nghị Khoa học thường niên năm 2024. ISBN: 978-604-82-8175-5
523
ỨNG DỤNG MÔ HÌNH HỌC MÁY LINEAR REGRESSION (LR)
VÀ RANDOM FOREST (RF) VÀ K-NEAREST NEIGHBORS (KNN)
TRONG DỰ BÁO MỰC NƯỚC HỆ THỐNG SÔNG HẬU -
ĐỒNG BẰNG SÔNG CỬU LONG
Trần Đăng An1, Thái Hữu Hùng1, Trần Xuân Thủy2, Triệu Ánh Ngọc1
1Trường Đại học Thủy lợi, email: ngocta@tlu.edu.vn
2Viện Công nghệ Tài nguyên nước và Môi trường
1. GIỚI THIỆU CHUNG
Dự báo mực nước là yếu tố quan trọng trong
quản lý tài nguyên nước, phòng chống thiên tai
và quy hoạch đô thị. Các phương pháp truyền
thống như mô hình toán học, thủy văn và thủy
lực gặp nhiều hạn chế do yêu cầu dữ liệu chi
tiết và độ phức tạp cao [1] [2] [3]. Trong bối
cảnh đó, các mô hình học máy (Machine
Learning) đã được phát triển và ứng dụng như
công cụ hữu ích trong việc xử lý lượng dữ liệu
lớn và học từ các mẫu dữ liệu lịch sử để dự báo
chính xác các thông số khí tượng thủy văn và
môi trường. Trong đó, phương pháp hồi quy
tuyến tính (Linear Regression - LR) được xem
là hiệu quả nhờ sự đơn giản và khả năng áp
dụng rộng rãi [4]. Nhiều nghiên cứu đã khẳng
định hiệu quả của Machine Learning trong dự
báo mực nước. Mosavi et al. (2018) đã áp dụng
Machine Learning để dự báo mực nước lũ và
đạt độ chính xác cao hơn so với các phương
pháp truyền thống với chỉ số xác định R2 >
0,85 và hệ số sai số < 0,2 [5].
Trong nghiên cứu này, ba phương pháp: K-
Nearest Neighbors (KNN), Linear Regression
(LR) và Random Forest Regression (RFR),
được sử dụng để phân tích độ tin cậy, tính
chính xác của từng phương pháp. Trạm thủy
văn Cần Thơ (trên sông Hậu) được sử dụng
để dự báo mực nước trong vòng 6 tháng để
làm rõ ưu điểm và hạn chế của các phương
pháp, khẳng định tính khả thi và hiệu quả
của Machine Learning trong quản lý tài
nguyên nước.
2. PHƯƠNG PHÁP NGHIÊN CỨU
Nhóm nghiên cứu sử dụng ba phương
pháp: (a) K-Nearest Neighbors (KNN), (b)
Linear Regression (LR), (c) Random Forest
Regression.
Hình 1. Phương pháp hồi quy KNN (a),
LR (b) và RFR (c)
(a) K-Nearest Neighbors (KNN) - Phương
pháp này dự đoán giá trị của một mới bằng
cách dựa vào thông tin từ K điểm dữ liệu gần
nhất trong tập huấn luyện (K-lân cận).
(b) Linear Regression (LR) - Phương pháp
này tìm một đường thẳng (hoặc siêu phẳng
trong trường hợp đa biến) phù hợp nhất với
dữ liệu, nhằm dự đoán giá trị của biến phụ
thuộc dựa trên giá trị của biến độc lập.
(c) Random Forest Regression (RFR) -
Phương pháp này tổng hợp kết quả từ nhiều
cây quyết định đơn lẻ, từ đó nâng cao hiệu
quả dự báo thông qua hình thức biểu quyết đa
số hoặc tính trung bình kết quả, tùy theo từng
bài toán cụ thể.
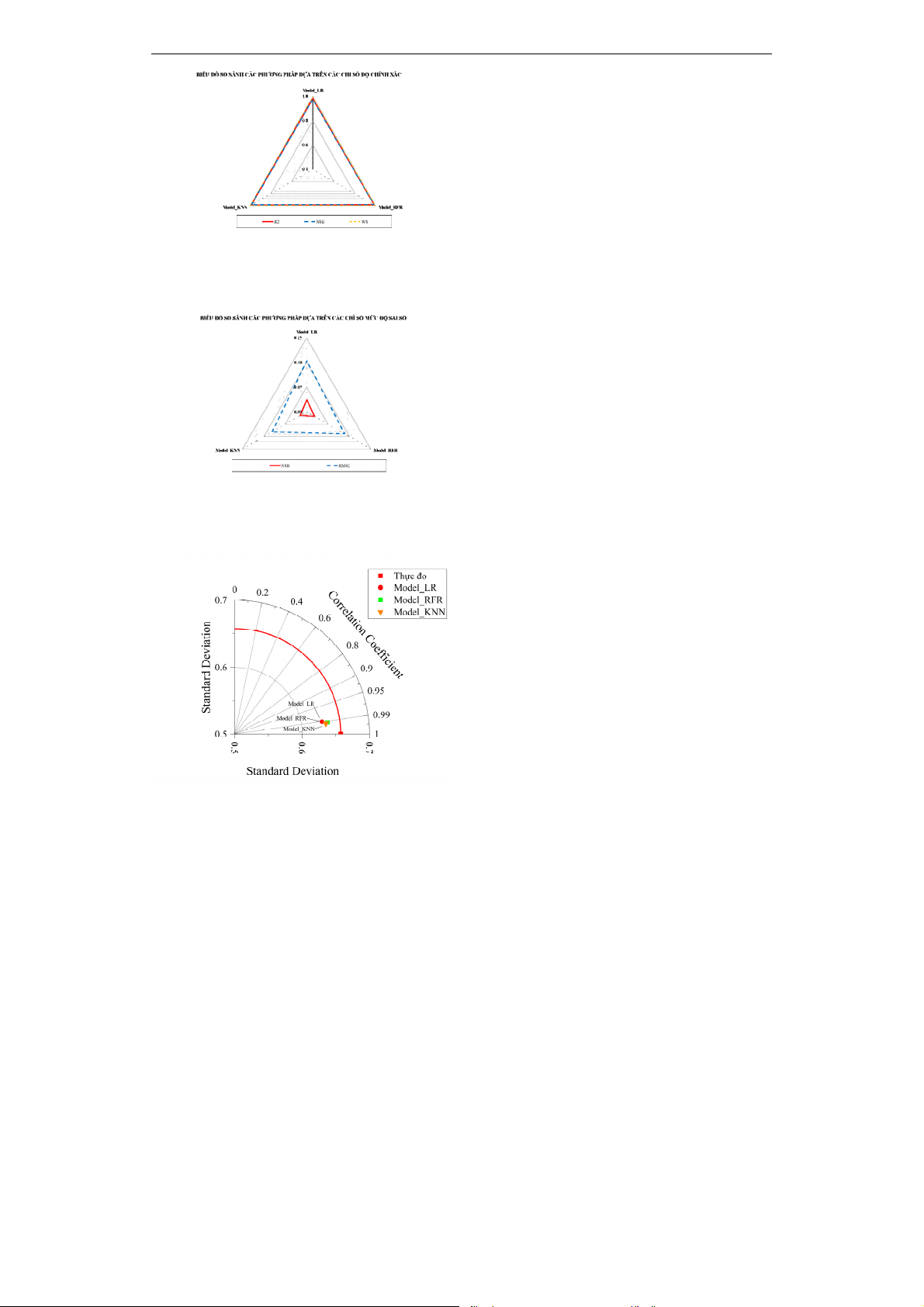
Để đánh giá mức độ dự báo chính xác của
các mô hình hồi quy, các tiêu chí đánh giá
sau đây được sử dụng: hệ số sai số - NSR (1),
RMSE (2). Và hệ số độ chính xác - R2 (3),
NSE (4) và WS (5). Công thức được thể hiện
dưới đây: