
Trịnh Tấn Đạt
Khoa CNTT – Đại Học Sài Gòn
Email: trinhtandat@sgu.edu.vn
Website: https://sites.google.com/site/ttdat88/

Contents
Introduction
Voting
Bagging
Boosting
Stacking and Blending

Introduction

Definition
An ensemble of classifiers is a set of classifiers whose individual decisions
are combined in some way (typically, by weighted or un-weighted voting)
to classify new examples
Ensembles are often much more accurate than the individual classifiers that
make them up.
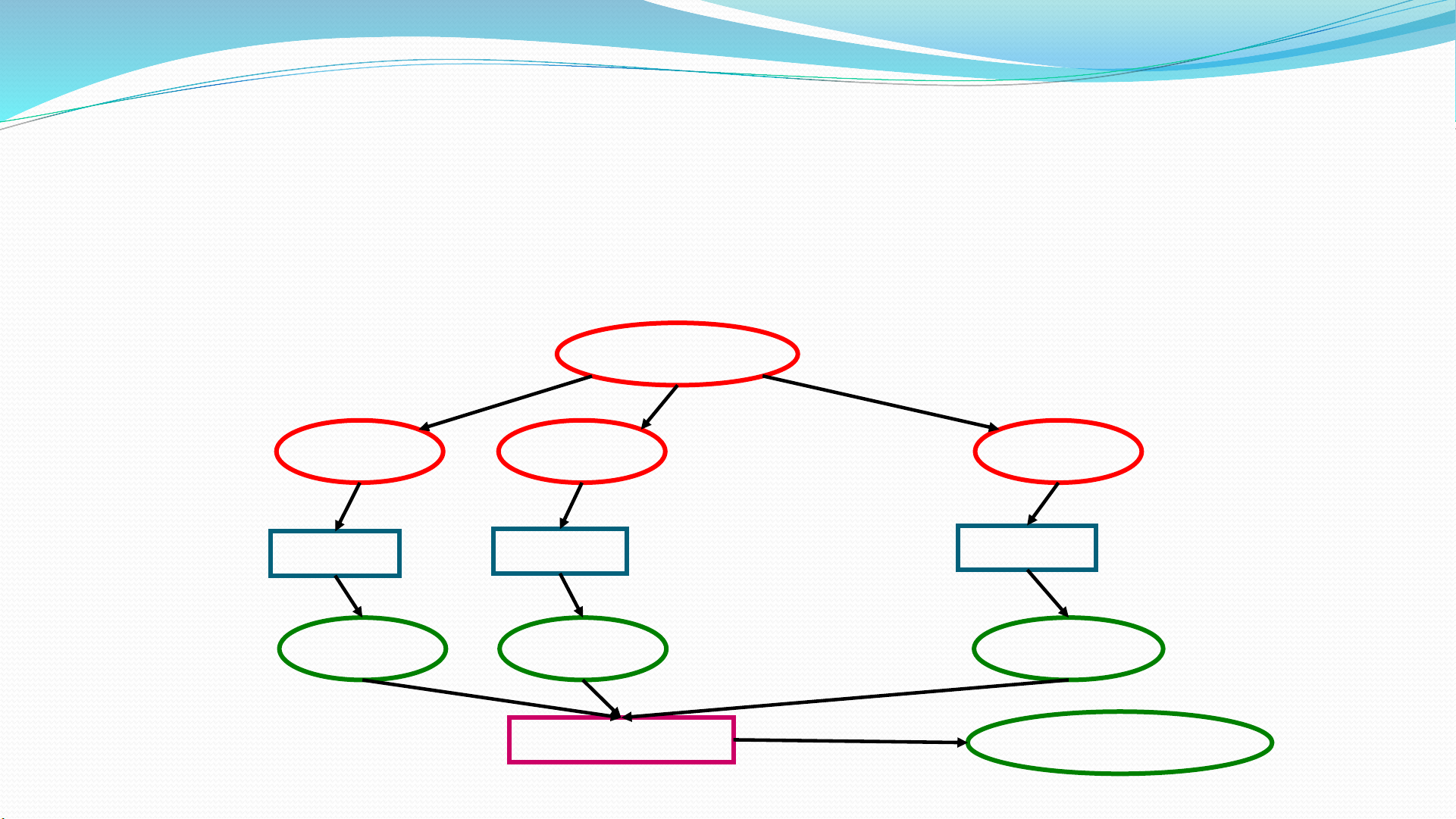
Learning Ensembles
Learn multiple alternative definitions of a concept using different training
data or different learning algorithms.
Combine decisions of multiple definitions, e.g. using voting.
Training Data
Data 1 Data KData 2
Learner 1 Learner 2 Learner K
Model 1 Model 2 Model K
Model Combiner Final Model

























