
Chapter 6: The Lexer, Compiler, Resolver, and
Interpreter Objects
Now that you're familiar with Mason's basic syntax and some of its more
advanced features, it's time to explore the details of how the various pieces
of the Mason architecture work together to process components. By knowing
the framework well, you can use its pieces to your advantage, processing
components in ways that match your intentions.
In this chapter we'll discuss four of the persistent objects in the Mason
framework: the Interpreter, Resolver, Lexer, and Compiler. These objects
are created once (in a mod_perl setting, they're typically created when the
server is starting up) and then serve many Mason requests, each of which
may involve processing many Mason components.
Each of these four objects has a distinct purpose. The Resolver is responsible
for all interaction with the underlying component source storage mechanism,
which is typically a set of directories on a filesystem. The main job of the
Resolver is to accept a component path as input and return various properties
of the component such as its source, time of last modification, unique
identifier, and so on.
The Lexer is responsible for actually processing the component source code
and finding the Mason directives within it. It interacts quite closely with the
Compiler, which takes the Lexer's output and generates a Mason component
object suitable for interpretation at runtime.
The Interpreter ties the other three objects together. It is responsible for
taking a component path and arguments and generating the resultant output.
This involves getting the component from the resolver, compiling it, then
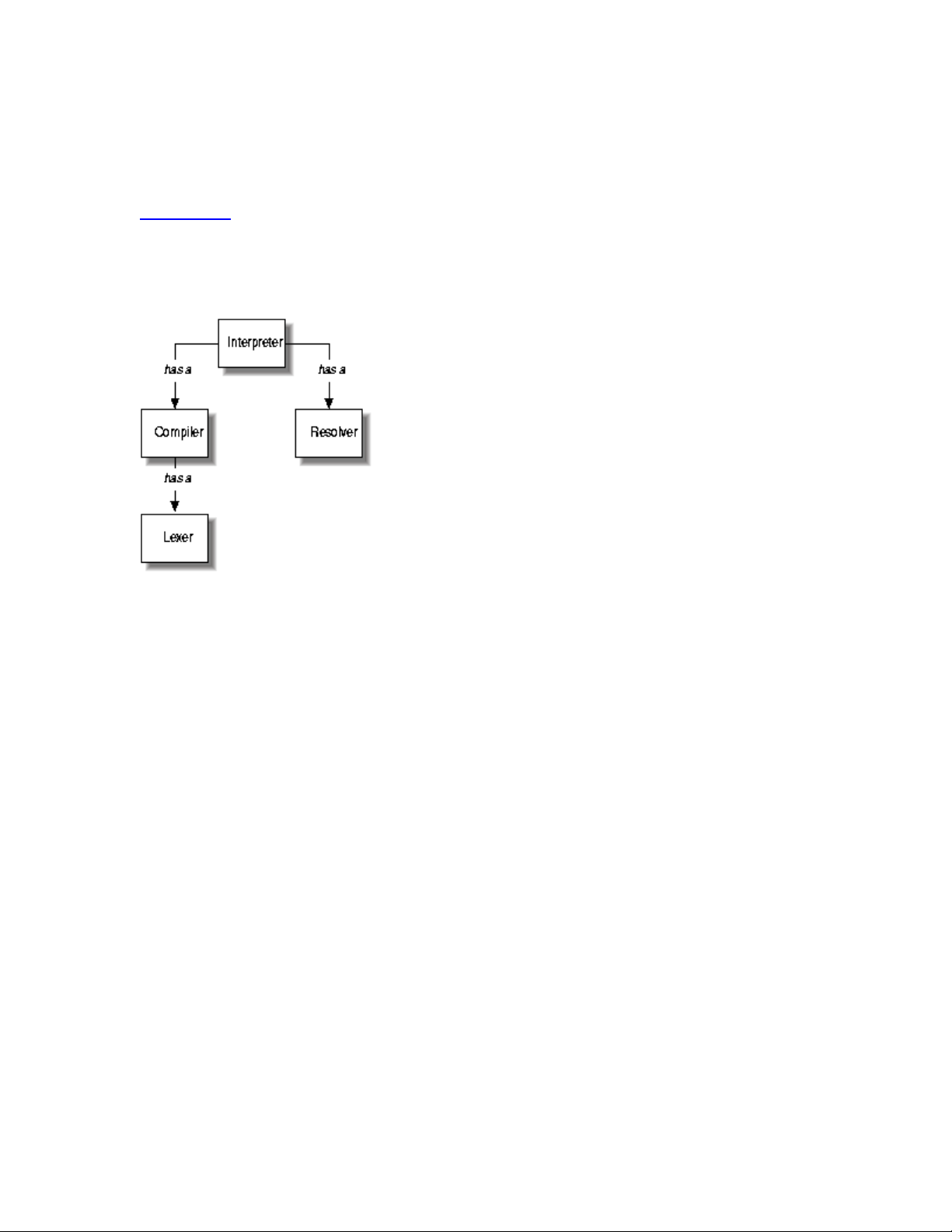
caching the compiled version so that next time the interpreter encounters the
same component it can skip the resolving and compiling phases.
Figure 6-1 illustrates the relationship between these four objects. The
Interpreter has a Compiler and a Resolver, and the Compiler has a Lexer.
Figure 6-1. The Interpreter and its cronies
Passing Parameters to Mason Classes
An interesting feature of the Mason code is that, if a particular object
contains another object, the containing object will accept constructor
parameters intended for the contained object. For example, the Interpreter
object will accept parameters intended for the Compiler or Resolver and do
the right thing with them. This means that you often don't need to know
exactly where a parameter goes. You just pass it to the object at the top of
the chain.
Even better, if you decide to create your own Resolver for use with Mason,
the Interpreter will take any parameters that your Resolver accepts -- not the
parameters defined by Mason's default Resolver class.

Also, if an object creates multiple delayed instances of another class, as the
Interpreter does with Request objects, it will accept the created class's
parameters in the same way, passing them to the created class at the
appropriate time. So if you pass the autoflush parameter to the
Interpreter's constructor, it will store this value and pass it to any Request
objects it creates later.
This system was motivated in part by the fact that many users want to be
able to configure Mason from an Apache config file. Under this system, the
user just sets a certain configuration directive (such as MasonAutoflush1
to set the autoflush parameter) in her httpd.conf file, and it gets directed
automatically to the Request objects when they are created.
The details of how this system works are fairly magical and the code
involved is so funky its creators don't know whether to rejoice or weep, but
it works, and you can take advantage of this if you ever need to create your
own custom Mason classes. Chapter 12 covers this in its discussion of the
Class::Container class, where all the funkiness is located.
The Lexer
Mason's built-in Lexer class is, appropriately enough,
HTML::Mason::Lexer . All it does is parse the text of Mason
components and pass off the sections it finds to the Compiler. As of Version
1.10, the Lexer doesn't actually accept any parameters that alter its behavior,
so there's not much for us to say in this section.
Future versions of Mason may include other Lexer classes to handle
alternate source formats. Some people -- crazy people, we assure you -- have
expressed a desire to write Mason components in XML, and it would be

fairly simple to plug in a new Lexer class to handle this. If you're one of
these crazy people, you may be interested in Chapter 12 to see how to use
objects of your own design as pieces of the Mason framework.
By the way, you may be wondering why the Lexer isn't called a Parser, since
its main job seems to be to parse the source of a component. The answer is
that previous implementations of Mason had a Parser class with a different
interface and role, and a different name was necessary to maintain forward
(though not backward) compatibility.
The Compiler
By default, Mason will use the
HTML::Mason::Compiler::ToObject class to do its compilation. It
is a subclass of the generic HTML::Mason::Compiler class, so we
describe here all parameters that the ToObject variety will accept,
including parameters inherited from its parent:
• allow_globals
You may want to allow access to certain Perl variables across all
components without declaring or initializing them each time. For
instance, you might want to let all components share access to a $dbh
variable that contains a DBI database handle, or you might want to
allow access to an Apache::Session%session variable.
For cases like these, you can set the allow_globals parameter to
an array reference containing the names of any global variables you
want to declare. Think of it like a broadly scoped use vars
declaration; in fact, that's exactly the way it's implemented under the

hood. If you wanted to allow the $dbh and %session variables, you
would pass an allow_globals parameter like the following:
allow_globals => ['$dbh', '%session']
Or in an Apache configuration file:
PerlSetVar MasonAllowGlobals $dbh
PerlAddVar MasonAllowGlobals %session
The allow_globals parameter can be used effectively with the
Perl local() function in an autohandler. The top-level autohandler
is a convenient place to initialize global variables, and local() is
exactly the right tool to ensure that they're properly cleaned up at the
end of the request:
# In the top-level autohandler:
<%init>
# $dbh and %session have been declared
using 'allow_globals'
local $dbh = DBI->connect(...connection
parameters...);
local *session; # Localize the glob so the
tie() expires properly
tie %session, 'Apache::Session::MySQL',
Apache::Cookie->fetch->{session_id}-
>value,
{ Handle => $dbh, LockHandle => $dbh };
![Tài liệu lập trình Node.js đơn giản, dễ hiểu [chuẩn nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260505/baobinh_011/135x160/6451777990429.jpg)

![Tài liệu ôn tập môn Lập trình web 1 [mới nhất/chuẩn nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20251208/hongqua8@gmail.com/135x160/8251765185573.jpg)





![Các chức năng cần có của website nhà hàng, ăn uống [chuẩn SEO]](https://cdn.tailieu.vn/images/document/thumbnail/2020/20200723/thunguyen0103/135x160/5651595496094.jpg)

















%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23fff;%20}%20.st1%20{%20fill:%20%237800fa;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st1'%20d='M117.78,12.18H43.11c2.9,3.47,4.65,7.94,4.65,12.82,0,5.6-2.3,10.66-6.01,14.29h76.02l7.22-13.56-7.22-13.56Z'/%3e%3cg%3e%3cpath%20class='st0'%20d='M53.58,26.17h-.59v-1.46h.59v-4.96h2.83c1.78,0,2.67.94,2.67,2.82v5.76c0,1.87-.89,2.81-2.67,2.81h-2.83v-4.96ZM55.36,21.37v3.34h1.1v1.46h-1.1v3.34h1.01c.61,0,.91-.37.91-1.1v-5.93c0-.74-.3-1.1-.91-1.1h-1.01Z'/%3e%3cpath%20class='st0'%20d='M65.99,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM65.28,18.04c-.25.46-.51.77-.75.94-.21.15-.47.22-.79.22-.26,0-.57-.07-.92-.22l-.38-.15c-.14-.05-.26-.07-.37-.07-.3,0-.53.18-.71.54l-.91-.68c.25-.46.51-.77.75-.94.21-.14.48-.21.79-.21.26,0,.57.07.92.21l.38.15c.14.05.26.07.37.07.3,0,.53-.18.71-.54l.91.68ZM61.91,27.52h1.73l-.87-5.76-.87,5.76Z'/%3e%3cpath%20class='st0'%20d='M74.53,26.89v1.52c0,1.91-.89,2.86-2.67,2.86s-2.67-.95-2.67-2.86v-5.93c0-1.91.89-2.86,2.67-2.86s2.67.95,2.67,2.86v1.11h-1.69v-1.22c0-.75-.31-1.12-.93-1.12s-.93.37-.93,1.12v6.15c0,.74.31,1.11.93,1.11s.93-.37.93-1.11v-1.63h1.69Z'/%3e%3cpath%20class='st0'%20d='M81.4,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM75.9,19.2l1.52-1.91h1.71l1.51,1.91h-1.61l-.76-.95-.75.95h-1.61ZM77.32,27.52h1.73l-.87-5.76-.87,5.76ZM83.1,15.99l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M84.86,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM84.01,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M93.51,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM92.66,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M98.8,31.14h-1.79v-11.39h1.79v4.88h2.03v-4.88h1.83v11.39h-1.83v-4.88h-2.03v4.88Z'/%3e%3cpath%20class='st0'%20d='M105.36,24.55h2.46v1.62h-2.46v3.34h3.09v1.63h-4.88v-11.39h4.88v1.63h-3.09v3.18ZM108.17,17.29l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M112.2,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM111.35,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3c/g%3e%3ccircle%20class='st1'%20cx='25'%20cy='25'%20r='20'/%3e%3cpath%20class='st0'%20d='M32.78,19.27c2.92,0,4.43,2.55,5.28,5.33l.71,2.17c.14.38-.33.75-.71.75h-5.61c.19-.33.24-.71.09-1.08l-.75-2.45c-.43-1.32-.99-2.64-1.79-3.77.75-.57,1.65-.94,2.78-.94h0ZM25,18.38c3.25,0,4.9,2.78,5.89,5.89l.76,2.45c.14.42-.33.8-.8.8h-11.69c-.42,0-.94-.38-.8-.8l.75-2.45c.99-3.11,2.64-5.89,5.89-5.89h0ZM25,11.35c1.74,0,3.11,1.37,3.11,3.11s-1.37,3.11-3.11,3.11-3.11-1.41-3.11-3.11,1.41-3.11,3.11-3.11h0ZM17.27,19.27c1.08,0,1.98.38,2.73.94-.8,1.13-1.37,2.45-1.74,3.77l-.8,2.45c-.14.38-.05.75.09,1.08h-5.56c-.42,0-.9-.38-.75-.75l.71-2.17c.9-2.78,2.41-5.33,5.33-5.33h0ZM17.27,12.91c1.51,0,2.78,1.27,2.78,2.83s-1.27,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM32.78,12.91c1.56,0,2.78,1.27,2.78,2.83s-1.23,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM27.07,28.56v.09c0,.57-.24,1.08-.61,1.46h0v.05c-.38.33-.9.57-1.46.57s-1.08-.24-1.46-.61h0c-.38-.38-.61-.9-.61-1.46v-.09h1.41v.09c0,.19.05.38.19.47v.05c.09.09.28.19.47.19s.38-.09.47-.19v-.05c.14-.09.24-.28.24-.47t-.05-.09h1.41ZM30.99,28.56v.09c0,1.65-.66,3.16-1.74,4.24-1.08,1.08-2.59,1.79-4.24,1.79s-3.16-.71-4.24-1.79l-.05-.05c-1.04-1.08-1.7-2.55-1.7-4.2v-.09h1.41v.09c0,1.27.47,2.4,1.27,3.25h.05c.85.85,1.98,1.37,3.25,1.37s2.4-.52,3.25-1.37c.85-.8,1.37-1.98,1.37-3.25v-.09h1.37ZM34.99,28.56v.09c0,2.78-1.13,5.28-2.92,7.07-1.79,1.79-4.29,2.92-7.07,2.92s-5.23-1.13-7.07-2.92c-1.79-1.79-2.92-4.29-2.92-7.07v-.09h1.41v.09c0,2.4.94,4.53,2.5,6.08,1.56,1.56,3.72,2.5,6.08,2.5s4.52-.94,6.08-2.5c1.56-1.56,2.5-3.68,2.5-6.08v-.09h1.41Z'/%3e%3c/svg%3e)