
LOGO
LẬPTRÌNH CHO KHOA HỌC DỮ LIỆU
Bài 11. Một số mô hình học máy

Nội dung
Phân cụm dữ liệu
1
Phân cụm mờ
2
2
3
Phân lớp SVM
4
Hồi quy tuyến tính
3
Phân cụm
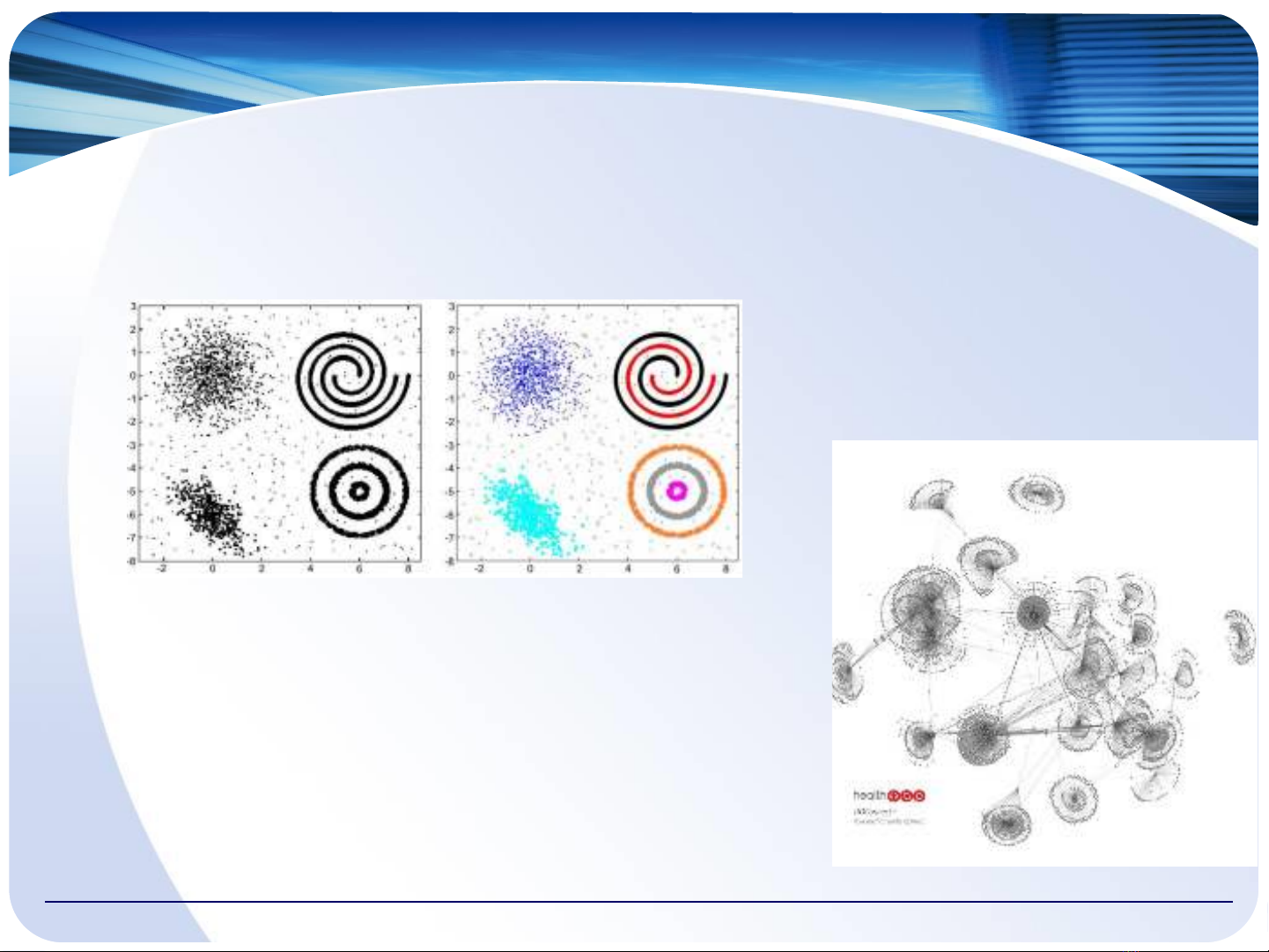
◼◼ Phân cụm (clustering)
❑❑ Phát hiện các cụm dữ liệu, cụm tính chất,…
◼◼ Community detection
◼◼ Phát hiện các cộng đồng trong mạng xã hội

4
Tổng quan
❖PCDL là một lĩnh vực liên ngành đang được phát
triển mạnh mẽ. Ở một mức cơ bản nhất, đưa ra
định nghĩa PCDL như sau [10][11]:
"PCDL là một kỹ thuật trong DATA
MINING, nhằm tìm kiếm, phát hiện các cụm, các
mẫu dữ liệu tự nhiên tiềm ẩn, quan tâm trong tập dữ
liệu lớn, từ đó cung cấp thông tin, tri thức hữu ích
cho ra quyết định"

5
Tổng quan
❖Như vậy, PCDL là quá trình phân chia một tập DL
ban đầu thành các cụm DL sao cho:
▪Các phần tử trong một cụm "tương tự" (Similar)
nhau.
▪Các phần tử trong các cụm khác nhau sẽ "phi
tương tự" (Dissimilar) nhau.
▪Số các cụm được xác định trước theo kinh
nghiệm hoặc tự động.




















![Bài giảng Phân tích thiết kế hệ thống [Mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20250811/vijiraiya/135x160/642_bai-giang-phan-tich-thiet-ke-he-thong.jpg)



