
Exploring Composite Indexes for Domain Adaptation
in Neural Machine Translation
Nhan Vo Minh , Khue Nguyen Tran Minh , Long H. B. Nguyen
*
and Dien Dinh
Faculty of Information Technology, University of Science
Ho Chi Minh City, Vietnam
Vietnam National University
Ho Chi Minh City, Vietnam
*
nhblong@fit.hcmus.edu.vn;long.hb.nguyen@gmail.com
Received 2 April 2023
Revised 24 July 2023
Accepted 22 August 2023
Published 23 September 2023
Domain adaptation in neural machine translation (NMT) tasks often involves working with
datasets that have a di®erent distribution from the training data. In such scenarios, k-nearest-
neighbor machine translation (kNN-MT) has been shown to be e®ective in retrieving relevant
information from large datastores. However, the high-dimensional context vectors of large
neural machine translation model result in high computational costs for distance computation
and storage. To address this issue, index optimization techniques have been proposed, including
the use of inverted ¯le index (IVF) and product vector quantization (PQ), called IVFPQ. In this
paper, we explore the recent index techniques for e±cient machine translation domain adap-
tation and combine multiple index structures to improve the e±ciency of nearest-neighbor
search in domain adaptation datasets for machine translation task. Speci¯cally, we evaluate the
e®ectiveness when combining optimized product quantization (OPQ) and hierarchical navi-
gable small-world (HNSW) indexing with IVFPQ. Our study aims to provide insights into the
most suitable composite index methods for e±cient nearest-neighbor search in domain adap-
tation datasets, with a focus on improving both accuracy and speed.
Keywords: Domain adaptation in neural machine translation; k-nearest-neighbor machine
translation; index method.
1. Introduction
Modern neural machine translation (NMT) models are mostly parametric, meaning
that the output for each input depends only on a ¯xed number of model parameters
obtained from some training data in the same domain.
1,2
However, in real-world
*
Corresponding author.
This is an Open Access article published by World Scienti¯c Publishing Company. It is distributed under
the terms of the Creative Commons Attribution 4.0 (CC BY) License which permits use, distribution and
reproduction in any medium, provided the original work is properly cited.
OPEN ACCESS
Vietnam Journal of Computer Science
Vol. 11, No. 1 (2024) 75–94
#
.
cThe Author(s)
DOI: 10.1142/S2196888823500148
75
Vietnam J. Comp. Sci. 2024.11:75-94. Downloaded from www.worldscientific.com
by 2402:800:f473:a235:98cc:533f:b145:9069 on 10/07/25. Re-use and distribution is strictly not permitted, except for Open Access articles.

scenarios, the input to the NMT system often comes from domains that were not part
of the training data, resulting in suboptimal translations. One solution to this issue is
to train or ¯ne-tune the entire model or a part of it for each domain, but this can be
costly and may result in catastrophic forgetting.
3
Recently, a promising approach has been to augment parametric models with a
retrieval component, leading to semi-parametric models.
4–6
These models construct a
datastore based on a set of source/target sentences or word-level contexts, i.e.
translation memories, and retrieve similar examples from the datastore during the
generation process. This allows for the use of a single model for multiple domains.
However, the runtime of the model increases with the size of the domain's
datastore, and searching for related examples on large datastores can be computa-
tionally expensive. For instance, when retrieving 64 neighbors from the datastore,
the model may become two orders of magnitude slower.
6
To address this issue, recent works have proposed methods that aim to make the
retrieval process more e±cient. For example, Meng et al.
7
proposed constructing a
separate datastore for each source sentence by ¯rst searching for the neighbors of the
source tokens, while He et al.
8
suggested various techniques such as adaptive retrieval
and dimension reduction for k-nearest-neighbor machine translation (kNN-MT).
In this paper, we adapt the dimension reduction and cache methods proposed
by He et al.
8
and Martins et al.
9
to kNN-MT, and further examine various compo-
site index methods that increase the approximate k-nearest-neighbor search
over the datastore performance. The index is implemented using FAISS
10
which
was previously proposed by Khandelwal et al.
6
to implement ANN search in
kNN-MT. The index method basically combines inverted ¯le index
11
and product
vector quantization
12
which proved to reduce memory usage by only storing quan-
tized vectors and accelerates kNN search by pre-clustering the datastore vectors.
We examine various composite index methods for the e±cient nearest-neighbor
(NN) retrieval of information from large NLP databases. Our focus is to improve the
existing indexing methods and to explore the trade-o®s between indexing speed,
accuracy and memory usage.
2. Related Studies
The primary objective of NMT is to develop a neural network model that can au-
tomatically translate text from source language to target language. Usually, the
NMT model performs well on sentences that have the same data distribution with
the training data or in-domain data. However, the model struggles when dealing with
out-of-domain data. That is why domain adaptation in NMT is used to improve the
performance of this model in target domain by adapting it from source domain where
the training data may be insu±cient or unavailable. In this section, we present
various related studies that have been published on the approaches of domain
adaptation in NMT.
76 N. V. Minh et al.
Vietnam J. Comp. Sci. 2024.11:75-94. Downloaded from www.worldscientific.com
by 2402:800:f473:a235:98cc:533f:b145:9069 on 10/07/25. Re-use and distribution is strictly not permitted, except for Open Access articles.
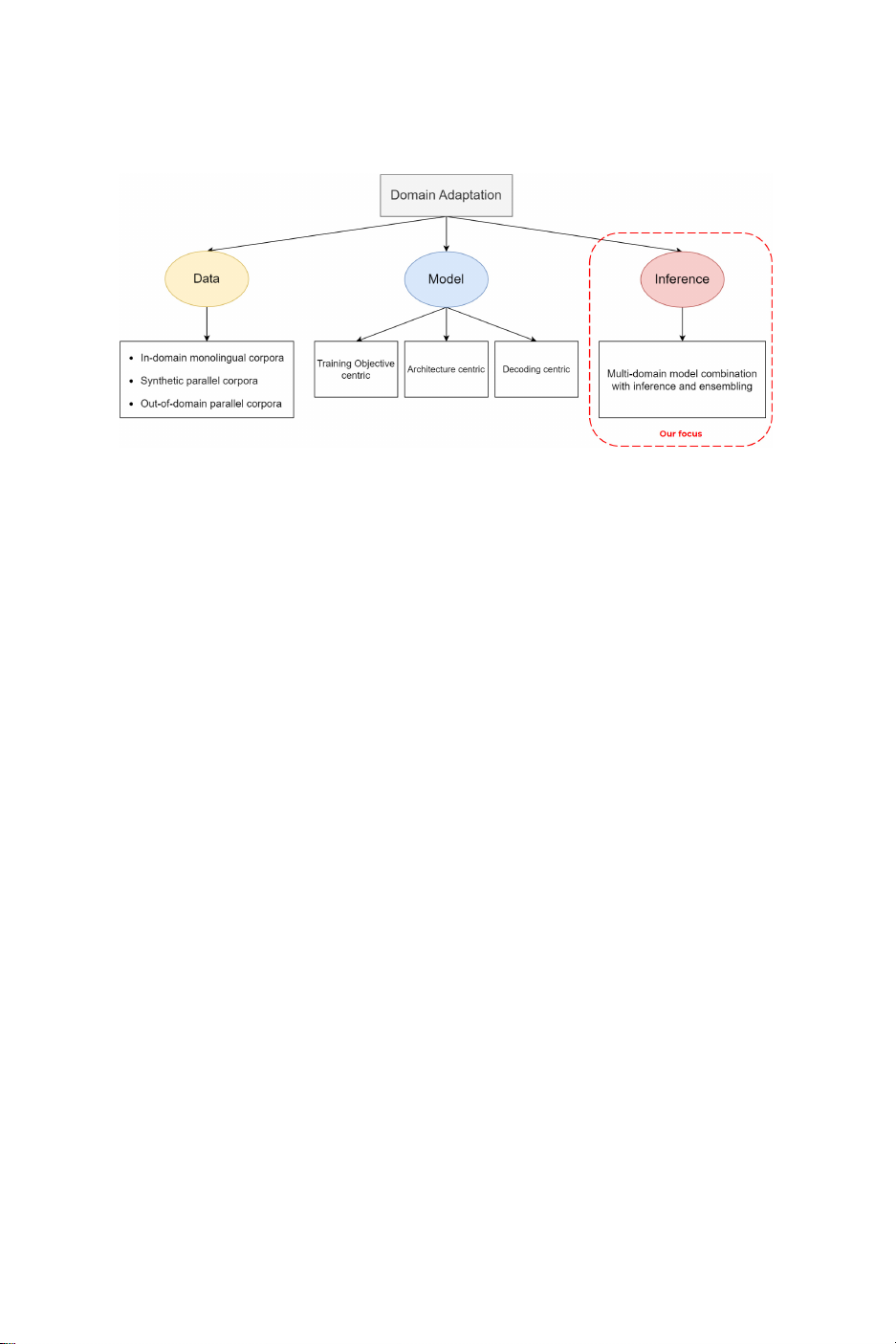
Based on Refs. 3and 13, domain adaptation for NMT is classi¯ed into three main
approaches: data-, model- and inference time-centric approaches. Figure 1shows
these three approaches.
The data-centric approach focuses on the data being used that can be in-domain
monolingual corpora, synthetic corpora or parallel corpora:
.In-domain monolingual corpora: They are a cheaper data source compared to
parallel bilingual sentence pairs and can be used to improve model performance in
MT. In statistical machine translation (SMT), monolingual data can be used
directly, while in NMT, more complex approaches are required to fuse LMs and
translation models.
14
For instance, the monolingual data can be used to train the
decoder as the LM and NMT using multi-task learning.
15
On the source side, the
monolingual data can be used to strengthen the encoder via multi-task learning
with both translation and reordering of source sentences.
16
.Synthetic parallel corpora: Back-translation of monolingual in-domain target
sentences can be used to generate a synthetic parallel corpus, which can further
enhance the decoder performance.
17
This technique can be applied to both the
source and target corpora.
.Out-of-domain parallel corpora: They are often cheaper and more widely available
than bilingual in-domain data. Therefore, it is desirable to use both types of data
when training the NMT to improve its performance on in-domain data while
achieving a solid baseline on out-of-domain data. The multi-domain method
18
uses
tags to inform the NMT as to whether a sentence is in-domain or out-of-domain.
The NMT system is trained on both in-domain and a smaller amount of out-of-
domain data while oversampling the in-domain sentences. Data selection methods
from SMT systems have limited e®ects on NMT because these methods do not
relate well to NMT. However, internal sentence embedding can be evaluated and
used as a measure of similarity between in-domain and out-of-domain data.
19
In
NMT, dynamically introducing in-domain data through gradual ¯ne-tuning can
Fig. 1. Overview of domain adaptation for the NMT task, based on Refs. 3and 13.
Exploring Composite Indexes for Domain Adaptation in NMT 77
Vietnam J. Comp. Sci. 2024.11:75-94. Downloaded from www.worldscientific.com
by 2402:800:f473:a235:98cc:533f:b145:9069 on 10/07/25. Re-use and distribution is strictly not permitted, except for Open Access articles.

lead to signi¯cant increases in BLEU scores.
20
The training data is scored based on
its relevance to in-domain translation, and starting with the entire dataset, more
and more relevant sentences are selected over several epochs, leading to smaller
subsets with more speci¯c data.
The model-centric approach focuses on changing the NMT models for domain
adaptation, which can be changing the training function or procedure, the NMT
architecture or the decoding algorithm.
Training objective-centric technique of model-centric group: Training objectives
can be manipulated to achieve better in-domain translation. Instance weighting
assigns a training weight using cross-entropy between two in-domain and out-of-
domain LMs to re°ect this goal.
21
However, this is challenging in NMT as it involves
nonlinear models due to the activation functions in the neural network. Another
method is ¯ne-tuning, which involves pre-training an NMT system on a larger,
parallel out-of-domain corpus and then optimizing the NMT parameters according
to a smaller in-domain corpus.
17
A re¯nement of this method is mixed ¯ne-tuning,
where the NMT is trained exclusively on an out-of-domain corpus until convergence
and then continues training on a mix of out-of-domain and in-domain data, with
oversampling of in-domain sentences. This approach has been shown to outperform
both multi-domain and ¯ne-tuning methods.
18
Model architecture-centric technique of model-centric group: It involves two
approaches as discussed below:
.One way to do this is through fusion approaches, where an in-domain Recurrent
Neural Network Language Model (RNNLM) is trained and combined with an
NMT model. Shallow fusion combines the scores from NMT and LM to choose the
best suitable translation, while deep fusion integrates RNNLM into the NMT
architecture to merge their internal representations, i.e. their hidden states, to
translate based on this fused representation. This can be done by training LM and
NMT separately or jointly.
14,15
.Another approach is to introduce a Domain Discriminator as a discriminative
method, e.g. a feed-forward neural network, on top of the encoder to predict the
domain of the source sentence.
22
Decoding-centric technique of model-centric group: This technique aims at modifying
the decoding algorithm, which makes them complementary to other model-centric
approaches:
.Shallow Fusion is an approach in this technique that combines the LM and NMT
scores during hypothesis generation.
14
When extending an existing subhypothesis,
the possible next words are evaluated based on a weighted sum of the NMT and
LM probabilities.
.Another approach is ensembling with models trained on out-of-domain data and a
¯ne-tuned in-domain model is another approach to prevent degrading model
78 N. V. Minh et al.
Vietnam J. Comp. Sci. 2024.11:75-94. Downloaded from www.worldscientific.com
by 2402:800:f473:a235:98cc:533f:b145:9069 on 10/07/25. Re-use and distribution is strictly not permitted, except for Open Access articles.

performance on out-of-domain translations.
23
This method involves combining the
outputs of multiple models, such as an out-of-domain model and an in-domain
model, to generate a single translation output.
Inference time-centric group: It means changing at inference time, i.e. we could
assign a separate model to each domain and combine them at inference. One example
of this approach is the k-nearest-neighbor machine translation proposed by Khan-
delwal et al.
6
Here, the authors build a speci¯c-domain datastore. The datastore will
map NMT decoder representations to in-domain target tokens. Then, at each in-
ference step, the NMT model's predictions are interpolated with a distribution of the
k-nearest-neighbor tokens. Their approach is robust since it overcomes the cata-
strophic forgetting problem of parametric NMT models. However, its drawback lies
in the slow model runtime and searching time when meeting a large datastore.
Our paper is based on kNN-MT proposed by Khandelwal et al.
6
of the inference
approach.
3. Background
3.1. The k-nearest-neighbor machine translation
The kNN-MT is a retrieval-based MT method that augments a pre-trained MT
model with a nearest-neighbor retrieval mechanism. This allows the model to have
direct access to a datastore of cached translation examples, improving its translation
quality. At each time step, the model ¯nds the kmost similar contexts in the
datastore and computes a distribution over the corresponding target tokens, which is
then interpolated with the output distribution from the pre-trained MT model.
To elaborate, NMT models take a source language input sequence, s¼
ðs1;...;sM1Þ, and generate a target language output sequence, t¼ðt1;...;tM2Þ.
Autoregressive decoders condition the output distribution for each target token ti
on both the source sequence and the previous target tokens, expressed as
pðtijs;t1:i1Þ. The translation context is denoted as s;t1:i1and the target token as ti.
Khandelwal et al.
6
constructed the datastore consisting of key–value pairs com-
puted o®line. The keys represent high-dimensional representations of the translation
context computed by the MT decoder using a mapping function fðs;t1:i1Þfrom
input to intermediate representation, while the values are the corresponding ground-
truth target tokens ti. For a parallel text collection ðS;TÞ, representations are
generated for each example with a single forward pass, and the complete datastore is
de¯ned as
ðK;VÞ ¼ fðfðs;t1:i1Þ;tiÞ;8ti2tjðs;tÞ2ðS;TÞg:
Note that source language tokens are not stored as values in the datastore, but are
implicitly conditioned via the keys, while the values correspond to target language
tokens.
During generation at test time, given a source sequence x, the NMT model
produces a distribution pMTðyijx;^
y1:i1Þover the target vocabulary for the target
Exploring Composite Indexes for Domain Adaptation in NMT 79
Vietnam J. Comp. Sci. 2024.11:75-94. Downloaded from www.worldscientific.com
by 2402:800:f473:a235:98cc:533f:b145:9069 on 10/07/25. Re-use and distribution is strictly not permitted, except for Open Access articles.






![Bài giảng Mạng nơ-ron nhân tạo trường Đại học Cần Thơ [PDF]](https://cdn.tailieu.vn/images/document/thumbnail/2013/20130331/o0_mrduong_0o/135x160/8661364662930.jpg)


















