
Tìm kiếm toàn văn trong MySQL
Khi dữ liệu ngày càng nhiều thì vấn đề tìm kiếm thông tin chính xác
càng trở nên quan trọng. Với khối lượng dữ liệu lớn và có tổ chức
phức tạp, vấn đề đặt ra là làm thế nào để tìm nhanh và đúng thông tin
cần. Người dùng không muốn tìm kiếm một từ mà lại có cả triệu câu
trả lời, họ cần sự chính xác và loại bỏ các từ gây nhiễu. Lúc đó, người
dùng sẽ cần đến tính năng tìm kiếm toàn văn.
Tìm kiếm toàn văn (TKTV) đã được hỗ trợ trong MySQL version
3.23.23. Các cột VARCHAR và TEXT được đánh chỉ mục với FULLTEXT có thể dùng được
với các câu lệnh SQL đặc biệt để thực hiện việc tìm kiếm toàn văn trong MySQL. Đến bản 4.1,
tính năng này trở nên hoàn thiện với sự hỗ trợ đầy đủ tìm kiếm boolean.
Tìm kiếm toàn văn trong MySQL
TKTV là một chức năng có trong MySQL cho phép người dùng tìm kiếm các mẩu thông tin
khớp với một chuỗi trên một hay một số bảng nhất định, hơn là tìm sự so khớp dạng "SELECT
LIKE" trên từng hàng của một trường nào đó.
Một chỉ mục toàn văn trong MySQL là một chỉ mục có kiểu FULLTEXT. Các chỉ mục
FULLTEXT chỉ được dùng với các bảng MyISAM và có thể được tạo ra từ các cột CHAR,
VARCHAR, hay TEXT vào lúc tạo bảng với CREATE TABLE hay bổ sung sau với ALTER
TABLE hoặc CREATE INDEX.
Chỉ mục TKTV rất giống với các chỉ mục khác: nó là một danh sách các khóa được xếp theo trật
tự. Các khóa này chỉ đến các bản ghi nằm trong file dữ liệu. Mỗi khóa gồm (định dạng của phiên
bản 4.1):
{
Word -- VARCHAR. Một từ bên trong phần văn bản.
Count -- LONG. Từ đó xuất hiện bao nhiều lần trong phần văn bản.
}
{
Weight -- FLOAT. Đánh giá về tầm quan trọng của từ.
Rowid -- một con trỏ chỉ đến hàng cụ thể nằm trong file dữ liệu.
}
Một số đặc điểm chính của tính năng TKTV trong MySQL:
• Tự loại bỏ các từ có ít hơn 4 chữ cái.
• Các từ có gạch ngang nằm giữa được xem là 2 từ.
• Các hàng được trả lại theo thứ tự thích hợp, từ cao xuống thấp
• Các từ nằm trong danh sách từ phổ thông bằng tiếng Anh cũng bị loại bỏ khỏi danh sách kết
quả tìm kiếm. Danh sách từ này nằm trong file myisam/ft_static.c. Khi bạn cần lọc các từ thông
dụng cho một ngôn ngữ khác, ví dụ tiếng Việt thì bạn cần chỉnh lại file này, biên dịch lại
MySQL, và xây dựng lại các chỉ mục!
Chuẩn bị dữ liệu
Chúng ta thử triển khai một ví dụ đơn giản để hình dung rõ hơn về cơ chế hoạt động của TKTV.
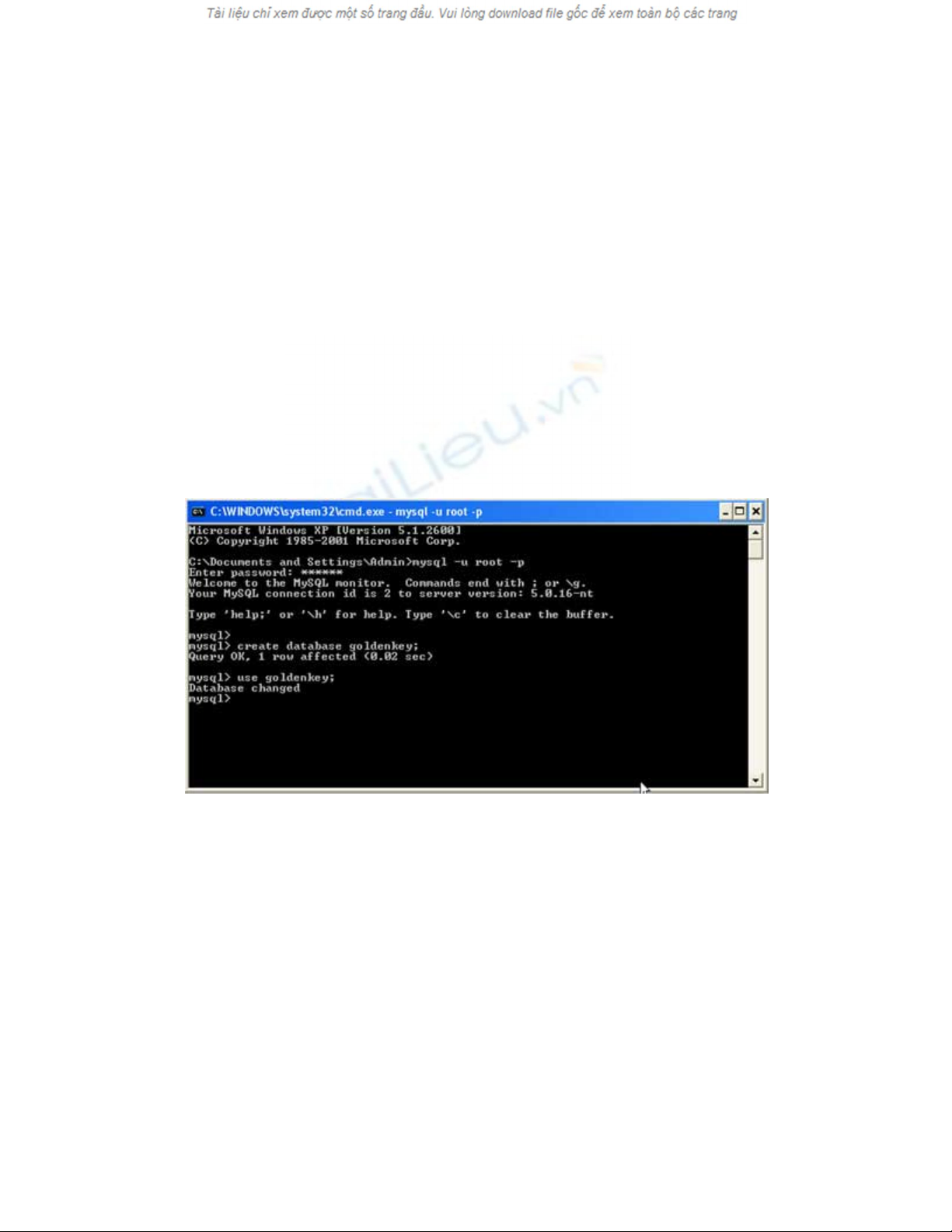
Đầu tiên, chúng ta tạo ra một CSDL tên goldenkey từ cửa sổ dòng lệnh (console) của MySQL:
Tiếp theo, chúng ta tạo ra một bảng dùng mệnh đề FULLTEXT của MySQL để chỉ định những
trường mà chúng ta muốn đánh chỉ mục cho việc tìm kiếm:
create table Staff
(
pk_id int auto_increment not null,
firstName varchar(20),
lastName varchar(20),
age int,
details text,
primary key(pk_id),
unique id(pk_id),
fulltext(firstName, lastName, details)
) ENGINE=MyISAM;
Sau khi thực hiện câu lệnh này, bạn được một bảng có cấu trúc như sau:
Trường pk_id đầu tiên được dùng làm khóa chính. Chúng ta đã dùng mệnh đề FULLTEXT để
đánh chỉ mục cho nhóm 3 trường là firstName, lastName và details.
Nếu đã lập bảng như trên và muốn thay đổi trường có chỉ mục, bạn dùng lệnh sau:
ALTER TABLE Staff ADD FULLTEXT(field1, field2);
Ở đây, bạn chú ý dòng fulltext(firstName, lastName, details). Dòng này thông báo cho MySQL
thiết lập một chỉ mục lên các trường firstName, lastName và details của bảng Staff. Các chỉ mục
chỉ có thể được tạo ra trên các trường có kiểu là VARCHAR và TEXT. Khi các trường này đã có
chỉ mục thì CSDL đã sẵn sàng cho việc khai thác tính năng TKTV để tìm các bản ghi phù hợp
yêu cầu tìm kiếm dựa trên các giá trị có trong ba trường này.
Để thử nghiệm, chúng ta bổ sung dữ liệu vào bảng mới tạo bằng các câu lệnh sau:
insert into Staff values(0, Jeff, Holmes, 52, Mr. Jeff Holmes is a senior teacher in Golden Key.
He likes Business, Technology and Finance. He is responsible for English for Information
Technology course in Golden Key.);
insert into Staff values(0, Beth, Adams, 29, Mrs. Beth Adams is the Director of Studies of
Golden Key Language Center. She was born in England. She is very nice and professional.);
insert into Staff values(0, Jason, Bell, 33, Mr. Jason Bell is a business assistant in Golden Key.
He graduated from London Business Management School. His major is Law in Business.);
Chú ý là TKTV được thiết kế cho các bảng dữ liệu lớn, khi dữ liệu càng lớn thì kết quả trả về
càng đáng tin cậy.
Thực hiện tìm kiếm
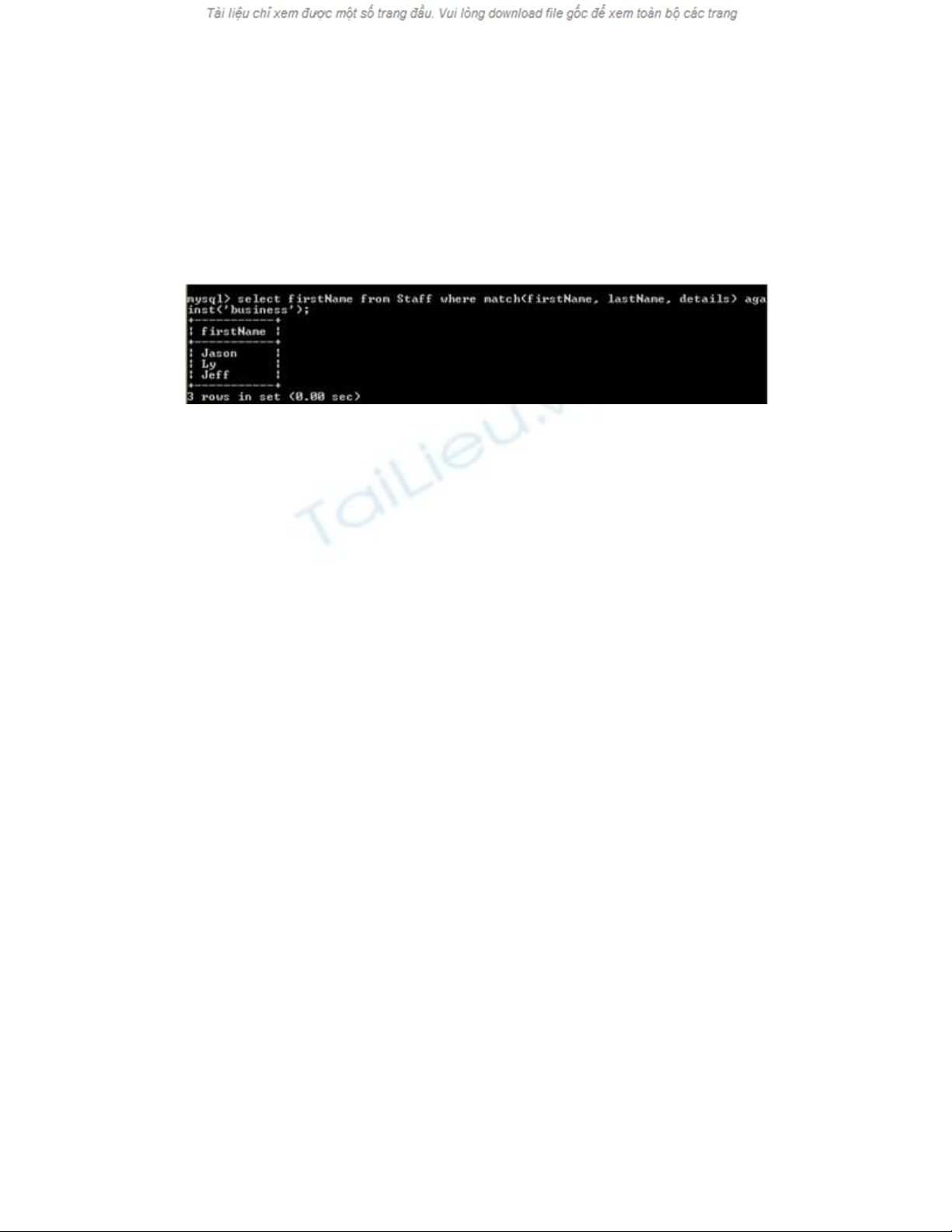
Sử dụng lệnh TKTV:
select firstName from Staff where match(firstName, lastName, details) against(business);
Kết quả trả lại như sau:
Chúng ta sẽ phân tích để thấy được sự khác biệt. Đầu tiên, xem xét phần SELECT và FROM
trong câu truy vấn:
select firstName from Staff
Ở đây không có gì khác biệt so với các câu SELECT bình thường khác. Nhưng sự khác biệt nằm
ở phần mệnh đề WHERE tiếp sau đó:
where match(firstName, lastName, details) against(business);
Đây chính là chỗ phát huy sức mạnh của TKTV. Trong phần đầu của câu truy vấn này, bạn dùng
câu lệnh MATCH. Lệnh này sẽ tiến hành so khớp yêu cầu tìm kiếm với các giá trị của các trường
firstName, lastName và details.
Khi câu lệnh MATCH được sử dụng trong mệnh đề SELECT nó sẽ trả lại một thứ tự sắp xếp
theo mức độ thích hợp, được xác định bằng một con số thập phân dương. Số này càng gần với 0
thì bản ghi càng kém thích hợp. Giá trị thích hợp này được xác định dựa trên biểu thức tìm kiếm,
số từ có trong các trường được đánh chỉ mục cũng như tổng số bản ghi được tìm kiếm.
Câu lệnh AGAINST chỉ chấp nhận một tham số. Đó là chuỗi mà chúng ta cần tìm.
Tuy nhiên, cho đến bây giờ chúng ta vẫn chưa thấy được sự khác biệt với cách tìm kiếm truyền
thống dựa trên câu lệnh LIKE:
select firstName from Staff where details like business;
Bạn hãy thực hiện câu lệnh trên để xem chúng có trả về cùng một tập kết quả không? Câu trả lời
có thể là: có và không. Chính sự can thiệp của thứ tự sắp xếp theo mức độ thích hợp đã làm cho
tập kết quả này có sự sai khác với tập kết quả có từ TKTV.

Sắp xếp theo độ thích hợp
Để kiểm tra con số đánh giá mức độ thích hợp, chúng thực hiện câu lệnh truy vấn sau:
select concat(firstName, , lastName) as name, match(firstName, lastName, details)
against(business) as relevance from Staff where match(firstName, lastName, details)
against(business);
Kết quả trả lại như sau:
Trong câu truy vấn này, chúng ta sử dụng lệnh MATCH trong mệnh đề SELECT để gửi trả lại
chỉ số đánh giá mức độ thích hợp cho mỗi bản ghi. Câu lệnh trên thực hiện việc TKTV trên các
trường firstName, lastName và details để so khớp chuỗi "business":
where match(firstName, lastName, details) against(business);
Câu lệnh truy vấn này trả về hai bản ghi có chứa chuỗi "business" nằm ở một trong các trường
firstName, lastName hay details. Bây giờ chúng ta sẽ xem lại các bản ghi có chứa chuỗi
"business":
"Ms. Nguyen Hoang Ly is the Marketing and Business Development Manager In Golden Key
Language Center. If you want to talk about business cooperation, please call her."
"Mr. Jeff Holmes is a senior teacher in Golden Key. He likes Business, Technology and Finance.
He is responsible for English for Information Technology course in Golden Key."
"Mr. Jason Bell is a business assistant in Golden Key. He graduated from London Business
Management School. His major is Law in Business."
Trường relevance trả lại từ câu truy vấn của chúng ta được tạo ra từ chuỗi lệnh sau:
match(firstName, lastName, details) against(business) as relevance

























