
Hindawi Publishing Corporation
EURASIP Journal on Information Security
Volume 2011, Article ID 502782, 16 pages
doi:10.1155/2011/502782
Research Article
Hierarchical Spread Spectrum Fingerprinting Scheme
Based on the CDMA Technique
Minoru Kuribayashi (EURASIP Member)
Graduate School of Engineering, Kobe University, 1-1, Rokkodai, Nada, Kobe, Hyogo 657-8501, Japan
Correspondence should be addressed to Minoru Kuribayashi, kminoru@kobe-u.ac.jp
Received 10 March 2010; Revised 15 December 2010; Accepted 20 January 2011
Academic Editor: Jeffrey A. Bloom
Copyright © 2011 Minoru Kuribayashi. This is an open access article distributed under the Creative Commons Attribution
License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly
cited.
Digital fingerprinting is a method to insert user’s own ID into digital contents in order to identify illegal users who distribute
unauthorized copies. One of the serious problems in a fingerprinting system is the collusion attack such that several users combine
their copies of the same content to modify/delete the embedded fingerprints. In this paper, we propose a collusion-resistant
fingerprinting scheme based on the CDMA technique. Our fingerprint sequences are orthogonal sequences of DCT basic vectors
modulated by PN sequence. In order to increase the number of users, a hierarchical structure is produced by assigning a pair of
the fingerprint sequences to a user. Under the assumption that the frequency components of detected sequences modulated by
PN sequence follow Gaussian distribution, the design of thresholds and the weighting of parameters are studied to improve the
performance. The robustness against collusion attack and the computational costs required for the detection are estimated in our
simulation.
1. Introduction
Accompanying technology advancement, multimedia con-
tent (audio, image, video, etc.) has become easily available
and accessible. However, such an advantage also causes a
serious problem that unauthorized users can duplicate digital
content and redistribute it. In order to solve this problem,
digital fingerprinting is used to trace the illegal users, where
a unique ID known as a digital fingerprint [1] is embedded
into the content assisted by a watermarking technique before
distribution. When a suspicious copy is found, the owner can
identify illegal users by extracting the fingerprint.
Since each user purchases contents involving his own
fingerprint, the fingerprinted copy slightly differs with
each other. Therefore, a coalition of users can combine
their different marked copies of the same content for the
purpose of removing/changing the original fingerprint. In
a fingerprinting system, a usual assumption is that the
colluders add white Gaussian noise to a forgery which they
create by combining (averaging) their copies in a linear
or nonlinear fashion [2–5]. Under the assumption of a
fixed correlation detector, it is reported that the uniform
linear averaging strategy is the most damaging one [6].
It is important to generate fingerprints that can identify
the colluders. A number of works on designing collusion-
resistant fingerprints have been proposed. Many of them
can be categorized into two approaches. One approach is
to exploit the spread spectrum (SS) technique [2–5], and
the other approach is to devise an exclusive code, known as
collusion-secure code [7–12], which can trace colluders.
In the former approach, spread spectrum sequences,
which follow a normal distribution, are assigned to users as
fingerprints. The origin of the spread spectrum watermark-
ing scheme is Cox’s method [2] that embeds a sequence into
the frequency components of a digital image and detects
it using a correlator. In this work, the fingerprinting is
introduced as a possible application of the spread spectrum
watermarking. Because of the quasi-orthogonality among
spread spectrum sequence used in the paper, the identifi-
cation of users from an illegal copy is possible. Hereafter,
we use the term “fingerprinting” as the application of the
watermarking scheme. Since normally distributed values
allow the theoretical and statistical analysis of the method,
modeling of a variety of attacks has been studied. Studies

2EURASIP Journal on Information Security
in [3] have shown that a number of nonlinear collusions
such as an interleaving attack can be well approximated by
averaging collusion plus additive noise. So far, many variants
of the spread spectrum fingerprinting schemes based on
Cox’s method have been proposed, particularly for using
a sequence whose elements are randomly selected from
normally distributed values.
There is a common disadvantage that high computa-
tional resources are required for the detection because the
correlation values with all spread spectrum sequences are
calculated at the detection. When the number of users
is increased, that of spread spectrum sequences is also
increased, hence the computational cost is linearly increased.
Wang et al . [ 4] presented the idea of group-oriented
fingerprinting system and proposed by a tree-structured
scheme. At the detection, firstly the groups to which colluders
belong are detected, and then only suspicious users within
the detected groups are checked if they are guilty or not.
The limitation of the number of innocent users placed under
suspicion reduces the computational costs by a factor of log
scale. The idea is based on the observation that the users
who have similar background and region are more likely
to collude with each other. Their motivation is to exploit
such a prior knowledge to assign specific fingerprints in
order to classify their groups in the system. The fingerprints
assigned to members of different groups that are unlikely to
collude with each other are statistically independent, while
the fingerprints assigned to members within a group of
potential colludes are correlated. Therefore, the reduction of
computational costs are merely the optional side effect. In
addition, since the prior knowledge is not always available,
the generation of fingerprints is not suitable from this point
of view.
In this paper, we focus on the spread spectrum finger-
printing and propose a new fingerprinting scheme based
on the CDMA technique. Our spread spectrum sequences
are theoretically quasi-orthogonal because they are DCT
basic vectors modulated by PN (pseudo noise) sequence
such as M-sequence and Gold-sequence [13], and so forth,
while those of Cox’s method are random sequences. The PN
sequence is a pseudorandom sequence of 1 and −1values,
and is designed to retain quasi-orthogonality. Using the
quasi-orthogonality, it is possible to assign the combination
of spectrum components to each user and to provide the
hierarchical structure using two kinds of the sequences;
one is for group ID and the other for user ID. In order
to uniquely classify each user, we introduce a dependency
between the sequences by selecting a specific PN sequence
for the sequence of user ID using group ID. It specifies
the detection procedure because the detection of user ID
requires the corresponding group ID. Therefore, if we fail
to detect the group ID at the first detection, the following
procedure to detect user ID is not conducted. If no user
ID is detected from a pirated copy, it results in the false-
negative detection. By applying the statistical property, we
calculate proper thresholds according to the probability
of false-positive detection. Considering the characteristics
of the detection, we study the parameters used in the
procedure of embedding and detection, and assign weights
to the parameters. We demonstrate the performance of
the proposed scheme through computer simulation. From
the results, it is confirmed that the proposed scheme
rationally reduces the computational complexity because of
the introduction of hierarchical structure for fingerprinting
sequences and the specific designed of quasi-orthogonal
sequences that allows us to perform fast algorithm at the
detection. Furthermore, using properly selected parameters
derived from our experiments, the proposed scheme retains
high robustness against averaging collusion.
It will be required for a fingerprinting system to reveal its
algorithm because no standard tool is black box. In such a
situation, the security parameter is a secret key managed by
the author or his agent. Users only get a fingerprinted copy of
contents. Even if some of them collude to produce a pirated
version of the copy, it is necessary that no information about
the key is leaked from their fingerprinted copies. Assuming
that the embedding and detection algorithms are revealed to
colluders, the robustness against collusion attack is discussed,
and is evaluated by experiments. In the previous works [4,
5,14], the robustness is evaluated by measuring the number
of the colluders detected from the attacked image that is
produced by collusion attack and is further distorted by other
attacks such as addition of noise and lossy compression.
The addition of noise and lossy compression distort the
whole attacked image, not only the components in which
a fingerprint is embedded. Thus, the fingerprint-to-noise
ratio has been measured in a spatial domain even if the
fingerprint is embedded in a frequency domain. When the
algorithms are revealed, it is possible for colluders to add a
noise only to those components. In this paper, we evaluate
the robustness when colluders add a Gaussian noise only to
those components by changing the fingerprint-to-noise ratio
that is measured only from the fingerprinted components.
From the experimental results, the proposed method retains
a considerable tolerance against addition of noise for the
image attacked by averaging.
This paper is organized as follows. Section 2 reviews
related works and reports the drawbacks and problems.
Section 3 describes the basic idea and approach of our
proposed scheme, and Section 4 presents the procedure
of embedding and detection introducing a hierarchical
structure. Section 5 discusses the parameters in the pro-
cedure and presents the weighting parameters considering
the characteristic of the proposed scheme. In Section 6,
computer-simulated results are provided. Finally, Section 7
concludes the paper.
2. Related Works
In this section, we briefly review conventional collusion-
resistant fingerprinting schemes based on the spread spec-
trum fingerprinting.
2.1. Spread Spectrum Fingerprinting. Many fingerprinting
techniques have been recently proposed considering the
robustness against collusion attacks. Cox et al. [2]proposed
the first fingerprinting scheme based on the SS technique.

EURASIP Journal on Information Security 3
In their scheme, a unique SS sequence wof real numbers is
assigned to each user as a fingerprint: w={w0,...,wℓ−1},
where each element wiis randomly generated by an inde-
pendently identically distributed source like N(0, 1) (where
N(µ,σ2) denotes a normal distribution with mean µand
variance σ2).
Let v={v0,...,vℓ−1}be the frequency components of a
digitalimage.Weinsertwinto vto obtain a fingerprinted
sequence v∗,forexample,v∗
i=vi(1 + αwi), where αis
the embedding strength. At the detector side, we determine
which SS sequence is present in a pirated copy by evaluating
the similarity of sequences. From the pirated copy, a sequence
wis detected by calculating the difference from the original
one, and its similarity with wis obtained as follows:
sim(w,w)=w·w
√w·w,(1)
If the value exceeds a threshold, the embedded sequence is
regarded as w.
In a fingerprinting scheme, each fingerprinted copy is
slightly different; hence, malicious users can collect ccopies
D1,...,Dcwith respective fingerprints w1,...,wcin order to
remove/alter the fingerprints. A simple, yet effective way is to
average them because when ccopies are averaged,
D=(D1+
···+Dc)/c, the similarity value calculated by (1) is reduced
by a factor of c, which can be roughly √ℓ/c [2]. Even in this
case, we can detect the embedded fingerprint and identify
the colluders by an appropriately designed threshold if the
number of colluders is small. Wang et al. [4]investigated
the error performance of pseudonoise (PN) sequences using
maximum and threshold detectors and proposed a method
to estimate the number of colluders.
The Cox’s method has excellent robustness against signal
processing, geometric distortions, subterfuge attacks, and
so forth [2]. However, the (quasi-)orthogonality of the
fingerprinting sequences is not theoretically assured. It is
well known that the cross-correlation between sequences
statistically decreases with an increase in the sequence
length. On the basis of this characteristic, conventional
fingerprinting schemes using the spread spectrum technique
provide quasi-orthogonality; hence it is probabilistic. Some
of the sequences might be mutually correlated. From the
viewpoint of robustness against attacks, it is desirable to
use real (quasi-)orthogonal sequences as a fingerprint. In
addition, this technique has a weakness that the required
number of SS sequences and the computational complexity
forthedetectionisincreasedlinearlywiththenumberof
users. A numerical example is shown in Figure 1 by changing
the number of users Nu, under the following environment.
The time consumption at the detection is evaluated on a
computer having an Intel Core2Duo E6700 CPU and 8-GB
RAM for Cox’s method with length of sequence ℓ=1024.
Since the detector of Cox’s method checks all candidates of
a fingerprint sequence, the time consumption is constant. It
is observed that the computing time for detecting colluders
is almost linearly increased with the number of users in a
fingerprinting system.
302520151050
Number of colluders
0.1
1
10
100
1000
Computing time (s)
Cox (Nu=106)
Cox (Nu=105)
Cox (Nu=104)
Figure 1: Time consumption in the detection of colluders for Cox’s
scheme [sec].
2.2. Grouping. There is a common disadvantage in Cox’s
scheme and its variants such that high computational
resources are required for the detection because the correla-
tion values of all spread spectrum sequences must be calcu-
lated. For the reduction of computational costs, hierarchical
spread spectrum fingerprinting schemes have been proposed.
The motivation of the scheme proposed by Wang et al. [5]is
to divide a set of users into different subset and assign each
subset to a specific group whose members are more likely
to collude with each other than with members from other
groups. With the assumption that the users in the same group
are equally likely to collude with each other, the fingerprints
in one group have equal correlation. At the detection, the
independency among groups limits the amount of innocent
users falsely placed under suspicion within a group, because
the probability of accusing another group is very large.
Suppose that each group can accommodate up to Musers.
The fingerprint sequence wi,jassigned to jth user within ith
group consists of two components:
wi,j=1−ρei,j+ρai,(2)
where {ei,1,ei,2,...,ei,M,ai}are the orthogonal basis vectors
of group iwith equal energy and ρis called intragroup
correlation. Due to the common vector ai, when colluders
from the same group average their copies, the energy of the
vector is not attenuated, and hence, the detector can accu-
rately identify the group. The detection algorithm consists
of two stages; one is the identification of groups involving
colluders and the other involves identifying colluders within
each suspicious group.
The idea of grouping was also applied in the finger-
printing code proposed by Lin et al. [15]. The difference of
approach is the model of attack. Generally, the performance
of fingerprinting codes is evaluated under the marking
assumption [7]. In the study of fingerprinting schemes based
on the spread spectrum fingerprinting, the attack is modeled
by averaging plus additive noise and the schemes involve the
embedding of fingerprint signal.
4EURASIP Journal on Information Security
3. Proposed Fingerprint Sequence
3.1. Fingerprint Sequence. Code division multiple access
(CDMA) is a form of multiplexing and a method of multiple
access to a physical medium such as a radio channel, where
each user of the medium has a different PN sequence.
Different from the sequence explained in Section 2.1,a
PN sequence which is a pseudorandom sequence of 1
and −1 values is mathematically designed to retain quasi-
orthogonality. Examples of such a sequence are an M-
sequence, Gold-sequence, and so forth [13].
One of the simple methods for fingerprinting is to assign
a unique PN sequence to each user as a fingerprint. However,
at the detection, we have to check all sequences by calculating
their correlations, which is the same problem that in the
case of spread spectrum fingerprinting. Instead, orthogonal
sequences are exploited as input signals using a well-
known orthogonal transform such as DFT and DCT before
modulating them by a PN sequence. If only orthogonal
sequences are used, the number of sequences is just equal to
the length of sequence. For the increase of the number, the
modulation by a PN sequence is employed. Thus, the spread
sequences modulated by a PN sequence do not seriously
influence each other, and the use of a fast algorithm for
calculating the orthogonal transform enables us to reduce
the computational costs. Considering such a property in our
scheme, we allocate one of the spectrum components to the
corresponding fingerprint information.
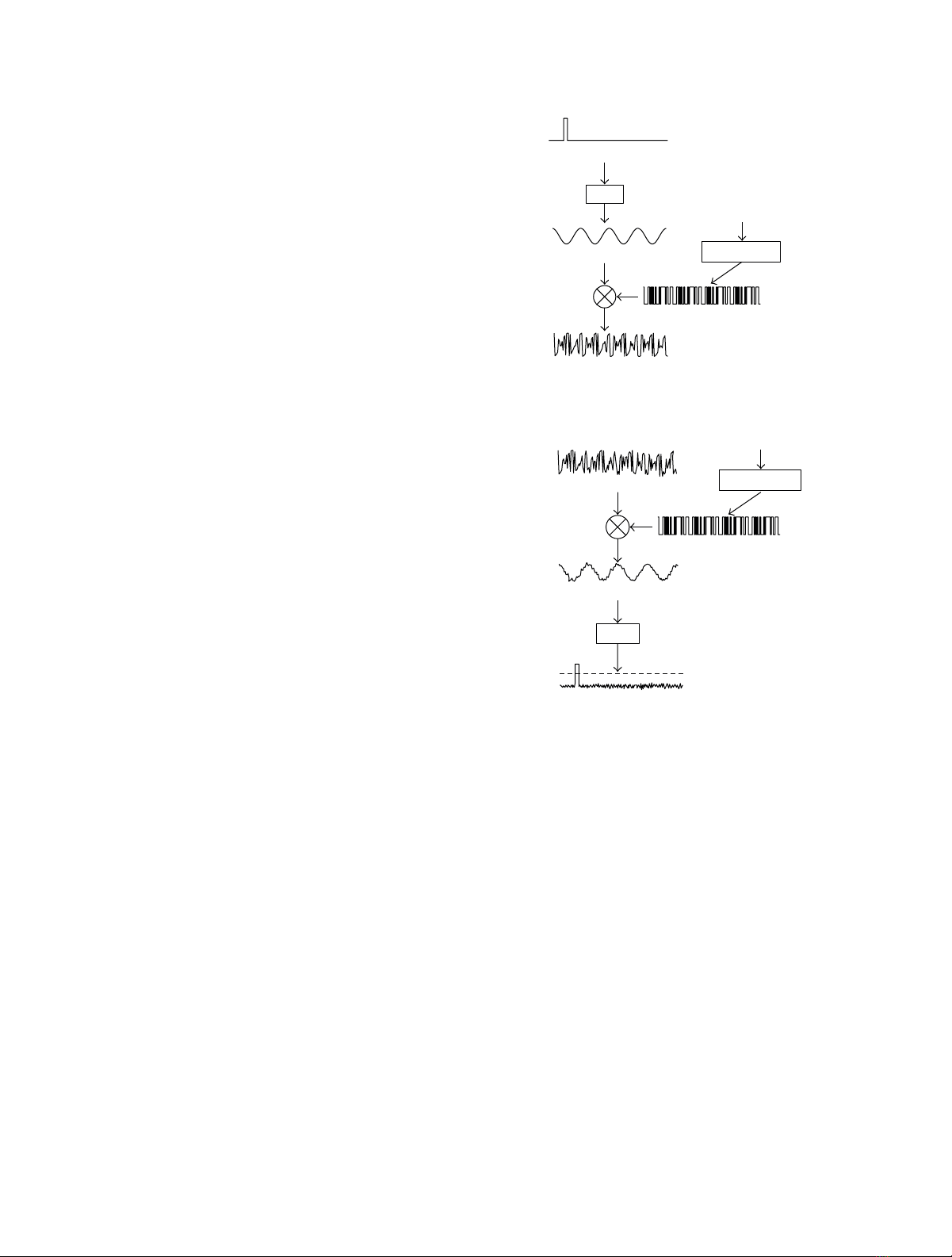
Let d={d0,...,dℓ−1}be a sequence constructed from
DCT coefficients and be initialized to the zero vector. We
assume that the ith element diis assigned to the ith user
as a fingerprint. At the time of embedding, the embedding
strength βis added only to an ith coefficient di=β;the
values of the other DCT coefficients are 0. After performing
IDCT on the sequence, it is multiplied by a PN sequence
to generate a specific spread spectrum sequence. Then,
the spread spectrum sequence assigned to the ith user is
represented by
wi=pn(s)⊗dcti,β,(3)
where pn(s) is a PN sequence generated using an initial
value s,dct(i,β)istheith DCT basic vector of an ℓ-tuple
of strength β,and⊗implies elementwise multiplication. An
illustration of our spread spectrum sequence is shown in
Figure 2.Thesequencewiis embedded into the frequency
components of a digital image.
The sequence obtained by subtracting the host sequence
from the sequence of a pirated copy is denoted by wi.Atthe
detection, instead of a similarity measurement, we multiply
each element of wiby the corresponding element of the PN
sequence pn(s) and perform DCT in order to obtain the
sequence
d={
d0,...,
dℓ−1}
d=FDCTpn(s)⊗wi,(4)
where FDCT denotes a fast discrete cosine transform algo-
rithm. Illegal users can be determined if the corresponding
coefficients exceed a threshold T. The procedure to detect the
embedded fingerprint information is depicted in Figure 3.If
Fingerprint information
id
IDCT
dct(i,β)
wi
Secret key s
PN generator
pn(s)
Spread spectrum sequence
Figure 2: Generation of the spread spectrum sequence.
i
d
FDCT
pn(s)wi
wi
Secret key s
PN generator
pn(s)
Detection sequence
Threshold T
Figure 3: Detection of the fingerprint information.
a pirated copy is composed of ccolluders’ ones, cspikes can
be detected by the detector.
The advantage of the above detection method is its
lower computational complexity because FDCT requires
O(ℓlog ℓ) multiplications [16] and the multiplication by the
PN sequence requires O(ℓ) operations. Therefore, the total
computational complexity is much lower than that of Cox’s
method because the similarity function given in (1)requires
O(ℓ2) operations for ℓusers.
3.2. Design of Threshold. In conventional fingerprinting
schemes [2,3], illegal users are detected by calculating the
correlations with the original fingerprint. If the original data
is available, the reliability of the detector can be increased.
Here, it is strongly required for the detector to detect only
illegal users, and not innocent ones. Therefore, the design
of a threshold is inevitable to guarantee low probability
of false-positive detection. In this subsection, we exploit
statistical properties to obtain the proper threshold for a
given probability of false-positive detection.
The sequence obtained by subtracting the host sequence
from the sequence of a pirated copy is denoted by w,and
EURASIP Journal on Information Security 5
the DCT coefficients of the sequence modulated by the
PN sequence pn(s)aredenotedby
d={
d0,...,
dℓ−1}.
Remember that our fingerprint sequence is a DCT basic
vector modulated by a PN sequence. So, a base conversion
is performed to a set of PN sequences to generate new
spread spectrum sequences. For convenience, the sequence
dis called a detection sequence. The quasi-orthogonality of
our sequence is based on that of original PN sequence. In
the spread spectrum communication, the energy of a signal is
spread over a much wider band, and it resembles white noise.
Except for the synchronized signal, namely, an embedded
fingerprint, the other ones also resembles white noise. Hence,
the noise introduced by attacks may behave like a white
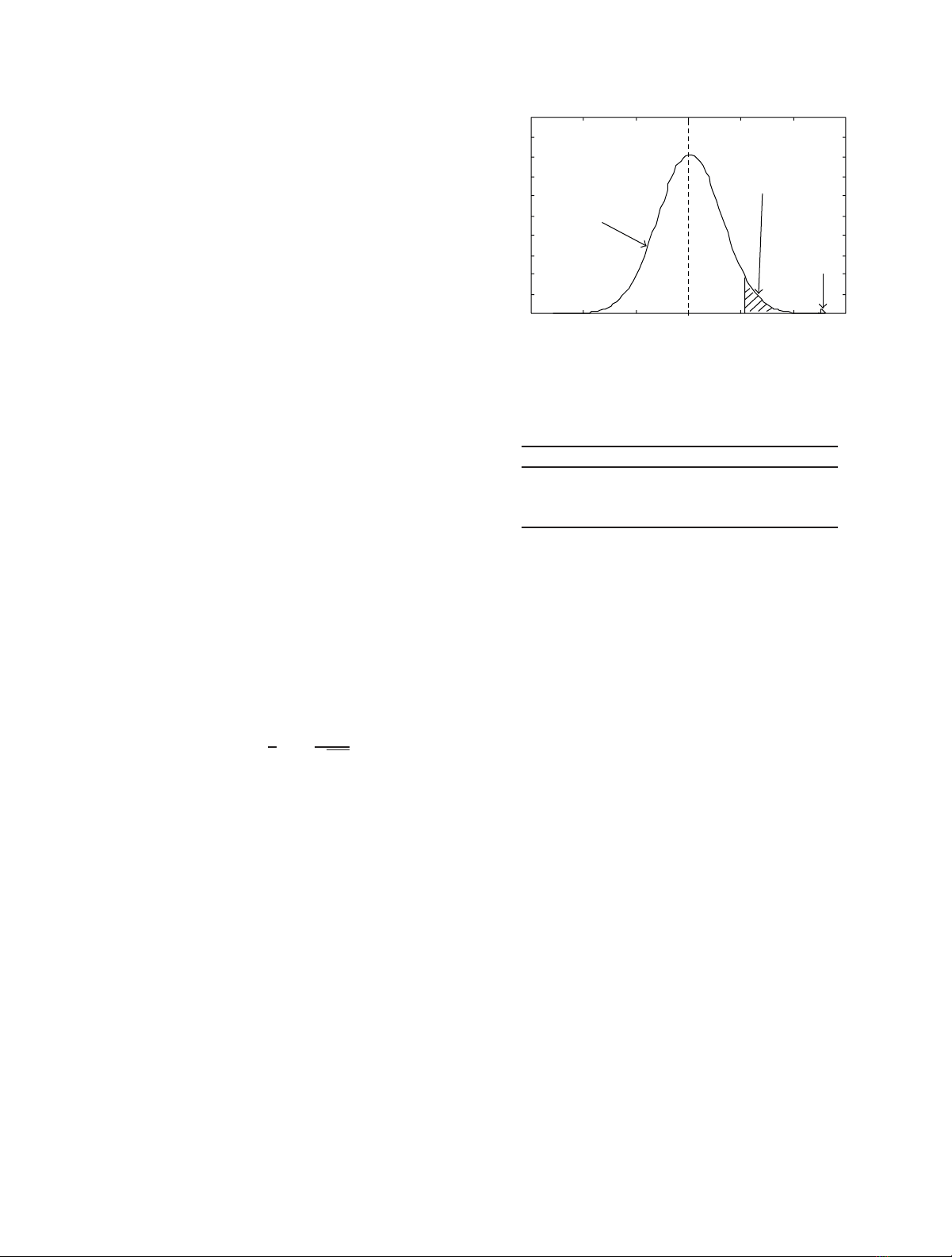
Gaussian injected in the sequence. From the preliminary
experiment shown in Figure 4, the distribution of
dcan be
modeled by a Gaussian distribution.
Suppose that the distribution of
dis N(0, σ2)exceptfor
a fingerprinted component
dk. If we insert a fingerprint by
adding a strength βto dkin order to satisfy the inequality
dk>max
i/
=k
di.(5)
We can detect the embedded fingerprint by setting a
threshold Tto be imposed:
dk>T>
di.Then,Tcan
be calculated according to the probability of false detection,
which is illustrated in Figure 4. The probability that a
random variable dkexceeds T,Pr(
di>T), is equal to the
marked area in Figure 4.If
di>T, the detector decides
that
diis fingerprinted; hence, it detects an innocent user
by mistake. Therefore, Pr(
di>T) is the probability of false-
positive detection. Then, we can say that
Pr
di>T
≤1
2erfcT
√2σ2,(6)
from the study in [17], where erfc(·) stands for the comple-
mentary error function.
Theknowledgeofthevarianceσ2enables a fingerprint
detector to obtain a proper threshold corresponding to a
given probability of false detection. The estimation of the
variance σ2is discussed in Section 5.1.
4. Hierarchical Scheme
4.1. Hierarchical Structure. In our technique, we assume that
each user’s fingerprint information consists of two parts:
“group ID” that identifies the group to which a user belongs,
and “user ID” that represents an individual user within the
group.
A fingerprint sequence is produced from one of the
DCT coefficients and a PN sequence in order to make
the fingerprint sequences quasi-orthogonal to each other.
However, in such a case the allowable number of users
is equal to the number of spectrum components. One
simple approach to increase the number of users is to use
two sequences, one for group ID and the other for user
ID. We assume that dg={dg,0,...,dg,ℓ−1}and du=
T0
Detection statics
d
P(
di>T)
dk
Frequency distributions
Figure 4: Distribution of
dis approximated to N(0, σ2).
Table 1: Example of assigned fingerprint to 9 users.
dg,0 dg,1 dg,2
du,0 user 1 user 4 user 7
du,1 user 2 user 5 user 8
du,2 user 3 user 6 user 9
{du,0,...,du,ℓ−1}are the vectors for group ID and user
ID, respectively. In this case, ℓ2users can be allowed with
2ℓspectrum components because the combination of two
components has ℓ2candidates. However, under averaging
collusion, it causes a serious problem that the combination
of two components cannot be identified uniquely even if
the embedded signals are correctly detected from a pirated
copy. For example, we assign two components to each user
to represent fingerprint information, as shown in Tab le 1 .
If user 1 and user 6 collude to average two fingerprinted
contents, then two components,
dg,0 and
dg,1,canbedetected
from
dg; similarly, two components,
du,0 and
du,2,canbe
detected from the other sequence
du. Here, even if we can
detect such fingerprinted components, we cannot identify
the users uniquely since there are two cases for the collusion
of two users: user 1 and user 6, or user 3 and user 4. Such a
problem occurs even if the number of sequences is increased.
In order to solve this problem, conventional schemes [9,
11] exploited the error correcting codes with large minimum
distance to maintain collusion resistance. Different from
such an approach, we introduce dependency between the
spread spectrum sequences wigand wiugenerated from two
sequences dgand du, by exploiting the property of quasi-
orthogonality of PN sequences. Before embedding a user ID,
its corresponding DCT basic vector is multiplied by a specific
PN sequence related to the group ID. Thus, for fingerprint
information (ig,iu), two spread spectrum sequences related
to dgand duwith strengths βgand βuare given by
wig=pn(s)⊗dctig,βg,(7)
wiu=pnig⊗dctiu,βu,(8)





![Thuyết minh tính toán kết cấu đồ án Bê tông cốt thép 1: [Mô tả/Hướng dẫn/Chi tiết]](https://cdn.tailieu.vn/images/document/thumbnail/2016/20160531/quoccuong1992/135x160/1628195322.jpg)




















%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23fff;%20}%20.st1%20{%20fill:%20%237800fa;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st1'%20d='M117.78,12.18H43.11c2.9,3.47,4.65,7.94,4.65,12.82,0,5.6-2.3,10.66-6.01,14.29h76.02l7.22-13.56-7.22-13.56Z'/%3e%3cg%3e%3cpath%20class='st0'%20d='M53.58,26.17h-.59v-1.46h.59v-4.96h2.83c1.78,0,2.67.94,2.67,2.82v5.76c0,1.87-.89,2.81-2.67,2.81h-2.83v-4.96ZM55.36,21.37v3.34h1.1v1.46h-1.1v3.34h1.01c.61,0,.91-.37.91-1.1v-5.93c0-.74-.3-1.1-.91-1.1h-1.01Z'/%3e%3cpath%20class='st0'%20d='M65.99,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM65.28,18.04c-.25.46-.51.77-.75.94-.21.15-.47.22-.79.22-.26,0-.57-.07-.92-.22l-.38-.15c-.14-.05-.26-.07-.37-.07-.3,0-.53.18-.71.54l-.91-.68c.25-.46.51-.77.75-.94.21-.14.48-.21.79-.21.26,0,.57.07.92.21l.38.15c.14.05.26.07.37.07.3,0,.53-.18.71-.54l.91.68ZM61.91,27.52h1.73l-.87-5.76-.87,5.76Z'/%3e%3cpath%20class='st0'%20d='M74.53,26.89v1.52c0,1.91-.89,2.86-2.67,2.86s-2.67-.95-2.67-2.86v-5.93c0-1.91.89-2.86,2.67-2.86s2.67.95,2.67,2.86v1.11h-1.69v-1.22c0-.75-.31-1.12-.93-1.12s-.93.37-.93,1.12v6.15c0,.74.31,1.11.93,1.11s.93-.37.93-1.11v-1.63h1.69Z'/%3e%3cpath%20class='st0'%20d='M81.4,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM75.9,19.2l1.52-1.91h1.71l1.51,1.91h-1.61l-.76-.95-.75.95h-1.61ZM77.32,27.52h1.73l-.87-5.76-.87,5.76ZM83.1,15.99l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M84.86,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM84.01,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M93.51,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM92.66,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M98.8,31.14h-1.79v-11.39h1.79v4.88h2.03v-4.88h1.83v11.39h-1.83v-4.88h-2.03v4.88Z'/%3e%3cpath%20class='st0'%20d='M105.36,24.55h2.46v1.62h-2.46v3.34h3.09v1.63h-4.88v-11.39h4.88v1.63h-3.09v3.18ZM108.17,17.29l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M112.2,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM111.35,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3c/g%3e%3ccircle%20class='st1'%20cx='25'%20cy='25'%20r='20'/%3e%3cpath%20class='st0'%20d='M32.78,19.27c2.92,0,4.43,2.55,5.28,5.33l.71,2.17c.14.38-.33.75-.71.75h-5.61c.19-.33.24-.71.09-1.08l-.75-2.45c-.43-1.32-.99-2.64-1.79-3.77.75-.57,1.65-.94,2.78-.94h0ZM25,18.38c3.25,0,4.9,2.78,5.89,5.89l.76,2.45c.14.42-.33.8-.8.8h-11.69c-.42,0-.94-.38-.8-.8l.75-2.45c.99-3.11,2.64-5.89,5.89-5.89h0ZM25,11.35c1.74,0,3.11,1.37,3.11,3.11s-1.37,3.11-3.11,3.11-3.11-1.41-3.11-3.11,1.41-3.11,3.11-3.11h0ZM17.27,19.27c1.08,0,1.98.38,2.73.94-.8,1.13-1.37,2.45-1.74,3.77l-.8,2.45c-.14.38-.05.75.09,1.08h-5.56c-.42,0-.9-.38-.75-.75l.71-2.17c.9-2.78,2.41-5.33,5.33-5.33h0ZM17.27,12.91c1.51,0,2.78,1.27,2.78,2.83s-1.27,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM32.78,12.91c1.56,0,2.78,1.27,2.78,2.83s-1.23,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM27.07,28.56v.09c0,.57-.24,1.08-.61,1.46h0v.05c-.38.33-.9.57-1.46.57s-1.08-.24-1.46-.61h0c-.38-.38-.61-.9-.61-1.46v-.09h1.41v.09c0,.19.05.38.19.47v.05c.09.09.28.19.47.19s.38-.09.47-.19v-.05c.14-.09.24-.28.24-.47t-.05-.09h1.41ZM30.99,28.56v.09c0,1.65-.66,3.16-1.74,4.24-1.08,1.08-2.59,1.79-4.24,1.79s-3.16-.71-4.24-1.79l-.05-.05c-1.04-1.08-1.7-2.55-1.7-4.2v-.09h1.41v.09c0,1.27.47,2.4,1.27,3.25h.05c.85.85,1.98,1.37,3.25,1.37s2.4-.52,3.25-1.37c.85-.8,1.37-1.98,1.37-3.25v-.09h1.37ZM34.99,28.56v.09c0,2.78-1.13,5.28-2.92,7.07-1.79,1.79-4.29,2.92-7.07,2.92s-5.23-1.13-7.07-2.92c-1.79-1.79-2.92-4.29-2.92-7.07v-.09h1.41v.09c0,2.4.94,4.53,2.5,6.08,1.56,1.56,3.72,2.5,6.08,2.5s4.52-.94,6.08-2.5c1.56-1.56,2.5-3.68,2.5-6.08v-.09h1.41Z'/%3e%3c/svg%3e)