NDHien
XỬ LÝ SỐ LIỆU TRONG EXCEL
Giới thiệu về Data Analysis
Trong Bảng tính Excel có một phần chuyên xử lý số liệu, gọi là Data Analysis, tuy chưa
thật sâu nhưng trong tình hình hiện tại có thể coi là đủ dùng để xử lý thống kê các số liệu thu
thập được trong quá trình điều tra nghiên cứu (Tính các đặc trưng thống kê cơ bản, chia tổ, vẽ
biểu đồ, tính hệ số tương quan, hiệp phương sai, tính và vẽ đường hồi quy tuyến tính hoặc phi
tuyến, tính hồi quy bội tuyến tính, vẽ đồ thị kiểu cột, kiểu bánh tròn, làm trơn số liệu v.v...) và
trong các kiểu bố trí thí nghiệm với một hoặc hai nhân tố (Phân tích phương sai một nhân tố,
hai nhân tố, so sánh 2 phương sai, so sánh hai trung bình v v ...). Cách vào số liệu và chọn
công cụ xử lý đơn giản, dễ dùng, đồ hoạ đẹp. Tuy nhiên vì quan niệm người dùng đã biết cách
xử lý số liệu và hiểu được các kết quả nên Excel chỉ in ra các kết quả tóm tắt, không giải thích
gì thêm. Phần Help có tỷ mỷ hơn nhưng cũng rất vắn tắt.
Trước khi dùng phải có số liệu, tuỳ vấn đề mà sắp xếp số liệu cho thích hợp, sau đó vào
Menu Tools chọn Data Analysis (Nếu không thấythì phải mở Add -ins sau đó bổ sung thêm
Analysis Toolpak, nếu không thấy Analysis ToolPak thì phải Setup lại Excel để bổ sung).
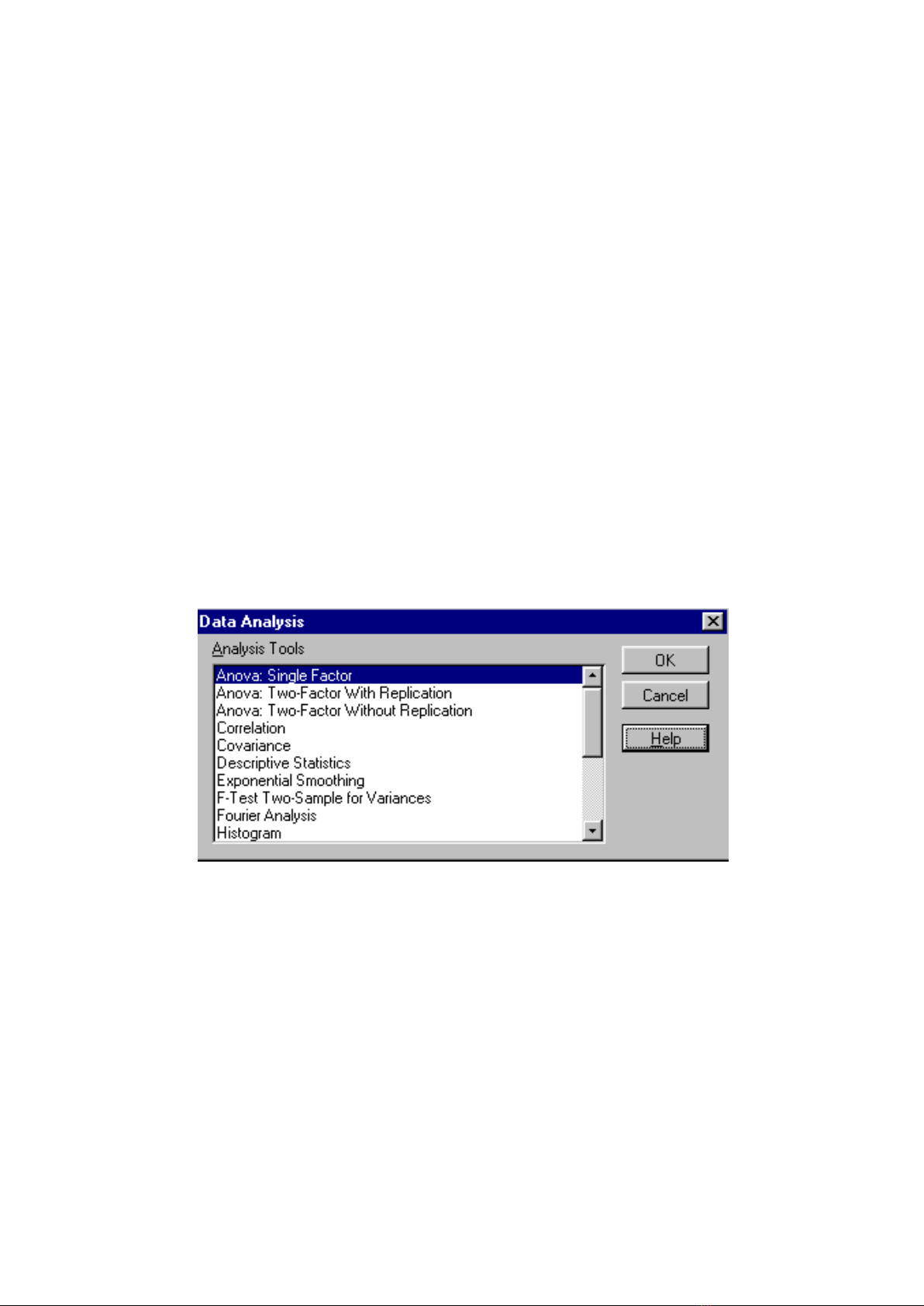
Menu Data Analysis có dạng như sau:
Chọn trong Menu công cụ xử lý thích hợp ta được một hộp thoại, nhìn chung mỗi hộp
thoại gồm 3 phần: Phần Input Range để ghi dịa chỉ miền số liệu cần xử lý, phần Options để có
các chọn lựa thích hợp, cuối cùng là phần Output Range để chọn nơi in ra kết quả.
Thí dụ Chọn Anova Single Factor (Phân tích phương sai một nhân tố) được hộp thoại
Input Range: ghi địa chỉ miền vào
Options : Số liệu để theo cột thì đánh dấu Columns, để theo hàng thì chọn Rows, có
tên các mức thì chọn Labels, chọn mức ý nghĩa Alpha
Output Range : ghi địa chỉ một vùng trắng trong Sheet để ghi kết quả
hoặc chọn 1 trang mới (New Worksheet)
hoặc một tệp mới (New Work Book)

NDHien
Có thể chia Data Analysis ra thành 5 nhóm:
1/ Thống kê mô tả:
Thống kê mô tả: Descriptive Statistics
Nhật đồ : Histogram Trung bình trượt: Moving Average
Làm trơn số liệu: Exponential Smoothing
Thứ hạng và phân vị: Rank and percentile
2/ So sánh:
So sánh hai phương sai của 2 mẫu quan sát: F- test two sample for means
So sánh hai trung bình khi lấy mẫu theo cặp: T- test Paired two samples for means
So sánh hai trung bình khi lấy mẫu độc lập T- test two sample assuming
giả thiết phương sai bằng nhau: equal variances
So sánh hai trung bình khi lấy mẫu độc lập T- test two sample assuming
giả thiết phương sai khác nhau: unequal variances
So sánh hai trung bình khi biết phương sai: Z- test two sample for means
3/ Phân tích phương sai:
Phân tích phương sai một nhân tố Anova single factor
Phân tích phương sai hai nhân tố không lặp lai Anova two factor without replication
Phân tích phương sai hai nhân tố có lặp lai Anova two factor with replication
4/ Hiệp phương sai, tương quan, hồi quy:
Hiệp phương sai Covariance
Tương quan Correlation
Hồi quy Regression
5/ Một số tiện ích
Lấy mẫu Sampling
Phân tích Fourrier Fourrier Analysis
Tạo số ngẫu nhiên Random number generation
NDHien
Bài1 THỐNG KÊ MÔ TẢ
I/ Nhật đồ (Histogram)
Khi có nhiều số liệu, để trong một cột hay để trong một bảng, chúng ta muốn chia
khoảng, tính các tần số ứng với mỗi khoảng sau đó vẽ nhật đồ để xem số liệu có phân phối
chuẩn không thì dùng Histogram.
Các bước làm như sau:
1- Để số liệu trong 1 cột hay bảng chữ nhật
2- Tìm giá trị lớn nhất bằng (hàm Max), giá trị nhỏ nhất (hàm Min)
lấy R = Max - Min
3- Chọn số khoảng n (trong thực tế thường chọn n từ 20 - 30)
4- Tìm h = R / n (Để bớt lẻ có thể dùng hàm Round§ (h, số số lẻ)
5- Tạo cột Bin sau đó gọi Histogram
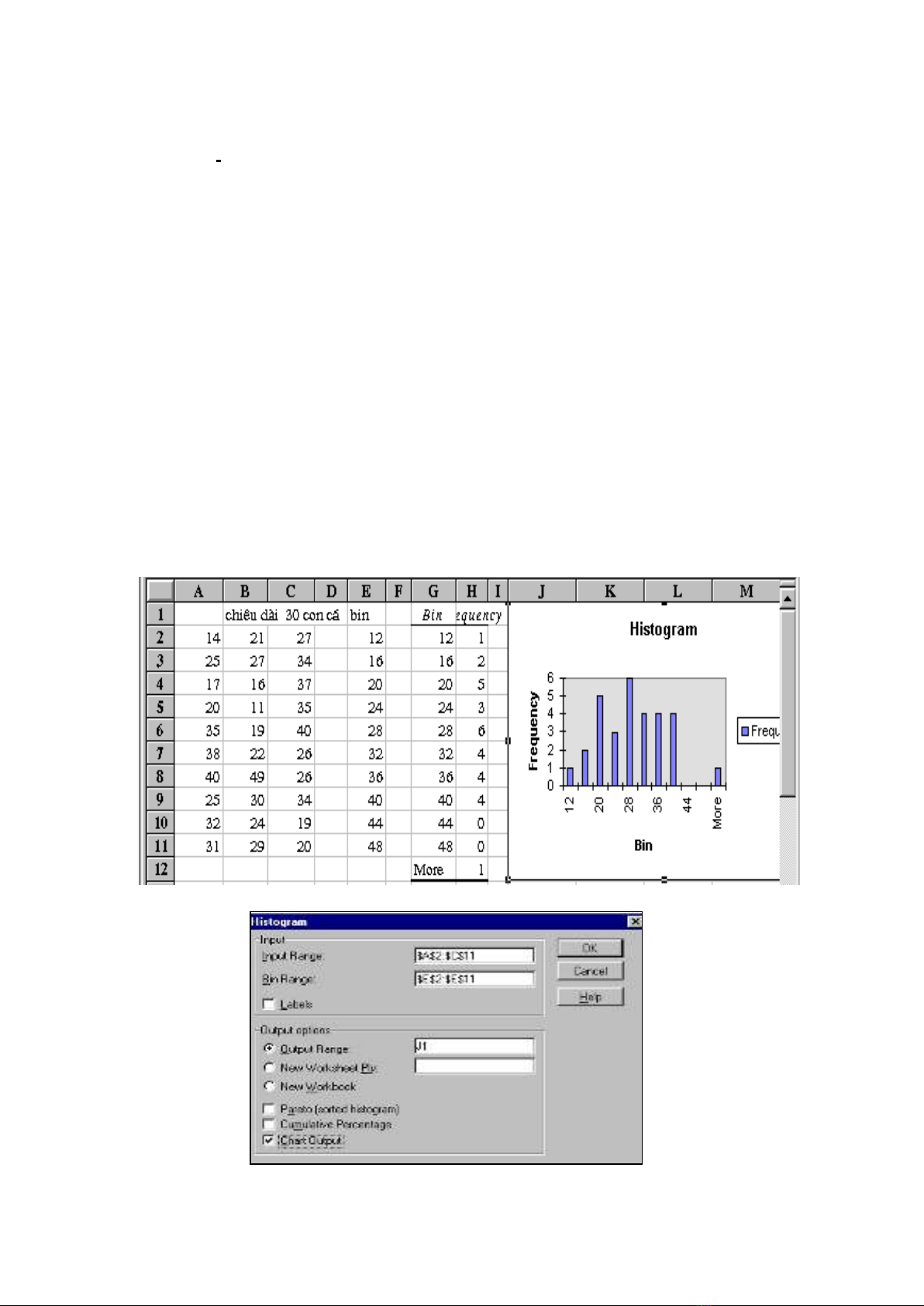
Thí dụ chiều dài 30 con cá
Max = 49 Min = 11 R = 38 n = 8 h = 38/5 quy tròn h =5
Tạo cột Bin Xuất phát gần Min thí dụ 12 tiếp theo lấy 12 + 5 = 17 17 + 5 = 22 . . .
Cho đến sát Max (49)
NDHien
Nếu muốn nhật đồ sắp xếp theo thứ tự tăng dần thì chọn Pareto, nếu muốn vẽ thêm
đường tần suất luỹ tích (cộng dồn) thì chọn cumulative percentage.
2/ Thống kê mô tả (Descriptive Statistics)
Khi có một bảng gồm nhiều cột, mỗi cột là một biến, tên biến đặt ở dòng đầu thì có thể
tính ngay tất cả các thống kê cho tất cả các biến bằng cách gọi thống kê mô tả (cũng có thể sắp
xếp các số liệu theo hàng, mỗi hàng là một biến).
Các công việc cần làm:
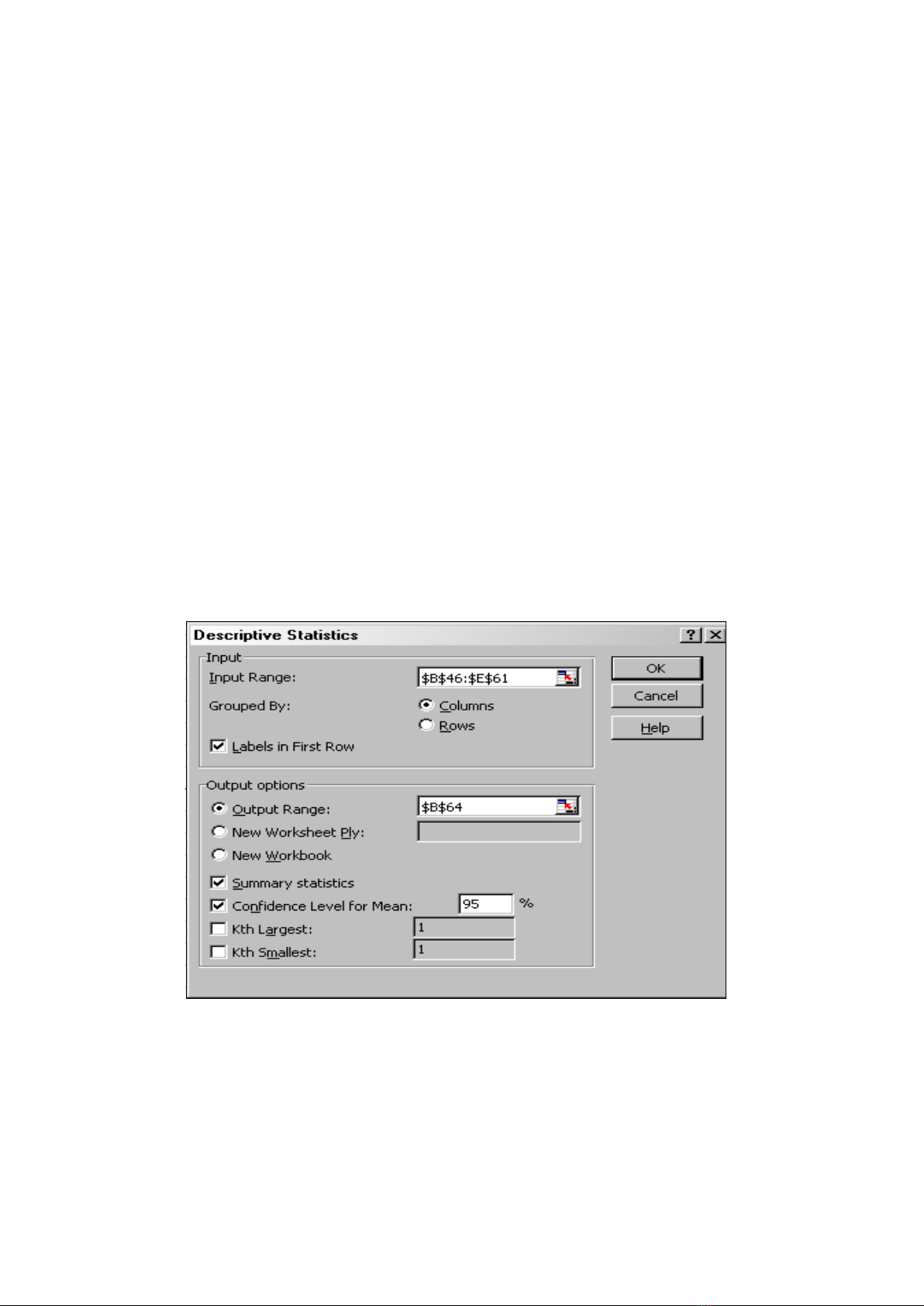
Chọn miền vào (Bảng gồm nhiều cột, mỗi cột là một biến, các biến không nhất thiết
phải dài bằng nhau, nhưng khi khai báo Input Range thì phải khai hình chữ nhật bao trùm toàn
bộ bảng).
Khai báo số liệu theo cột hay hàng.
Chọn nhãn (nháy vào ô Label) nếu tên biến đặt ở dòng đầu.
Chọn số to thứ mấy (k-Largest), nếu chọn 1 (mặc định) thì có số to nhất (Max), nếu
chọn 2 thì có số to thứ nhì v v. . .
Chọn số nhỏ thứ mấy (k- Smallest), nếu chọn 1 (mặc định) thì có số nhỏ nhất (Min), nếu
chọn 2 thì có số nhỏ thứ nhì v v . . .
Sau đó khai báo miền ra, quan trọng nhất là phải chọn ô Summary Statistics để có
được các thống kª.
Thí dụ ta có bảng gồm 4 biến số đặt ở A2..D17
Sau khi khai báo cho in kết quả ra F2
Mỗi cột biến bây giở sẽ ứng với 2 cột kết quả, cột đầu ghi tên các thống kê, cột sau ghi giá
trị của các thống kê, vì các cột tên giống nhau nên có thể để lại 1 cột còn xoá bớt, sau đó ghép
các cột giá trị lại sát nhau cho đẹp.
NDHien
X1
X2
X3
Y
X1
X2
X3
Y
52
40
81
5.5
Mean
45.33333
63.4
69.53333
10.93333
33
37
90
2.1
Standard Error
5.317238
6.137162
3.526588
1.69657
72
95
66
20.5
Median
46
62
70
10.3
15
58
40
9.6
Mode
#N/A
#N/A
#N/A
#N/A
40
20
75
1.7
Standard Deviation
20.59357
23.76913
13.65842
6.570787
32
41
80
3.8
Sample Variance
424.0952
564.9714
186.5524
43.17524
76
54
83
10.3
Kurtosis
-0.99416
-0.23096
0.616884
-0.23649
10
85
70
11.7
Skewness
-0.15496
0.116913
-0.81968
0.440507
68
70
65
15.2
Range
66
89
50
22.7
57
109
45
24.4
Minimum
10
20
40
1.7
24
62
64
9.3
Maximum
76
109
90
24.4
46
75
71
13
Sum
680
951
1043
164
35
55
82
6.5
Count
15
15
15
15
54
68
63
13.8
Confidence
Level(95.0%)
11.40435
13.16292
7.563786
3.638784
66
82
68
16.6
Mean - Giá trị trung bình (còn tên khác là Average) Standard error - Sai số của trung bình
Median - Trung vị Sample variance - phương sai mẫu
Kurtosis - Độ nhọn Skewness- Độ nghiêng (bất đối xứngb)
Range - Biên độ Minimum - Giá trị nhỏ nhất
Maximum - Giá trị lớn nhất Sum- Tổng (N/A là không xác định được)
Confidence Interval - Khoảng tin cậy Count - Số quan sát
Thí dụ chung
Mở tệp Baitap1.xls. Chọn biến Dobeo




















![Sổ tay Excel: Hướng dẫn sử dụng và mẹo hay [Năm hiện tại]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260520/vispacex_27/135x160/2851779253490.jpg)





%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23fff;%20}%20.st1%20{%20fill:%20%237800fa;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st1'%20d='M117.78,12.18H43.11c2.9,3.47,4.65,7.94,4.65,12.82,0,5.6-2.3,10.66-6.01,14.29h76.02l7.22-13.56-7.22-13.56Z'/%3e%3cg%3e%3cpath%20class='st0'%20d='M53.58,26.17h-.59v-1.46h.59v-4.96h2.83c1.78,0,2.67.94,2.67,2.82v5.76c0,1.87-.89,2.81-2.67,2.81h-2.83v-4.96ZM55.36,21.37v3.34h1.1v1.46h-1.1v3.34h1.01c.61,0,.91-.37.91-1.1v-5.93c0-.74-.3-1.1-.91-1.1h-1.01Z'/%3e%3cpath%20class='st0'%20d='M65.99,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM65.28,18.04c-.25.46-.51.77-.75.94-.21.15-.47.22-.79.22-.26,0-.57-.07-.92-.22l-.38-.15c-.14-.05-.26-.07-.37-.07-.3,0-.53.18-.71.54l-.91-.68c.25-.46.51-.77.75-.94.21-.14.48-.21.79-.21.26,0,.57.07.92.21l.38.15c.14.05.26.07.37.07.3,0,.53-.18.71-.54l.91.68ZM61.91,27.52h1.73l-.87-5.76-.87,5.76Z'/%3e%3cpath%20class='st0'%20d='M74.53,26.89v1.52c0,1.91-.89,2.86-2.67,2.86s-2.67-.95-2.67-2.86v-5.93c0-1.91.89-2.86,2.67-2.86s2.67.95,2.67,2.86v1.11h-1.69v-1.22c0-.75-.31-1.12-.93-1.12s-.93.37-.93,1.12v6.15c0,.74.31,1.11.93,1.11s.93-.37.93-1.11v-1.63h1.69Z'/%3e%3cpath%20class='st0'%20d='M81.4,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM75.9,19.2l1.52-1.91h1.71l1.51,1.91h-1.61l-.76-.95-.75.95h-1.61ZM77.32,27.52h1.73l-.87-5.76-.87,5.76ZM83.1,15.99l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M84.86,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM84.01,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M93.51,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM92.66,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M98.8,31.14h-1.79v-11.39h1.79v4.88h2.03v-4.88h1.83v11.39h-1.83v-4.88h-2.03v4.88Z'/%3e%3cpath%20class='st0'%20d='M105.36,24.55h2.46v1.62h-2.46v3.34h3.09v1.63h-4.88v-11.39h4.88v1.63h-3.09v3.18ZM108.17,17.29l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M112.2,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM111.35,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3c/g%3e%3ccircle%20class='st1'%20cx='25'%20cy='25'%20r='20'/%3e%3cpath%20class='st0'%20d='M32.78,19.27c2.92,0,4.43,2.55,5.28,5.33l.71,2.17c.14.38-.33.75-.71.75h-5.61c.19-.33.24-.71.09-1.08l-.75-2.45c-.43-1.32-.99-2.64-1.79-3.77.75-.57,1.65-.94,2.78-.94h0ZM25,18.38c3.25,0,4.9,2.78,5.89,5.89l.76,2.45c.14.42-.33.8-.8.8h-11.69c-.42,0-.94-.38-.8-.8l.75-2.45c.99-3.11,2.64-5.89,5.89-5.89h0ZM25,11.35c1.74,0,3.11,1.37,3.11,3.11s-1.37,3.11-3.11,3.11-3.11-1.41-3.11-3.11,1.41-3.11,3.11-3.11h0ZM17.27,19.27c1.08,0,1.98.38,2.73.94-.8,1.13-1.37,2.45-1.74,3.77l-.8,2.45c-.14.38-.05.75.09,1.08h-5.56c-.42,0-.9-.38-.75-.75l.71-2.17c.9-2.78,2.41-5.33,5.33-5.33h0ZM17.27,12.91c1.51,0,2.78,1.27,2.78,2.83s-1.27,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM32.78,12.91c1.56,0,2.78,1.27,2.78,2.83s-1.23,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM27.07,28.56v.09c0,.57-.24,1.08-.61,1.46h0v.05c-.38.33-.9.57-1.46.57s-1.08-.24-1.46-.61h0c-.38-.38-.61-.9-.61-1.46v-.09h1.41v.09c0,.19.05.38.19.47v.05c.09.09.28.19.47.19s.38-.09.47-.19v-.05c.14-.09.24-.28.24-.47t-.05-.09h1.41ZM30.99,28.56v.09c0,1.65-.66,3.16-1.74,4.24-1.08,1.08-2.59,1.79-4.24,1.79s-3.16-.71-4.24-1.79l-.05-.05c-1.04-1.08-1.7-2.55-1.7-4.2v-.09h1.41v.09c0,1.27.47,2.4,1.27,3.25h.05c.85.85,1.98,1.37,3.25,1.37s2.4-.52,3.25-1.37c.85-.8,1.37-1.98,1.37-3.25v-.09h1.37ZM34.99,28.56v.09c0,2.78-1.13,5.28-2.92,7.07-1.79,1.79-4.29,2.92-7.07,2.92s-5.23-1.13-7.07-2.92c-1.79-1.79-2.92-4.29-2.92-7.07v-.09h1.41v.09c0,2.4.94,4.53,2.5,6.08,1.56,1.56,3.72,2.5,6.08,2.5s4.52-.94,6.08-2.5c1.56-1.56,2.5-3.68,2.5-6.08v-.09h1.41Z'/%3e%3c/svg%3e)