
1
LU T K T H PẬ Ế Ợ
(Association Rules)
Ch ng 2ươ
2
01/18/13 www.lhu.edu.vn
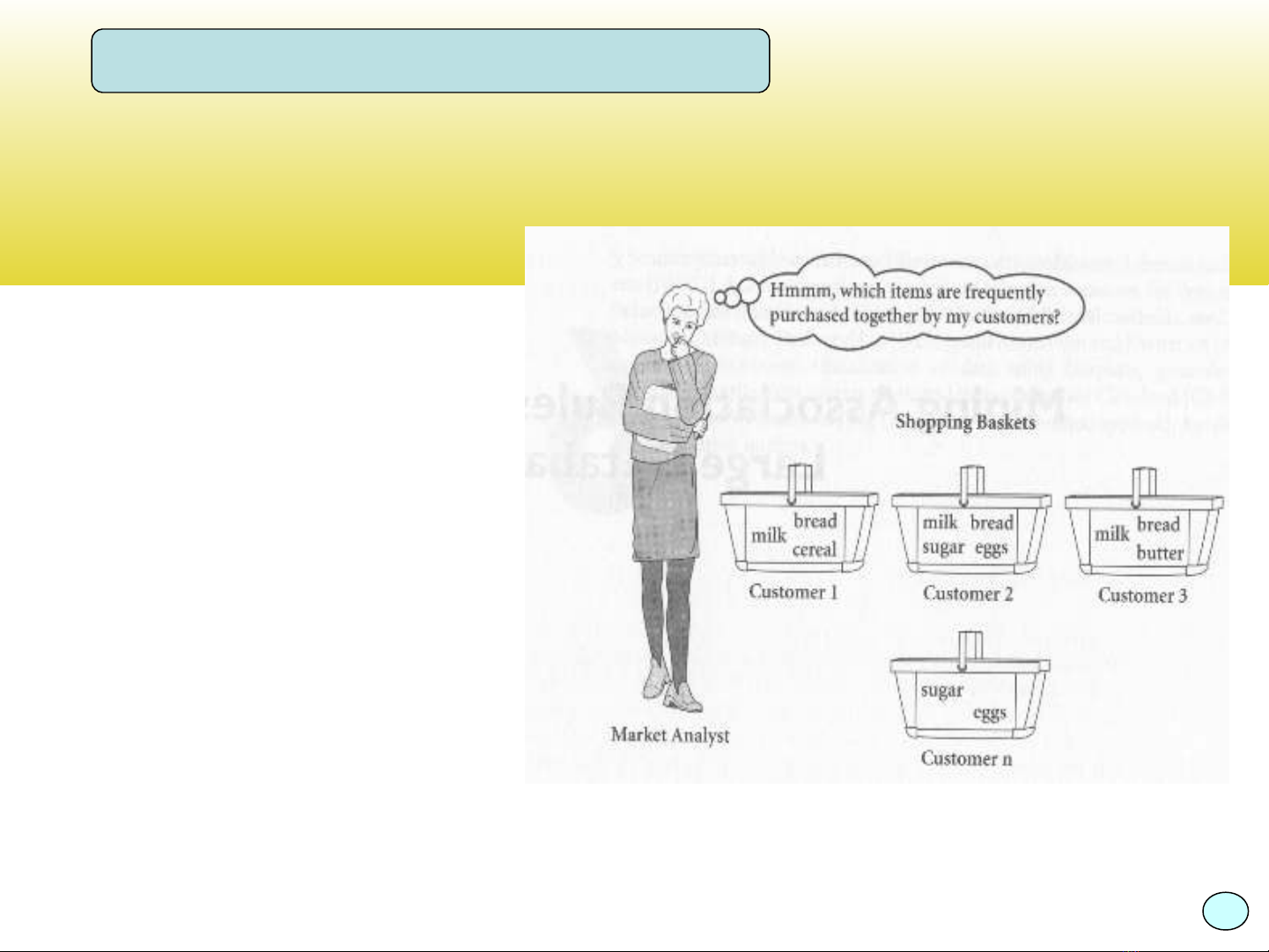
•Phân tích vi c ệ
Phân tích vi c ệ
mua hàng c a ủ
mua hàng c a ủ
khách hàng b ng ằ
khách hàng b ng ằ
cách tìm ra nh ng ữ
cách tìm ra nh ng ữ
“m i k t h p” gi a ố ế ợ ữ
“m i k t h p” gi a ố ế ợ ữ
nh ng m t hàng ữ ặ
nh ng m t hàng ữ ặ
mà khách đã mua.
mà khách đã mua.
•Bài toán đ c ượ
Bài toán đ c ượ
Agrawal thu c ộ
Agrawal thu c ộ
nhóm nghiên c u ứ
nhóm nghiên c u ứ
c a IBM đ a ra ủ ư
c a IBM đ a ra ủ ư
vào năm 1994.
vào năm 1994.
Bài toán phân tích gi hàng ỏ
Bài toán phân tích gi hàng ỏ

3
Lu t k t h p: C sậ ế ợ ơ ở
Lu t k t h p: C sậ ế ợ ơ ở
Khai phá lu t k t h p:ậ ế ợ
Khai phá lu t k t h p:ậ ế ợ
–Tìm t n s m u, m i k t h p, s t ng quan, hay các c u ầ ố ẫ ố ế ợ ự ươ ấ
trúc nhân qu gi a các t p đ i t ng trong các c s d ả ữ ậ ố ượ ơ ở ữ
li u giao tác, c s d li u quan h , và nh ng kho thông tin ệ ơ ở ữ ệ ệ ữ
khác.
Tính hi u đ c:ể ượ
Tính hi u đ c:ể ượ d hi uễ ể
Tính s d ng đ c: ử ụ ượ
Tính s d ng đ c: ử ụ ượ Cung c p thông tin thi t th cấ ế ự
Tính hi u qu : ệ ả
Tính hi u qu : ệ ả Đã có nh ng thu t toán khai thác hi u ữ ậ ệ
quả
Các ng d ng:ứ ụ
Các ng d ng:ứ ụ
–Phân tích bán hàng trong siêu th , cross-marketing, thi t k ị ế ế
catalog, loss-leader analysis, gom c m, phân l p, ...ụ ớ

4
Đ nh d ng th hi n đ c tr ng cho các lu t k t h p:ị ạ ể ệ ặ ư ậ ế ợ
Đ nh d ng th hi n đ c tr ng cho các lu t k t h p:ị ạ ể ệ ặ ư ậ ế ợ
–khăn ⇒ bia [0.5%, 60%]
–mua:khăn ⇒ mua:bia [0.5%, 60%]
–“N uế mua khăn thì mua bia trong 60% tr ng h p. Khăn và ườ ợ
bia đ c mua chung trong 0.5% dòng d li u."ượ ữ ệ
Các bi u di n khác:ể ễ
Các bi u di n khác:ể ễ
–mua(x, “khăn") ⇒ mua(x, “bia") [0.5%, 60%]
–khoa(x, "CS") ^ học(x, "DB") ⇒ đi mể(x, "A") [1%, 75%]
Lu t k t h p: C sậ ế ợ ơ ở
Lu t k t h p: C sậ ế ợ ơ ở
5
khăn ⇒ bia [0.5%, 60%]
Lu t k t h p: C sậ ế ợ ơ ở
Lu t k t h p: C sậ ế ợ ơ ở
Ti n đề ề
Ti n đề ề, v trái lu tế ậ
M nh đ k t quệ ề ế ả
M nh đ k t quệ ề ế ả, v ph i lu t ế ả ậ
Support
Support, đ h tr / ng h (“trong bao nhiêu ph n trăm d ộ ỗ ợ ủ ộ ầ ữ
li u thì nh ng đi u v trái và v ph i cùng x y ra")ệ ữ ề ở ế ế ả ả
Confidence
Confidence, đ m nh (“n u v trái x y ra thì có bao nhiêu ộ ạ ế ế ả
kh năng v ph i x y ra")ả ế ả ả
“N UẾ mua khăn
THÌ mua bia
trong 60% tr ng h pườ ợ
trên 0.5% dòng d li u"ữ ệ
1 2 3 4

























