
KHOA HỌC KỸ THUẬT THỦY LỢI VÀ MÔI TRƯỜNG - SỐ 88 (3/2024)
19
BÀI BÁO KHOA HỌC
NGHIÊN CỨU LỰA CHỌN MÔ HÌNH HỌC MÁY PHÙ HỢP
TRONG XÂY DỰNG BẢN ĐỒ PHÂN VÙNG NGUY CƠ SẠT LỞ ĐẤT
CHO KHU VỰC VÙNG NÚI TỈNH QUẢNG NGÃI
Đoàn Viết Long
1
, Nguyễn Chí Công
1
, Nguyễn Tiến Cường
2
Tóm tắt: Học máy là một phương pháp hiện đại, được ứng dụng rộng rãi trong dự đoán nguy cơ sạt lở
đất với rất nhiều loại mô hình khác nhau. Tuy nhiên, các nghiên cứu trước đây cho thấy rằng không có
một mô hình học máy nào là tốt nhất cho các khu vực. Đối với khu vực vùng núi tỉnh Quảng Ngãi
thường xuyên xảy ra sạt lở đất, nghiên cứu này đã sử dụng 5 thuật toán học máy: Logistic Regression,
Support Vector Machine, Decision Tree, Random Forest và Extreme Gradient Boosting (XGBoost) để
xây dựng mô hình dự đoán. Kết quả kiểm định và so sánh các mô hình thông qua các chỉ số thống kê và
phương pháp ROC cho thấy mô hình XGBoost có hiệu quả dự đoán tốt nhất (ACC= 0.813, kappa =
0.625, AUC = 0.892). Mô hình này được lựa chọn để xây dựng để tính toán chỉ số nguy cơ và xây dựng
bản đồ phân vùng nguy cơ sạt lở đất. Kết quả đánh giá mật độ sạt lở đất và kiểm chứng thực tế cho thấy
khả năng dự đoán rất tốt của bản đồ này.
Từ khóa: Học máy, Logictic Regression, SVM, Random Forest, XGBoost, ROC.
1. GIỚI THIỆU CHUNG
*
Sạt lở đất (SLĐ) là một hiện tượng rất phức tạp
do sự tương tác của nhiều yếu tố tự nhiên (địa
chất, địa mạo, khí tượng, thủy văn...) và yếu tố
con người (Varnes, 1984). SLĐ là một trong
những loại hình thiên tai nguy hiểm nhất, không
chỉ ở mỗi nước mà trên toàn thế giới
(Reichenbach, et al 2018). Ở Việt Nam, SLĐ xảy
ra thường xuyên ở các tỉnh miền núi phía Bắc và
miền Trung – Tây Nguyên (Long, nnk 2020a).
Hiện tượng này thường xảy ra bất ngờ, nhanh,
mạnh dẫn đến khó cảnh báo và dự báo, để lại hậu
quả kinh tế xã hội lớn, lâu dài và khó khắc phục.
Theo thống kê từ Tổng cục phòng chống thiên tai
(2020), thiên tai lũ quét và SLĐ trong giai đoạn từ
2000 đến 2020 đã làm 1,117 người chết và mất
tích, 671 người bị thương, 12,038 nhà bị sập đổ.
Trong nghiên cứu về SLĐ, bản đồ phân vùng
nguy cơ SLĐ là công cụ hữu hiệu để phòng chống
loại hình thiên tai đặc biệt nguy hiểm này. Đến
nay, rất nhiều nghiên cứu liên quan đến xây dựng
1
Khoa Xây dựng Công trình thủy, Trường Đại học Bách
khoa, Đại học Đà Nẵng
2
Khoa Kỹ thuật Ô tô và Năng lượng, Trường Đại học
Phenikaa
loại bản đồ này đã được công bố. Các nghiên cứu
gần đây tập trung chủ yếu vào phát triển các mô
hình nhằm tăng độ chính xác trong dự đoán
(Reichenbach, et al 2018). Ngày nay, với sự phát
triển của công nghệ viễn thám, kỹ thuật GIS cùng
với sự ra đời của các mô hình thống kê hiện đại
như học máy, độ chính xác của mô hình dự đoán
nguy cơ SLĐ ngày càng được nâng cao. Do đó,
xây dựng mô hình dự đoán nguy cơ SLĐ sử dụng
phương pháp học máy đang trở thành xu hướng
chính trong các nghiên cứu hiện nay (Liu, et al
2023). Nghiên cứu của Reichenbach et al (2018)
đã chỉ ra rằng phương pháp học máy có hiệu quả
cao và dần thay thế các phương pháp thống kê
truyền thống trong nghiên cứu lập bản đồ phân
vùng nguy cơ SLĐ. Ngoài ra, nghiên cứu của Liu
et al (2023) cũng cho thấy số lượng các công bố
về xây dựng bản đồ phân vùng nguy cơ SLĐ sử
dụng phương pháp học máy có sự tăng trưởng
vượt bậc trong giai đoạn từ năm 2015 đến 2021.
Bên cạnh đó, các nghiên cứu này cũng đã chỉ ra
rằng không có một mô hình dự đoán nguy cơ SLĐ
nào là tốt nhất cho tất cả các khu vực.
Khu vực vùng núi tỉnh Quảng Ngãi là địa
phương thường xuyên chịu ảnh hưởng của thiên
KHOA HỌC KỸ THUẬT THỦY LỢI VÀ MÔI TRƯỜNG - SỐ 88 (3/2024)
20
tai SLĐ. Theo kết quả thống kê trong điều tra của
Viện khoa học địa chất và khoáng sản (2020),
Quảng Ngãi được xác định là địa phương thuộc
nhóm có mật độ SLĐ cao nhất (0.167 điểm/km
2
).
Một số nghiên cứu đã sử dụng các mô hình hoặc
phương pháp khác nhau để dự đoán nguy cơ SLĐ
cho khu vực này như: phương pháp AHP (Cong,
et al 2019; Cong, et al 2023), phương pháp
Frequency Ratio (FR) (Long, nnk 2020b), LR
(Long, et al 2022). Tuy nhiên các nghiên cứu này
chỉ áp dụng các phương pháp mang tính chuyên
gia như AHP, các mô hình thống kê đơn giản như
FR, LR nên độ chính xác trong dự đoán không cao
(AUC < 0.8). Nghiên cứu của Long et al (2023) đã
sử dụng các mô hình hiện đại hơn như Support
Vector Machine (SVM), XGBoost để xây dựng
mô hình dự đoán nguy cơ SLĐ. Kết quả cho thấy
rằng mô hình học máy XGBoost có sự cải thiện
đáng kể về khả năng dự đoán so với mô hình
thống kê truyền thống. Tuy nhiên, nghiên cứu này
lại chưa xây dựng và đánh giá bản đồ phân vùng
nguy cơ SLĐ.
Trên cơ sở xu hướng nghiên cứu về đánh giá
nguy cơ SLĐ ở trên thế giới cũng như hạn chế của
các nghiên cứu áp dụng tại khu vực vùng núi tỉnh
Quảng Ngãi, nghiên cứu này sử dụng các mô hình
học máy từ đơn giản đến phức tạp như LR, DT,
SVM, Random Forest, XGBoost để dự đoán nguy
cơ SLĐ. Mô hình có khả năng dự đoán tốt nhất
được lựa chọn để xây dựng bản đồ phân vùng
nguy cơ SLĐ. Hiệu quả của bản đồ này sẽ được
đánh giá bằng chỉ số mật độ SLĐ và kết quả kiểm
chứng thực tế.
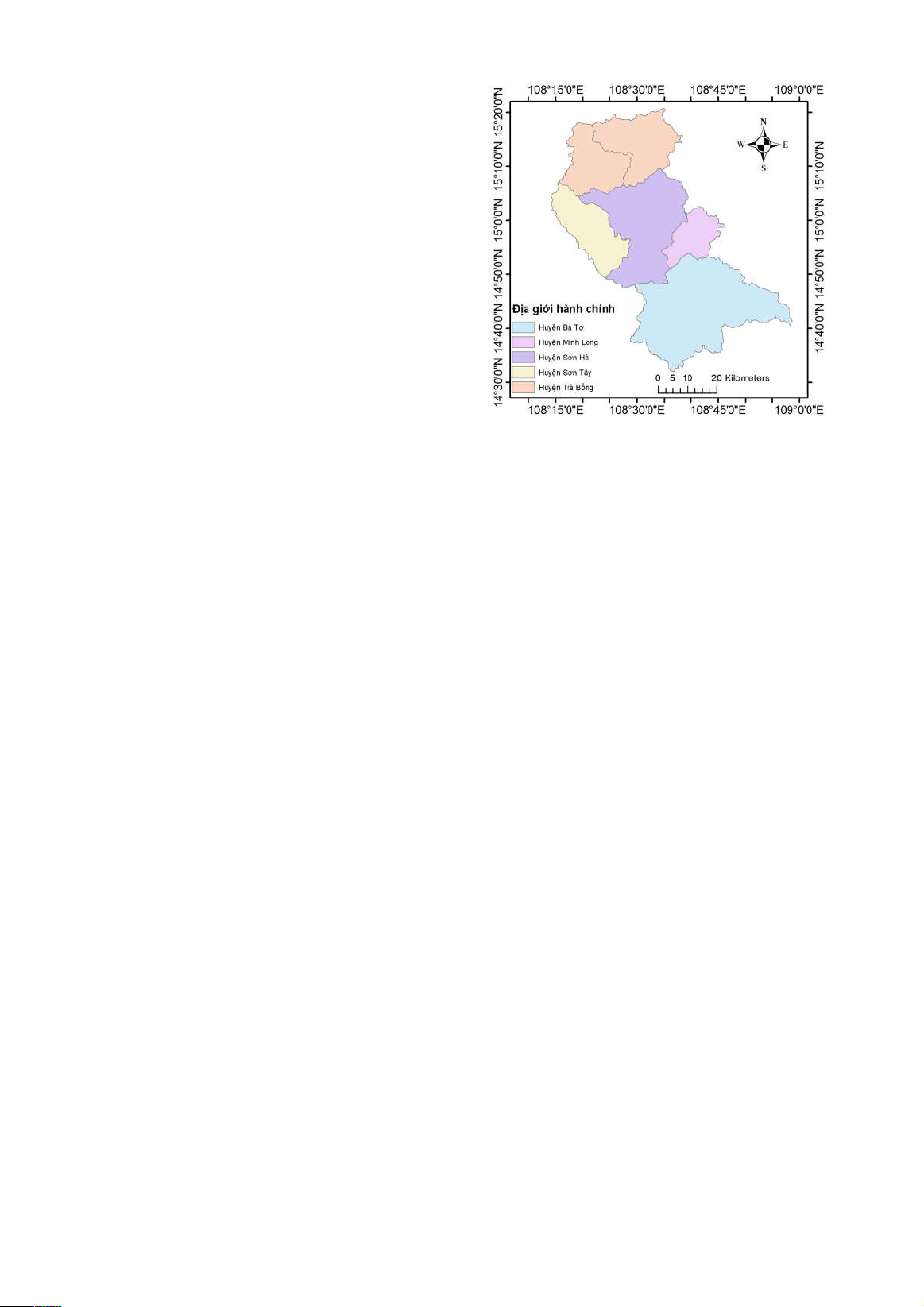
2. KHU VỰC NGHIÊN CỨU
Khu vực nghiên cứu lựa chọn là 5 huyện
miền núi thuộc tỉnh Quảng Ngãi, với tổng diện
tích khoảng 3,237 km
2
(Hình 1). Phía Tây tiếp
giáp với dãy Trường Sơn, phía Đông tiếp giáp
với đồng bằng ven biển. Độ dốc địa hình có xu
hướng giảm dần từ Tây sang Đông. Hàng năm,
từ tháng 9 đến tháng 12, khu vực này hứng chịu
trung bình từ 3 đến 17 cơn bão nhiệt đới kèm
theo lượng mưa lớn. Hơn 70% lượng mưa hàng
năm của khu vực là do mưa bão hoặc áp thấp
nhiệt đới. Đây được xem là nguyên nhân chính
dẫn đến SLĐ ở khu vực này.
Hình 1. Khu vực nghiên cứu
3. PHƯƠNG PHÁP NGHIÊN CỨU
Xây dựng bản đồ phân vùng nguy cơ SLĐ gồm
các bước sau:
(1) Thu thập dữ liệu, bao gồm: (i) dữ liệu hiện
trạng sạt lở đất và (ii) dữ liệu các yếu tố ảnh
hưởng (độ dốc, hướng phơi sườn, cao độ, độ cong
địa hình, chỉ số độ ẩm địa hình (TWI), sử dụng
đất, loại đất, khoảng cách đến đường, khoảng cách
đến sông suối, lượng mưa).
(2) Chọn phân tích và chọn lọc dữ liệu bằng
phương pháp VIF và Boruta.
(3) Xây dựng mô hình dự đoán, các mô hình
được sử dụng bao gồm: LR, SVM, DT, RF,
XGBoost, sử dụng dữ liệu huấn luyện.
(4) Kiểm định mô hình bằng dữ liệu kiểm tra.
(5) So sánh, đánh giá mô hình thông qua các
chỉ số thống kê và phương pháp ROC để xác định
mô hình phù hợp nhất.
(6) Xây dựng và đánh giá bản đồ phân vùng
nguy cơ sạt lở đất.
3.1. Thu thập và phân tích dữ liệu
3.1.1. Dữ liệu hiện trạng SLĐ
Bản đồ hiện trạng sạt lở đất đã được xây dựng
dựa trên tổng số 1,279 sự kiện sạt lở đất được xác
định bằng viễn thám và từ dự án. Trong đó, dự án
thực hiện bởi Viện khoa học địa chất và khoáng
sản (2020) đã xác định có 549 vụ sạt lở đất. Ngoài
ra, kỹ thuật viễn thám sử dụng hình ảnh Google
Earth kết hợp với hình ảnh vệ tinh Sentinel-2 đã
KHOA HỌC KỸ THUẬT THỦY LỢI VÀ MÔI TRƯỜNG - SỐ 88 (3/2024)
21
xác định được thêm 730 vụ sạt lở đất. Chuỗi dữ
liệu hiện trạng sạt lở đất được tạo ra bằng kỹ thuật
phát hiện sự thay đổi dựa trên ảnh vệ tinh
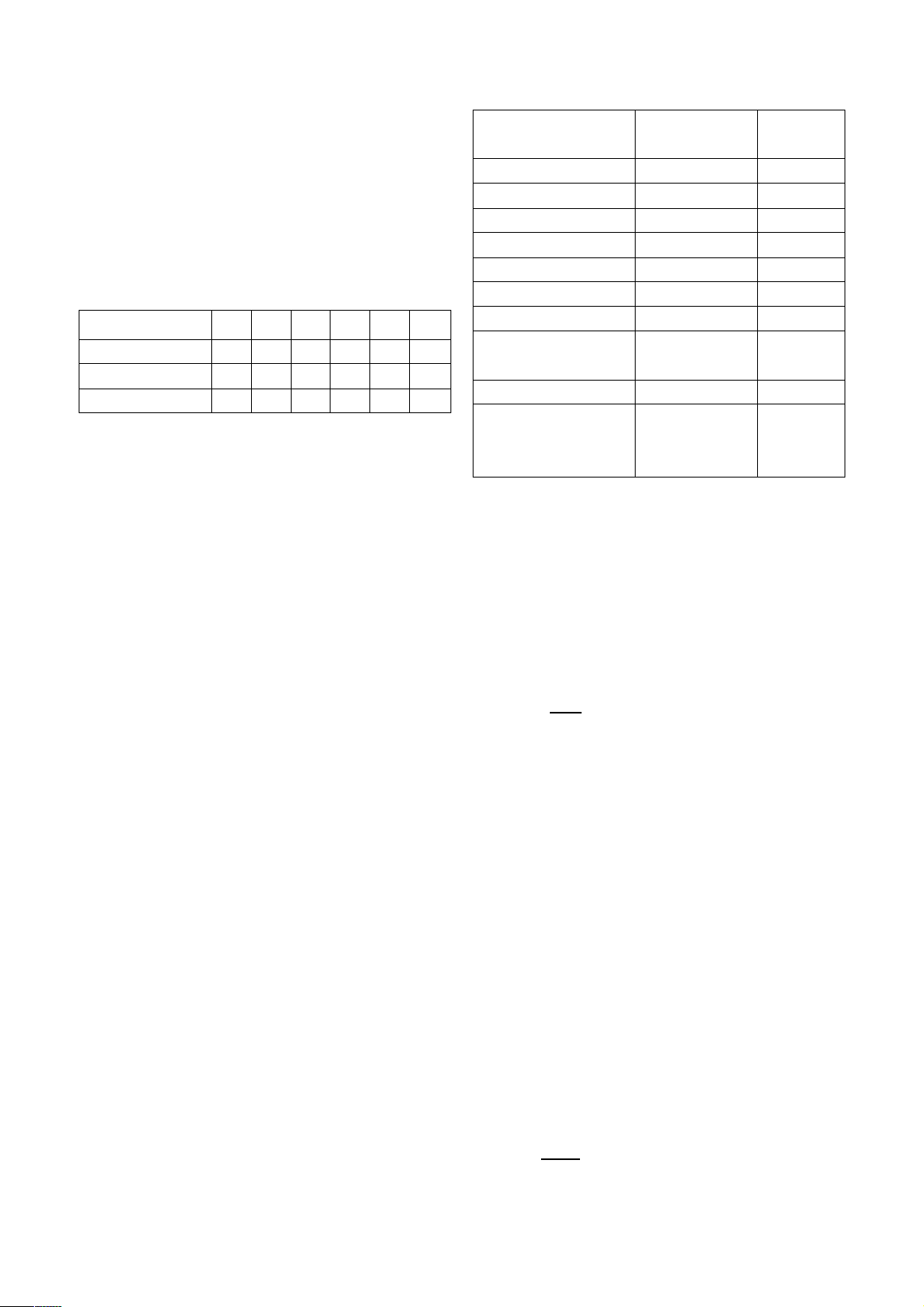
Sentinel-2 trong giai đoạn 2016-2020 (Bảng 1)
(Long, nnk 2021). Dữ liệu này sau đó được chia
thành hai nhóm: (i) tập dữ liệu huấn luyện (70%
điểm sạt lở đất) và (ii) tập dữ liệu kiểm tra (30%
điểm sạt lở đất còn lại).
Bảng 1. Dữ liệu hiện trạng SLĐ
Năm 2016
2017
2018
2019
2020
Tổng
Dữ liệu từ khảo sát 113 306 127 3 NA 549
Dữ liệu từ viễn thám 117 204 60 2 347 730
Tổng 230 510 187 5 347 1279
3.1.2. Dữ liệu các yếu tố ảnh hưởng
a. Lượng mưa
Dữ liệu mưa được thu thập từ Đài khí tượng
thủy văn khu vực Trung Trung Bộ. SLĐ tại khu
vực vùng núi tỉnh Quảng Ngãi thường xảy ra
sau nhận đợt mưa lớn kéo dài nhiều ngày, trong
đó lượng mưa tích lũy 3 ngày lớn nhất (3-NLN)
được xem là có ảnh hưởng nhất (Cong, et al
2019; Phuoc, et al 2019). Các bản đồ lượng mưa
3-NLN từ 2016 đến 2020 được thiết lập với độ
phân giải 30x30m. Với quan điểm mưa là yếu tố
mang tính chất thay đổi theo thời gian, nghiên
cứu này lựa chọn dữ liệu mưa 3-NLN kết hợp
với chuỗi dữ liệu các điểm SLĐ xảy ra trong
giai đoạn 2016-2020 để tạo ra chuỗi dữ liệu
lượng mưa theo thời gian.
c. Dữ liệu các yếu tố ảnh hưởng khác
Nghiên cứu này sử dụng bản đồ NASADEM
để trích xuất ra các yếu tố ảnh hưởng: độ dốc,
hướng phơi sườn, cao độ, TWI, độ cong địa
hình. Ngoài ra, nghiên cứu này còn thu thập
các nguồn dữ liệu có sẵn từ Sở Tài nguyên và
Môi trường tỉnh Quảng Ngãi (STNMTQN) như
bản đồ phân loại đất, bản đồ mạng lưới sông
suối, đường giao thông và sử dụng kỹ thuật
GIS để phân tích thành các bản đồ: loại đất, sử
dụng đất, khoảng cách đến sông suối, khoảng
cách đến đường giao thông. Thông tin chi tiết
của các yếu tố ảnh hưởng được cho ở Bảng 2.
Các yếu tố này sẽ được đánh giá và chọn lọc
trước khi sử dụng cho mô hình dự đoán.
Bảng 2. Thông tin các yếu tố ảnh hưởng
Yếu tố Nguồn gốc dữ liệu Tỷ lệ/độ phân
giải
Độ dốc NASA DEM 30x30 m
Hướng phơi sườn NASA DEM 30x30 m
Cao độ NASA DEM 30x30 m
TWI NASA DEM 30x30 m
Độ cong địa hình NASA DEM 30x30 m
Loại đất STNMTQN 1/100.000
Sử dụng đất STNMTQN 1/100.000
Khoảng cách đến đường
giao thông
STNMTQN 1/25.000
Khoảng cách đến sông suối
STNMTQN 1/25.000
Chuỗi dữ liệu lượng mưa
tích lũy lớn nhất
Đài khí tượng thủy
văn khu vực Trung
Trung Bộ
30x30 m
3.2. Đánh giá và chọn lọc dữ liệu
Phân tích đa cộng tuyến là một bước quan
trọng trong xây dựng mô hình dự đoán nguy cơ
SLĐ. Đa cộng tuyến là hiện tượng các biến đầu
vào có mối quan hệ phụ thuộc tuyến tính lẫn nhau.
Nghiên cứu này sử dụng chỉ số VIF để đánh giá đa
cộng tuyến (Pradhan & Sameen, 2017). Chỉ số này
được tính theo công thức:
=
(1)
Trong đó: R là hệ số tương quan đa biến giữa
một yếu tố ảnh hưởng và các yếu tố ảnh hưởng
khác trong mô hình.
Trong một số nghiên cứu, yếu tố có chỉ số VIF
> 5 được xem là có vấn đề về đa cộng tuyến và
khi VIF > 10 thì yếu tố đó cần được loại bỏ
(Pradhan & Sameen, 2017).
3.3. Lý thuyết các mô hình học máy
3.3.1. Mô hình LR
LR là một mô hình phân tích hồi quy tuyến
tính tổng quát phù hợp với bài toán đa biến. LR
được giới thiệu vào cuối thập niên 1960 và đầu
thập niên 1970 (Cabrera, 1994) và được ứng dụng
rộng rãi trong đánh giá nguy cơ SLĐ
(Reichenbach, et al 2018). Mối quan hệ giữa giá
trị đầu ra và các yếu tố đầu vào được mô tả bằng
phương trình:
=
(2)

KHOA HỌC KỸ THUẬT THỦY LỢI VÀ MÔI TRƯỜNG - SỐ 88 (3/2024)
22
Với z = w
0
+ w
1
x
1
+ w
2
x
2
+ ... + w
n
x
n
là mô
hình LR căn bản.
wi (i = 1, 2, ..., n) và w
0
là bộ tham số của
mô hình.
n là số yếu tố ảnh hưởng được xét đến.
mô tả xác suất xảy ra SLĐ tại vị trí i, có giá
trị trong khoảng [0,1].
Trong nghiên cứu này, hàm “glm” trong thư
viện “caret” thuộc ngôn ngữ lập trình R được sử
dụng để xây dựng mô hình dự đoán.
3.3.2. Mô hình SVM
Mô hình SVM bắt đầu được áp dụng vào
nghiên cứu SLĐ từ năm 2011 với khả năng xử lý
không gian đa chiều hiệu quả và hiệu suất phân
loại cao. Giả sử có một tập huấn luyện (X
i
, Y
i
),
với X
i
ϵ Rn: là vector đầu vào của các yếu tố ảnh
hưởng; Y
i
là giá trị đầu ra (SLĐ hoặc không
SLĐ). Bài toán tối ưu trong SVM là tìm ra một
siêu mặt phẳng sao cho lề đạt giá trị lớn nhất hay
xác định các tham số w và b để tối ưu hóa hàm
mục tiêu sau (Huang & Zhao, 2018):
:
,,
+ ∑
(3)
Với w là vector trọng số xác định hướng của
siêu mặt phẳng; b là phần dời của siêu phẳng so
với gốc tọa độ; ζ
i
là biến đo sự hy sinh; C là hằng
số dương dùng để điều chỉnh tầm quan trọng giữa
lề và sự hy sinh.
SVM với các hàm kernel cho phép giải quyết
bài toán phân loại với dữ liệu đầy vào phi tuyến
tính. Nghiên cứu này sử dụng RBF kernel trong
thư viện “e1071” thuộc ngôn ngữ lập trình R được
sử dụng để xây dựng mô hình dự đoán.
3.3.3. Mô hình DT
DT là mô hình phân loại phi tham số, bao
gồm việc phân vùng và phân loại dữ liệu liên
tục dựa trên quy tắc quyết định (Friedl &
Brodley, 1997). Với bài toán phân loại trong
đánh giá nguy cơ SLĐ, nghiên cứu này sử dụng
chỉ số Gini và thuật toán CART để xây dựng mô
hình dự đoán. Bộ thông số của mô hình DT
gồm: complexity parameter, max_depth,
minsplit, minbucket. Hàm “rpart” trong thư viện
“rpart” của ngôn ngữ lập trình R được sử dụng
để xây dựng mô hình dự đoán.
3.3.4. Mô hình RF
RF là một thuật toán khai thác dữ liệu sử dụng
kỹ thuật Ensemble thuộc nhóm Bagging, có khả
năng phân loại chính xác dữ liệu bằng cách sử
dụng một tập hợp các cây quyết định (Breiman,
2001). Các thông số của mô hình RF bao gồm: (i)
số lượng cây quyết định (ntree) và (ii) số lượng
biến ngẫu nhiên tại mỗi lần phân tách (mtry). Mô
hình huấn luyện được thực hiện bằng ngôn ngữ R
với thư viện “randomForest”.
3.3.5. Mô hình XGBoost
XGBoost là thuật toán học máy có hiệu suất
cao được phát triển bởi Chen & Guestrin
(2016). XGboost sử dụng nhiều cây phân loại
và hồi quy (CART) và tích hợp chúng bằng
phương pháp Gradient Boosting. Mục tiêu của
thuật toán XGboost là cực tiểu hóa hàm mất
mát sau:
(Φ)=∑(
,
)+∑Ω(
)
(4)
Ω()= +
||||
(5)
Với
và
là các giá trị dự đoán và quan sát; T
là số lá của cây quyết định ; w là trọng số của mỗi lá;
γ, λ: là mức độ điều chuẩn.
Bộ thông số chính của mô hình XGBoost bao
gồm: nrounds, max-depth, eta, gamma, colsample-
bytree, min-child-weight, subsample. Hàm
“xgb.train” trong thư viện “xgboost” của ngôn
ngữ lập trình R được sử dụng để xây dựng mô
hình dự đoán.
3.4. Phương pháp đánh giá mô hình
3.4.1. Đánh giá bằng chỉ số thống kê
Các chỉ số thống kê được đề xuất sử dụng
trong đánh giá mô hình bao gồm: độ chính xác
(ACC), kappa (k), độ nhạy (SST), độ đặc hiệu
(SPF). Các chỉ số có giá trị càng cao chứng tỏ mô
hình càng đáng tin cậy (Frattini, et al 2010).
3.4.2. Phương pháp ROC
Đường cong ROC được xây dựng bởi các điểm
có tọa độ (SST, (1-SPF)) tương ứng với một
ngưỡng quyết định cụ thể. Giá trị diện tích dưới
đường cong ROC (AUC) dùng để đo hiệu suất của
mô hình. AUC có giá trị trong khoảng (0,1), giá trị
AUC càng gần 1 thì hiệu suất dự đoán của mô
hình càng cao. Mô hình có giá trị AUC từ 0.9 –
1.0 được đánh giá loại “rất tốt”, tiếp theo là “tốt”
(0.8 – 0.9), “khá” (0.7 – 0.8), “trung bình” (0.6-
0.7) và “không đáng tin cậy” (0.5 – 0.6)
(Kantardzic, 2011).

KHOA HỌC KỸ THUẬT THỦY LỢI VÀ MÔI TRƯỜNG - SỐ 88 (3/2024)
23
4. KẾT QUẢ VÀ THẢO LUẬN
4.1. Kết quả đánh giá và chọn lọc dữ liệu
4.1.1. Kết quả phân tích đa cộng tuyến
Kết quả đánh giá 10 yếu tố ảnh hưởng bằng
phương pháp VIF (Bảng 3) cho thấy tất cả các
yếu tố không xảy ra đa cộng tuyến (VIF<5).
Điều này cho thấy tất cả 10 yếu tố đều thỏa mãn
điều kiện đa cộng tuyến và được sử dụng vào
xây dựng mô hình.
Bảng 3. Kết quả phân tích đa cộng tuyến
bằng phương pháp VIF
STT Yếu tố VIF
1 Độ dốc 1.164
2 Hướng phơi sườn 1.013
3 Cao độ 1.516
4 TWI 1.827
5 Độ cong địa hình 1.346
6 Loại đất 1.017
7 Khoảng cách đến đường giao thông 1.269
8 Khoảng cách đến sông suối 1.171
9 Sử dụng đất 1.028
10 Lượng mưa
1.066
4.1.2. Kết quả đánh giá mức độ quan trọng của
các yếu tố
Nghiên cứu này sử dụng phương pháp RF để
đánh giá tầm quan trọng của các yếu tố. Kết
quả biểu đồ ở Hình 2 thể hiện sự xếp hạng chỉ
số quan trọng từ cao nhất đến thấp nhất. Trong
đó, yếu tố lượng mưa 3-NLN xếp vị trí cao
nhất. Có thể thấy rằng, việc áp dụng chuỗi dữ
liệu mưa 3-NLN đã giúp đánh giá đúng ảnh
hưởng của lượng mưa gây SLĐ. Điều này góp
phần cải thiện hạn chế của các nghiên cứu
trước đây khi chỉ dùng một bản đồ mưa trung
bình nhiều năm trong đánh giá, dẫn đến tầm
quan trọng của yếu tố mưa được đánh giá thấp
hơn các yếu tố khác (Le, et al 2023; Pham, et al
2019). Trong khi đó, các yếu độ dốc, khoảng
cách đến đường, cao độ vẫn nằm trong nhóm
ảnh hưởng cao, phù hợp với xu thế chung trong
đánh giá các yếu tố của các nghiên cứu trước
đây (Reichenbach, et al 2018).
Hình 2. Mức độ quan trọng
của các yếu tố ảnh hưởng
4.1.3. Kết quả mô hình dự đoán nguy cơ SLĐ
Quá trình xây dựng mô hình bằng dữ liệu
huấn luyện giúp xác định được bộ thông số tốt
nhất của các mô hình (Bảng 4 đến Bảng 8)
thông qua phương pháp tối ưu Stochastic
Gradient Descent (SGD) đối với mô hình LR và
kỹ thuật fine-tuning đối với các mô hình còn lại.
Bộ thông số tốt nhất của mô hình được xác định
tương ứng với trường hợp cho kết quả kiểm
định đạt giá trị ACC lớn nhất.
Bảng 4. Bộ thông số mô hình LR
Tham số Giá trị
Intercept -4.005*10
-1
Độ dốc 6.696*10
-2
Hướng phơi sườn 4.182*10
-2
Cao độ 1.179*10
-3
TWI -2.891*10
-1
Độ cong địa hình -3.245*10
-1
Loại đất 8.070*10
-2
Khoảng cách đến đường giao thông -9.397*10
-4
Khoảng cách đến sông suối -7.686*10
-4
Sử dụng đất
-3.390*10
-2
Lượng mưa 3-NLN
2.907*10
-3
Bảng 5. Bộ thông số mô hình SVM
Yếu tố Giá trị thông số Giá trị tốt nhất
cost 2^(2:9) 4
gamma 0:1 0.1
![Atlas tài nguyên nước Việt Nam: Tài liệu [Mô tả/Hướng dẫn/Chi tiết]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20250715/vijiraiya/135x160/348_tai-lieu-atlas-tai-nguyen-nuoc-viet-nam.jpg)









![Đề cương bài giảng Bản đồ đại cương [mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260323/hoatudang2026/135x160/81191774414215.jpg)
![Tài liệu giảng dạy Bản đồ và Hệ thống thông tin địa lý [chuẩn nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260323/hoatudang2026/135x160/61501774414218.jpg)













