
1
Distributed Database
TS. Nguy n Đình Thuânễ

2
* Thiết kế hệ thống thông tin có CSDL phân tán
bao gồm:
- Phân tán và chọn những vị tri đặt dữ liệu;
- Các chương trình ứng dụng tại các điểm;
- Thiết kế tổ chức khai thác hệ thống đó trên mạng
* Định nghĩa 1:
Cơ sở dữ liệu (CSDL) phân tán là tập hợp dữ liệu,
mà về mặt logic tập hợp này thuộc cùng một hệ
thống, nhưng về mặt vật lý dữ liệu đó được phân tán
trên các vị trí khác nhau của một mạng máy tính.
3.1 Giới thiệu về CSDLPT

3
Sự phân tán dữ liệu (data distribution): dữ liệu phải được phân
tán ở nhiều nơi.
Sự tương quan luận lý (logical correlation): dữ liệu của các nơi
được sử dụng chung để cùng giải quyết một vấn đề.
Ví dụ:
- Một ngân hàng có ba chi nhánh ở các vị trí địa lý khác nhau.
- Tại mỗi chi nhánh có một máy tính và một cơ sở dữ liệu tài
khoản, tạo thành một nơi (site) của cơ sở dữ liệu phân tán.
- Các máy tính được kết nối với nhau thông qua một mạng
máy tính truyền thông.
- Một khách hàng có thể gửi tiền và rút tiền tại các chi nhánh.
3.1 Giới thiệu về CSDLPT

4
Định nghĩa 2: Cơ sở dữ liệu phân tán là tập hợp dữ liệu được
phân tán trên các máy tính khác nhau của một mạng máy tính.
Mỗi nơi của mạng máy tính có khả năng xử lý tự trị và có thể thực
hiện các ứng dụng cục bộ. Mỗi nơi cũng tham gia thực hiện ít
nhất một ứng dụng toàn cục, mà nơi này yêu cầu truy xuất dữ liệu
ở nhiều nơi bằng cách dùng hệ thống truyền thông.
- Sự phân tán dữ liệu (data distribution): dữ liệu phải được phân
tán ở nhiều nơi.
- Ứng dụng cục bộ (local application): ứng dụng được chạy hoàn
thành tại một nơi và chỉ sử dụng dữ liệu cục bộ của nơi này.
- Ứng dụng toàn cục (hoặc ứng dụng phân tán) (global application
/ distributed application): ứng dụng được chạy hoàn thành và sử
dụng dữ liệu của ít nhất hai nơi.
3.1 Giới thiệu về CSDLPT
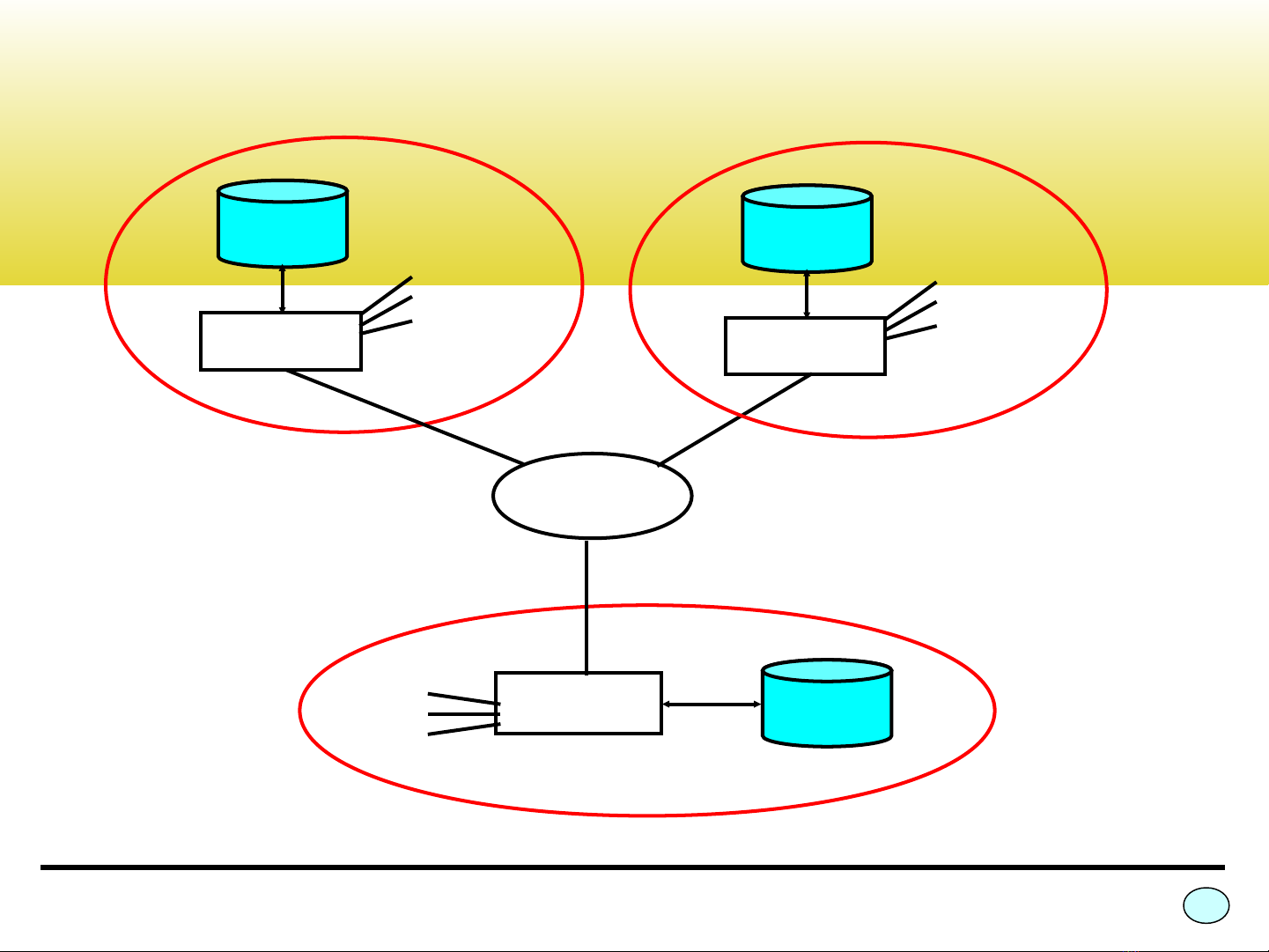
5
Máy tính 1
Terminal
T
T
Máy tính 3
T
T
T
Mạng truyền
thông
Cơ sở
dữ liệu 1
Máy tính 2
T
T
T
Cơ sở
dữ liệu 2
Cơ sở
dữ liệu 3
Chi nhánh 1 Chi nhánh 2
Chi nhánh 3
3.1 Giới thiệu về CSDLPT

























