
Chương 5
Phân lớp
KHAI PHÁ DỮ LIỆU

DM
DW
284
Nội dung
1. Giới thiệu phân lớp
2. Các kỹ tuật phân lớp

DM
DW
285
1. Giới thiệu phân lớp
Đầu vào
Tập dữ liệu D = {di}
Tập các lớp C1, C2, …, Ck mỗi dữ liệu d thuộc một lớp Ci
Tập ví dụ Dexam = D1+D2+ …+ Dkvới Di={dDexam: d thuộc
Ci}
Tập ví dụ Dexam đại diện cho tập D
Đầu ra
Mô hình phân lớp: ánh xạ từ D sang C
Sử dụng mô hình
d D \ Dexam : xác định lớp của đối tượng d
Bài toán phân lớp

DM
DW
286
Phân lớp: Quá trình hai pha
Xây dựng mô hình: Tìm mô tả cho tập lớp đã có
Cho trước tập lớp C = {C1, C2, …, Ck}
Cho ánh xạ (chưa biết) từ miền D sang tập lớp C
Có tập ví dụ Dexam=D1+D2+ …+ Dkvới Di={dDexam: dCi}
Dexam được gọi là tập ví dụ mẫu.
Xây dựng ánh xạ (mô hình) phân lớp trên: Dạy bộ phân lớp.
Mô hình: Luật phân lớp, cây quyết định, công thức toán học…
Pha 1: Dạy bộ phân lớp
Tách Dexam thành Dtrain (2/3) + Dtest (1/3). Dtrain và Dtest “tính đại
diện” cho miền ứng dụng
Dtrain : xây dựng mô hình phân lớp (xác định tham số mô hình)
Dtest : đánh giá mô hình phân lớp (các độ đo hiệu quả)
Chọn mô hình có chất lượng nhất
Pha 2: Sử dụng bộ phân lớp
d D \ Dexam : xác định lớp của d.
DM
DW
287
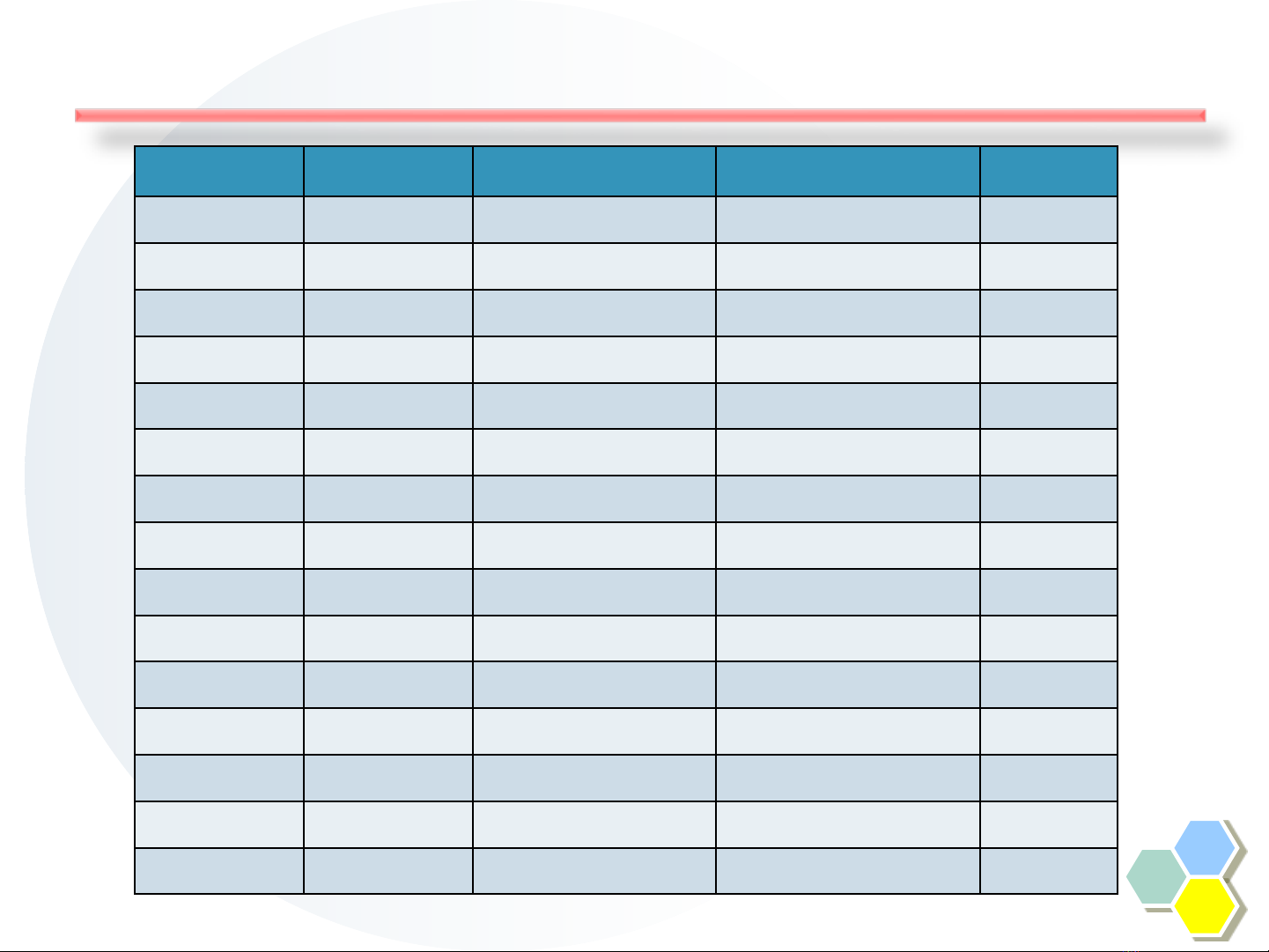
Ví dụ phân lớp: Bài toán cho vay
Tid Refund Marital Status Taxable Income Cheat
1No Single 75K No
2 Yes Married 50K No
3No Single 75K No
4No Married 150K Yes
5No Single 40K No
6No Married 80K Yes
7No Single 75K No
8 Yes Married 50K No
9 Yes Married 50K No
10 No Married 150K Yes
11 No Single 40K No
12 No Married 150K Yes
13 No Married 80K Yes
14 No Single 40K No
15 No Married 80K Yes






![Bài giảng Khai phá dữ liệu (Data mining): Introduction - Trịnh Tấn Đạt [Mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2023/20230918/diepkhinhchau/135x160/1792158917.jpg)


















