
Big Data nguồn mở, Phần 1: Hướng dẫn Hadoop: Tạo ứng
dụng Hello World với Java, Pig, Hive, Flume, Fuse, Oozie và
Sqoop với Informix, DB2 và MySQL
Có rất nhiều điều thú vị về Big Data và cũng có rất nhiều sự nhầm lẫn về nó. Bài
này sẽ cung cấp một định nghĩa về Big Data và sau đó thực hiện một loạt các ví dụ
để bạn có thể có được những hiểu biết ban đầu về một số khả năng của Hadoop,
công nghệ nguồn mở hàng đầu trong lĩnh vực Big Data. Cụ thể, ta tập trung vào
những câu hỏi sau:.
Big Data, Hadoop, Sqoop, Hive và Pig là gì và tại sao lĩnh vực này lại có
nhiều điều thú vị?
Hadoop liên quan đến DB2 và Informix của IBM như thế nào? Các công
nghệ này có thể chạy với nhau không?
Tôi có thể bắt đầu với Big Data như thế nào? Có ví dụ nào dễ để thử chạy
trên máy tính không?
Nếu bạn đã biết khái niệm về Hadoop rồi và muốn vào thẳng công việc với
các ví dụ mẫu, thì hãy làm như sau.
1. Hãy bắt đầu chạy một thể hiện Informix hoặc DB2 của bạn.
2. Tải về file ảnh cho máy ảo VMWare từ Trang web của Cloudera và
tăng thông số RAM máy ảo lên thành 1,5 GB.
3. Chuyển đến mục chứa các ví dụ mẫu.
4. Có một thể hiện MySQL đã được xây dựng sẵn trong máy ảo
VMWare này. Nếu bạn đang làm các bài thực hành mà không kết nối
mạng, hãy sử dụng các ví dụ MySQL này.
Ngoài ra, xin vui lòng xem tiếp...
Big Data là gì?
Big Data lớn về số lượng, được bắt giữ với tốc độ nhanh, có cấu trúc hoặc không
có cấu trúc, hoặc là bao gồm các yếu tố ở trên. Những yếu tố này làm cho Big Data
khó bắt giữ lại, khai phá và quản lý nếu dùng các phương thức truyền thống. Có rất
nhiều ý kiến về lĩnh vực này, đến nỗi có thể cần đến một cuộc tranh luận kéo dài
chỉ để định nghĩa thế nào là Big Data.
Sử dụng công nghệ Big Data không chỉ giới hạn về các khối lượng lớn. Bài này sử
dụng các ví dụ mẫu nhỏ để minh họa các khả năng của công nghệ này. Tính đến
năm 2012, các hệ thống được coi là lớn nằm trong phạm vi 100 Petabyte.

Dữ liệu lớn có thể vừa là dữ liệu có cấu trúc, vừa là dữ liệu không có cấu trúc. Các
cơ sở dữ liệu quan hệ truyền thống, như Informix và DB2, cung cấp các giải pháp
đã được kiểm chứng với dữ liệu có cấu trúc. Thông qua khả năng mở rộng, các cơ
sở dữ liệu này cũng quản lý cả dữ liệu không có cấu trúc. Công nghệ Hadoop mang
đến những kỹ thuật lập trình mới và dễ sử dụng hơn để làm việc với các kho dữ
liệu lớn có cả dữ liệu có cấu trúc lẫn dữ liệu không có cấu trúc.
Về đầu trang
Tại sao lại có những điều thú vị ấy?
Có nhiều yếu tố tạo nên sự cường điệu xoay quanh Big Data, bao gồm:.
Mang tính toán và lưu trữ lại cùng với nhau trên phần cứng thông dụng: Cho
kết quả tốc độ nhanh với chi phí thấp.
Tỷ số giá hiệu năng: Công nghệ Big Data của Hadoop đưa ra mức tiết kiệm
chi phí đáng kể (hãy nghĩ đến một hệ số nhân xấp xỉ 10) với những cải thiện
hiệu năng đáng kể (một lần nữa, hãy nghĩ đến một hệ số nhân là 10). Lời lãi
của bạn có thể thay đổi. Nếu công nghệ hiện tại có thể bị đánh bại nặng nề
như vậy, thì thật đáng để xem xét xem Hadoop có thể bổ sung hoặc thay thế
các khía cạnh của kiến trúc hiện tại của bạn không.
Khả năng mở rộng quy mô tuyến tính: Tất cả các công nghệ song song đều
tuyên bố dễ mở rộng quy mô. Hadoop có khả năng mở rộng quy mô kể từ
khi phát hành bản mới nhất có khả năng mở rộng giới hạn số lượng các nút
vượt quá 4.000.
Truy cập đầy đủ đến dữ liệu không có cấu trúc: Một kho dữ liệu có thể mở
rộng quy mô cao với một mô hình lập trình song song thích hợp,
MapReduce, đã là một thách thức cho ngành công nghiệp từ lâu nay. Mô
hình lập trình của Hadoop không giải quyết tất cả vấn đề, nhưng nó là một
giải pháp mạnh cho nhiều nhiệm vụ.
Các bản phân phối Hadoop: IBM và Cloudera
Đối với những người mới bắt đầu thì họ thường bối rối rằng "Tôi có thể tìm phần
mềm để làm việc với Big Data ở đâu?" Các ví dụ trong bài này đều dựa trên bản
phân phối Hadoop miễn phí của Cloudera được gọi là CDH (viết tắt của Cloudera
distribution including Hadoop). Bản phân phối này có sẵn dưới dạng một file ảnh
máy ảo VMWare từ trang web Cloudera. Gần đây IBM đang sửa đổi nền tảng Big
Data của mình để chạy trên CDH. Xem thông tin chi tiết trong phần Tài nguyên.

Thường thì thuật ngữ công nghệ đột phá bị lạm dụng rất nhiều, nhưng có thể nó rất
phù hợp trong trường hợp này.
Về đầu trang
Hadoop là gì?
Dưới đây là một vài định nghĩa về Hadoop, mỗi định nghĩa nhắm vào một nhóm
đối tượng khác nhau trong doanh nghiệp:
Đối với các giám đốc điều hành: Hadoop là một dự án phần mềm nguồn mở
của Apache để thu được giá trị từ khối lượng/ tốc độ/ tính đa dạng đáng kinh
ngạc của dữ liệu về tổ chức của bạn. Hãy sử dụng dữ liệu thay vì vứt bỏ hầu
hết dữ liệu đó đi.
Đối với các giám đốc kỹ thuật: Hadoop là một bộ phần mềm nguồn mở để
khai phá Big Data có cấu trúc và không có cấu trúc về công ty của bạn. Nó
tích hợp với hệ sinh thái Business Intelligence của bạn.
Đối với nhân viên pháp lý: Hadoop là một bộ phần mềm nguồn mở được
nhiều nhà cung cấp đóng gói và hỗ trợ. Hãy xem phần Tài nguyên về việc
trả tiền sở hữu trí tuệ (IP).
Đối với các kỹ sư: Hadoop là một môi trường song song thực thi map-reduce
dựa trên Java, không chia sẻ gì cả. Hãy nghĩ đến hàng trăm, hàng ngàn máy
tính đang làm việc để giải quyết cùng một vấn đề, có khả năng khôi phục lỗi
dựng sẵn. Các dự án trong hệ sinh thái Hadoop cung cấp khả năng load (tải)
dữ liệu, hỗ trợ ngôn ngữ cấp cao, triển khai trên đám mây tự động và các khả
năng khác.
Đối với chuyên gia bảo mật: Hadoop là một bộ phần mềm bảo mật-
Kerberos.
Hadoop có những thành phần nào?
Dự án Hadoop của Apache có hai thành phần cốt lõi, kho lưu trữ tệp gọi là Hadoop
Distributed File System (HDFS – Hệ thống tệp phân tán Hadoop) và khung công
tác lập trình gọi là MapReduce. Có một số dự án hỗ trợ để sử dụng HDFS và
MapReduce. Bài này sẽ cung cấp một cái nhìn sơ lược, bạn hãy tìm đọc cuốn sách
của OReily "Hadoop The Definitive Guide", tái bản lần thứ 3, để biết thêm chi tiết.
Các định nghĩa dưới đây nhằm cung cấp cho bạn những thông tin cơ bản để sử
dụng các ví dụ mã tiếp theo. Bài này thực sự mong muốn giúp bạn bắt đầu bằng
trải nghiệm thực hành với công nghệ này. Đây là một bài hướng dẫn hơn là bài hỏi
đáp thảo luận.

HDFS: Nếu bạn muốn có hơn 4000 máy tính làm việc với dữ liệu của bạn,
thì tốt hơn bạn nên phổ biến dữ liệu của bạn trên hơn 4000 máy tính đó.
HDFS thực hiện điều này cho bạn. HDFS có một vài bộ phận dịch chuyển.
Các Datanode (Nút dữ liệu) lưu trữ dữ liệu của bạn và Namenode (Nút tên)
theo dõi nơi lưu trữ các thứ. Ngoài ra còn có những thành phần khác nữa,
nhưng như thế đã đủ để bắt đầu.
MapReduce: Đây là mô hình lập trình cho Hadoop. Có hai giai đoạn, không
ngạc nhiên khi được gọi là Map và Reduce. Để gây ấn tượng với các bạn bè
của bạn hãy nói với họ là có một quá trình shuffle-sort (ND.: một quá trình
mà hệ thống thực hiện sắp xếp và chuyển các kết quả đầu ra của map tới các
đầu vào của các bộ rút gọn) giữa hai giai đoạn Map và Reduce. JobTracker
(Trình theo dõi công việc) quản lý hơn 4000 thành phần công việc
MapReduce. Các TaskTracker (Trình theo dõi nhiệm vụ) nhận các lệnh từ
JobTracker. Nếu bạn thích Java thì viết mã bằng Java. Nếu bạn thích SQL
hoặc các ngôn ngữ khác không phải Java thì rất may là bạn có thể sử dụng
một tiện ích gọi là Hadoop Streaming (Luồng dữ liệu Hadoop).
Hadoop Streaming: Một tiện ích để tạo nên mã MapReduce bằng bất kỳ
ngôn ngữ nào: C, Perl, Python, C++, Bash, v.v. Các ví dụ bao gồm một trình
mapper Python và một trình reducer AWK.
Hive và Hue: Nếu bạn thích SQL, bạn sẽ rất vui khi biết rằng bạn có thể viết
SQL và yêu cầu Hive chuyển đổi nó thành một tác vụ MapReduce. Đúng là
bạn chưa có một môi trường ANSI-SQL đầy đủ, nhưng bạn có 4000 ghi
chép và khả năng mở rộng quy mô ra nhiều Petabyte. Hue cung cấp cho bạn
một giao diện đồ họa dựa trên trình duyệt để làm công việc Hive của bạn.
Pig: Một môi trường lập trình mức cao hơn để viết mã MapReduce. Ngôn
ngữ Pig được gọi là Pig Latin. Bạn có thể thấy các quy ước đặt tên hơi khác
thường một chút, nhưng bạn sẽ có tỷ số giá-hiệu năng đáng kinh ngạc và
tính sẵn sàng cao.
Sqoop: Cung cấp việc truyền dữ liệu hai chiều giữa Hadoop và cơ sở dữ liệu
quan hệ yêu thích của bạn.
Oozie: Quản lý luồng công việc Hadoop. Oozie không thay thế trình lập lịch
biểu hay công cụ BPM của bạn, nhưng nó cung cấp cấu trúc phân nhánh if-
then-else và điều khiển trong phạm vi tác vụ Hadoop của bạn.
HBase: Một kho lưu trữ key-value có thể mở rộng quy mô rất lớn. Nó hoạt
động rất giống như một hash-map để lưu trữ lâu bền (với những người hâm
mộ python, hãy nghĩ đến một từ điển). Nó không phải là một cơ sở dữ liệu
quan hệ, mặc dù có tên là HBase.
FlumeNG: Trình nạp thời gian thực để tạo luồng dữ liệu của bạn vào
Hadoop. Nó lưu trữ dữ liệu trong HDFS và HBase. Bạn sẽ muốn bắt đầu với
FlumeNG, để cải thiện luồng ban đầu.

Whirr: Cung cấp Đám mây cho Hadoop. Bạn có thể khởi động một hệ thống
chỉ trong vài phút với một tệp cấu hình rất ngắn.
Mahout: Máy học dành cho Hadoop. Được sử dụng cho các phân tích dự báo
và phân tích nâng cao khác.
Fuse: Làm cho hệ thống HDFS trông như một hệ thống tệp thông thường, do
đó bạn có thể sử dụng lệnh ls, cd, rm và những lệnh khác với dữ liệu HDFS.
Zookeeper: Được sử dụng để quản lý đồng bộ cho hệ thống. Bạn sẽ không
phải làm việc nhiều với Zookeeper, nhưng nó sẽ làm việc rất nhiều cho bạn.
Nếu bạn nghĩ rằng bạn cần viết một chương trình có sử dụng Zookeeper thì
bạn hoặc là rất, rất thông minh và bạn có thể là một ủy viên cho một dự án
Apache hoặc bạn sắp có một ngày rất tồi tệ.
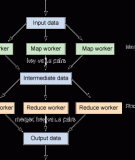
Hình 1 cho thấy các phần quan trọng của Hadoop.
Hình 1. Kiến trúc Hadoop
HDFS, tầng dưới cùng, nằm trên một cụm phần cứng thông thường. Các máy chủ
lắp vào tủ khung (rack-mounted) đơn giản, mỗi máy chủ có các CPU lõi 2-Hex, 6
đến 12 đĩa và 32 Gb ram. Đối với một công việc map-reduce, tầng trình ánh xạ đọc
từ các đĩa ở tốc độ rất cao. Trình ánh xạ phát ra các cặp khóa giá trị được sắp xếp
và được đưa tới trình rút gọn và tầng trình rút gọn tóm lược các cặp key-value.
Không, bạn không phải tóm lược các cặp key-value, trên thực tế bạn có thể có một
tác vụ map-reduce chỉ có có các trình ánh xạ. Điều này sẽ trở nên dễ hiểu hơn khi
bạn xem ví dụ python-awk.
Hadoop tích hợp với cơ sở hạ tầng Informix hoặc DB2 như thế nào?
Hadoop tích hợp rất tốt với cơ sở dữ liệu Informix và cơ sở dữ liệu DB2 thông qua
Sqoop. Sqoop là công cụ nguồn mở hàng đầu để di chuyển dữ liệu giữa Hadoop và
các cơ sở dữ liệu quan hệ. Nó sử dụng JDBC để đọc và viết vào Informix, DB2,
MySQL, Oracle và các nguồn khác. Có các bộ thích ứng được tối ưu hoá cho một
vài cơ sở dữ liệu, bao gồm Netezza và DB2. Hãy xem phần Tài nguyên về cách tải
về các bộ thích ứng này. Tất cả các ví dụ đều là đặc trưng của Sqoop.






![Đề thi giữa kì 1 môn Cấu trúc dữ liệu và giải thuật: Tổng hợp [Năm]](https://cdn.tailieu.vn/images/document/thumbnail/2012/20121223/loc_x_m/135x160/621356314200.jpg)
















![Tập bài giảng Thiết kế đa phương tiện (Nghề: Công nghệ thông tin) - Trường Cao đẳng Nông nghiệp Thanh Hóa [Mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260423/songngu_011/135x160/79441777364094.jpg)

%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23fff;%20}%20.st1%20{%20fill:%20%237800fa;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st1'%20d='M117.78,12.18H43.11c2.9,3.47,4.65,7.94,4.65,12.82,0,5.6-2.3,10.66-6.01,14.29h76.02l7.22-13.56-7.22-13.56Z'/%3e%3cg%3e%3cpath%20class='st0'%20d='M53.58,26.17h-.59v-1.46h.59v-4.96h2.83c1.78,0,2.67.94,2.67,2.82v5.76c0,1.87-.89,2.81-2.67,2.81h-2.83v-4.96ZM55.36,21.37v3.34h1.1v1.46h-1.1v3.34h1.01c.61,0,.91-.37.91-1.1v-5.93c0-.74-.3-1.1-.91-1.1h-1.01Z'/%3e%3cpath%20class='st0'%20d='M65.99,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM65.28,18.04c-.25.46-.51.77-.75.94-.21.15-.47.22-.79.22-.26,0-.57-.07-.92-.22l-.38-.15c-.14-.05-.26-.07-.37-.07-.3,0-.53.18-.71.54l-.91-.68c.25-.46.51-.77.75-.94.21-.14.48-.21.79-.21.26,0,.57.07.92.21l.38.15c.14.05.26.07.37.07.3,0,.53-.18.71-.54l.91.68ZM61.91,27.52h1.73l-.87-5.76-.87,5.76Z'/%3e%3cpath%20class='st0'%20d='M74.53,26.89v1.52c0,1.91-.89,2.86-2.67,2.86s-2.67-.95-2.67-2.86v-5.93c0-1.91.89-2.86,2.67-2.86s2.67.95,2.67,2.86v1.11h-1.69v-1.22c0-.75-.31-1.12-.93-1.12s-.93.37-.93,1.12v6.15c0,.74.31,1.11.93,1.11s.93-.37.93-1.11v-1.63h1.69Z'/%3e%3cpath%20class='st0'%20d='M81.4,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM75.9,19.2l1.52-1.91h1.71l1.51,1.91h-1.61l-.76-.95-.75.95h-1.61ZM77.32,27.52h1.73l-.87-5.76-.87,5.76ZM83.1,15.99l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M84.86,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM84.01,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M93.51,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM92.66,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M98.8,31.14h-1.79v-11.39h1.79v4.88h2.03v-4.88h1.83v11.39h-1.83v-4.88h-2.03v4.88Z'/%3e%3cpath%20class='st0'%20d='M105.36,24.55h2.46v1.62h-2.46v3.34h3.09v1.63h-4.88v-11.39h4.88v1.63h-3.09v3.18ZM108.17,17.29l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M112.2,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM111.35,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3c/g%3e%3ccircle%20class='st1'%20cx='25'%20cy='25'%20r='20'/%3e%3cpath%20class='st0'%20d='M32.78,19.27c2.92,0,4.43,2.55,5.28,5.33l.71,2.17c.14.38-.33.75-.71.75h-5.61c.19-.33.24-.71.09-1.08l-.75-2.45c-.43-1.32-.99-2.64-1.79-3.77.75-.57,1.65-.94,2.78-.94h0ZM25,18.38c3.25,0,4.9,2.78,5.89,5.89l.76,2.45c.14.42-.33.8-.8.8h-11.69c-.42,0-.94-.38-.8-.8l.75-2.45c.99-3.11,2.64-5.89,5.89-5.89h0ZM25,11.35c1.74,0,3.11,1.37,3.11,3.11s-1.37,3.11-3.11,3.11-3.11-1.41-3.11-3.11,1.41-3.11,3.11-3.11h0ZM17.27,19.27c1.08,0,1.98.38,2.73.94-.8,1.13-1.37,2.45-1.74,3.77l-.8,2.45c-.14.38-.05.75.09,1.08h-5.56c-.42,0-.9-.38-.75-.75l.71-2.17c.9-2.78,2.41-5.33,5.33-5.33h0ZM17.27,12.91c1.51,0,2.78,1.27,2.78,2.83s-1.27,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM32.78,12.91c1.56,0,2.78,1.27,2.78,2.83s-1.23,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM27.07,28.56v.09c0,.57-.24,1.08-.61,1.46h0v.05c-.38.33-.9.57-1.46.57s-1.08-.24-1.46-.61h0c-.38-.38-.61-.9-.61-1.46v-.09h1.41v.09c0,.19.05.38.19.47v.05c.09.09.28.19.47.19s.38-.09.47-.19v-.05c.14-.09.24-.28.24-.47t-.05-.09h1.41ZM30.99,28.56v.09c0,1.65-.66,3.16-1.74,4.24-1.08,1.08-2.59,1.79-4.24,1.79s-3.16-.71-4.24-1.79l-.05-.05c-1.04-1.08-1.7-2.55-1.7-4.2v-.09h1.41v.09c0,1.27.47,2.4,1.27,3.25h.05c.85.85,1.98,1.37,3.25,1.37s2.4-.52,3.25-1.37c.85-.8,1.37-1.98,1.37-3.25v-.09h1.37ZM34.99,28.56v.09c0,2.78-1.13,5.28-2.92,7.07-1.79,1.79-4.29,2.92-7.07,2.92s-5.23-1.13-7.07-2.92c-1.79-1.79-2.92-4.29-2.92-7.07v-.09h1.41v.09c0,2.4.94,4.53,2.5,6.08,1.56,1.56,3.72,2.5,6.08,2.5s4.52-.94,6.08-2.5c1.56-1.56,2.5-3.68,2.5-6.08v-.09h1.41Z'/%3e%3c/svg%3e)