
- 235
SỬ DỤNG CÁC MÔ HÌNH PHÂN LỚP, CẢNH BÁO SỚM
RỦI RO PHÁ SẢN CỦA DOANH NGHIỆP, THÔNG QUA BÁO CÁO
TÀI CHÍNH, BẰNG CHỨNG THỰC NGHIỆM TẠI VIỆT NAM
TS Nguyễn Huy Hoàng*
Nguyễn Tâm Nhi*
TÓM TẮT
Trong quá trình hoạt động, có thể một số Doanh nghiệp gặp phải rủi ro dẫn đến phá sản;
Việc dự báo sớm được khả năng này sẽ giúp ích cho Doanh nghiệp cũng như các Nhà quản
lý, Nhà đầu tư. Thông tin hoạt động Doanh nghiệp chủ yếu dựa vào báo cáo tài chính
(BCTC), nên việc xây dựng Mô hình cảnh báo sớm, rủi ro phá sản Doanh nghiệp thông
qua thông tin báo cáo tài chính là khả thi và hữu dụng. Nghiên cứu sử dụng một số Mô
hình phân lớp để giải quyết vấn đề này; việc xử lý kết quả được thông qua ngôn ngữ lập
trình Python. Bước đầu đạt kết quả khả quan và đáng tin cậy thông qua bằng chứng thực
nghiệm tại Việt Nam.
Từ khóa: Phá sản doanh nghiệp; Báo cáo tài chính; Mô hình phân lớp; Python.
1. Giới thiệu các kiến thức cơ bản
Các nhân tố, mô hình và phương pháp trong nghiên cứu
Biến phụ thuộc
Biến phụ thuộc trong mô hình dự báo rủi ro phá sản của doanh nghiệp là một biến nhị
phân. Nghiên cứu thực hiện thu thập số liệu theo 2 khung thời gian của các doanh nghiệp,
cụ thể như sau:
+ 4 quý: Đối với các doanh nghiệp đã phá sản, chọn quý thứ nhất là từ thời điểm phá
sản và 3 quý còn lại là từ thời điểm phá sản trở về trước. Đối với các doanh nghiệp đang
hoạt động, nghiên cứu chọn 4 quý từ quý III năm 2019 đến quý II năm 2020.
+ 8 quý: Đối với các doanh nghiệp đã phá sản, chọn quý thứ nhất là từ thời điểm phá
sản và 7 quý còn lại là từ thời điểm phá sản trở về trước. Đối với các doanh nghiệp đang
hoạt động, nghiên cứu chọn 8 quý từ quý IV năm 2018 đến quý II năm 2020.
* Khoa Kinh tế – Luật, Trường Đại học Tài chính – Marketing.

236 -
Biến phụ thuộc được xác định như sau: đối với các doanh nghiệp đã phá sản tại một
thời điểm xác định sẽ được gán nhãn với giá trị “1”; ngược lại, đối với các doanh nghiệp
hoạt động tại một thời điểm xác định sẽ được gán nhãn với giá trị “0”. Mô hình sau khi dự
báo sẽ cho xác suất phá sản cho từng đối tượng, tùy thuộc vào ngưỡng phân loại riêng của
mỗi nghiên cứu. Từ đó, có thể sắp xếp rủi ro phá sản vào các lớp phù hợp. Doanh nghiệp
có xác suất phá sản lớn hơn ngưỡng phân loại sẽ được xếp vào lớp “1” và ngược lại sẽ được
xếp vào lớp “0”.
Các biến độc lập
Nghiên cứu sử dụng 7 biến độc lập (thông tin trong BCTC) trong bảng dưới đây:
Bảng 1. Các biến của mô hình
STT Biến
Z1 Lợi nhuận sau thuế
Z2 Tổng tài sản
Z3 Nợ phải trả
Z4 Vốn chủ sở hữu
Z5 P/E
Z6 ROA
Z7 ROE
Trong nhiều tình huống cuộc sống, dự báo các phản ứng định tính là một nhu cầu
cần thiết, quá trình dự báo này được gọi là phân lớp (classification). Các phương thức được
sử dụng để phân lớp trước tiên dự báo xác suất xuất hiện từng lớp của một biến định tính,
làm cơ sở để thực hiện phân loại.
Có nhiều kỹ thuật để xây dựng một mô hình phân lớp, dự báo một phản ứng định
tính. Nghiên cứu này sử dụng một số các thuật toán phân lớp được sử dụng phổ biến nhất:
Logistic Regression; Random forest;… Xử lý kết quả bằng ngôn ngữ lập trình Python.
Các thuật toán này xác định xác suất phá sản của từng đối tượng, từ đó dự báo sớm doanh
nghiệp phá sản và doanh nghiệp hoạt động.
Mô hình Logistic Regression
Mô hình Logistic Regression ra đời vào những năm 1970 bởi Giáo sư David Roxbee
Cox. Logistic Regression nghiên cứu sự tác động của các biến độc lập (liên tục hoặc rời
rạc) đến biến phụ thuộc nhị phân (chỉ nhận một trong 2 giá trị: 0 hoặc 1). Một số khái niệm
liên quan đến mô hình Logistic Regression:
Odds ratio
Tỷ lệ Odds được định nghĩa là tỉ số của xác suất biến cố xảy ra trên xác suất biến cố
không/chưa xảy ra. Giá trị của xác suất dao động trong khoảng 0 đến 1, nhưng giá trị của
Odds thì không có giới hạn và là một biến liên tục.

- 237
Odds = x
N – x
Trong đó:
+ N: không gian mẫu
+ x: số lượng biến cố xảy ra
Logit của một biến cố
Gọi P là xác suất xảy ra biến cố:
P = x
N
Logit của một biến cố là log của tỷ lệ Odds:
logit(P) = log( P = log(Odds)
1 – P
Mô hình Logistic Regression có biến phụ thuộc là logit(P). Do đó, để mô hình mối
liên quan giữa rủi ro phá sản của doanh nghiệp và các biến độc lập, mô hình Logistic
Regression có thể viết lại thành:
logit(P) = α + β1X1 + β2X2 + β3X3 + ... + βnXn
⇒ P = exp(α + β1X1 + β2X2 + β3X3 + ... + βnXn)
1 + exp(α + β1X1 + β2X2 + β3X3 + ... + βnXn)
Khi đó, P là xác suất biến phụ thuộc (xác suất phá sản) nhận giá trị bằng 1 (có nguy cơ
phá sản) và 1 – P là xác suất biến phụ thuộc nhận giá trị bằng 0 (không có nguy cơ phá sản).
Random forest
Từ thế kỷ XX, các nhà khoa học dữ liệu đã nghiên cứu cách để kết hợp nhiều thuật
toán phân lớp thành tập hợp các thuật toán phân lớp để tăng độ chính xác so với chỉ sử dụng
một thuật toán duy nhất. Mục đích của các thuật toán kết hợp là giảm lỗi phương sai và độ
lệch (variance và bias) của các thuật toán. Bias là lỗi của mô hình học, còn variance là lỗi
do tính biến thiên của mô hình so với tính ngẫu nhiên của các mẫu dữ liệu.
Random forest được nghiên cứu (Breiman 2001) vì lý do trên. Đây là một trong
những thuật toán kết hợp thành công nhất. Random forest xây dựng các cây không cắt
nhánh nhằm giữ cho bias thấp và dùng tính ngẫu nhiên để điều khiển tính tương quan thấp
giữa các cây trong rừng. Random forest tạo ra một tập hợp các cây quyết định không cắt
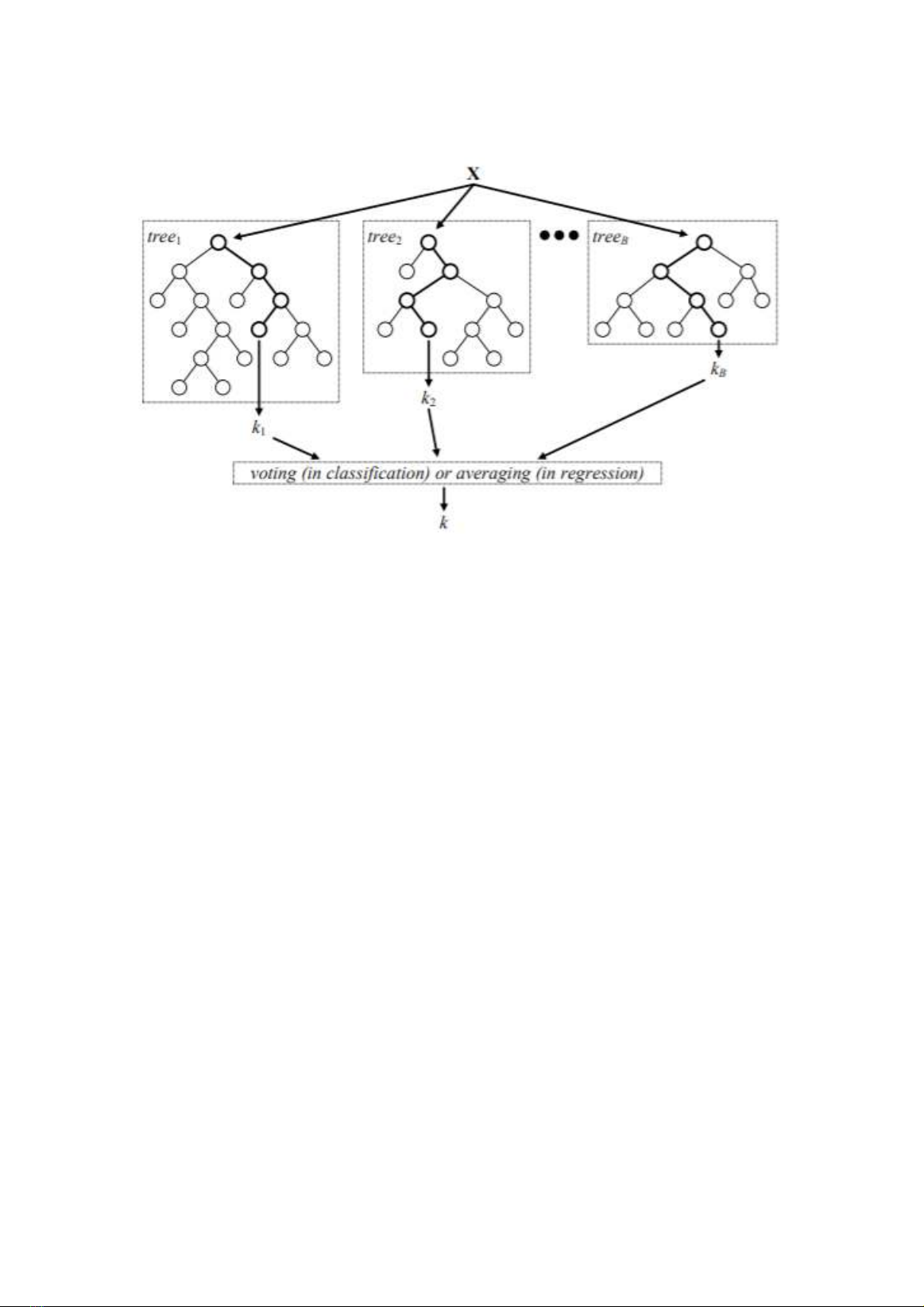
238 -
tỉa, mỗi cây được xây dựng trên cơ sở lấy mẫu ngẫu nhiên có hoàn lại. Lỗi tổng quát của
rừng phụ thuộc vào độ chính xác của từng cây thành viên trong rừng.
Hình 1. Random forest minh hoạ
Nguồn: Verikas et al. (2016)
Các bước xây dựng Random forest:
– Bước 1: Từ tập dữ liệu ban đầu S, sử dụng kỹ thuật lấy mẫu ngẫu nhiên có hoàn lại
để tạo ra k tập dữ liệu con S = {S1, S2,…,Sk}.
– Bước 2: Trên mỗi tập dữ liệu Si, xây dựng một cây quyết định Di. Thuật toán
Random forest là thuật toán D = {Di}k
i=1. Thay vì sử dụng tất cả các biến để lựa chọn điểm
chia tốt nhất, tại mỗi nút rừng ngẫu nhiên chọn ngẫu nhiên một không gian tập con K’ biến
từ K biến ban đầu (K’ << K).
– Bước 3: Random forest dự báo nhãn lớp của phần tử mới đến bằng chiến lược bình
chọn số đông của các cây quyết định.
Decision tree
Cây quyết được sử dụng cho cả vấn đề hồi quy (Cây hồi quy – Regression Trees) và
vấn đề phân lớp (Cây phân lớp – Classification Trees). Nghiên cứu này chỉ đề cập đến ứng
dụng phân lớp của cây quyết định để dự đoán một phản ứng định tính.
Cây quyết định thường có 3 phần chính: mỗi nhánh chỉ ra các quy luật, mỗi nút chỉ
ra được các đặc trưng và mỗi lá biểu diễn một kết quả (kết quả cuối cùng hoặc một nhánh
tiếp tục).

- 239
Bắt đầu từ một nút duy nhất chứa tất cả dữ liệu huấn luyện, dữ liệu được chia thành
hai nút bằng cách đặt câu hỏi nhị phân “nếu – thì – ngược lại”. Ví dụ, nếu tuổi của khách
hàng được so sánh với 30 để đưa ra quyết định phân nhánh. Sau khi phân nhánh, các khách
hàng dưới 30 tuổi đều ở cùng một nút trong khi các khách hàng có tuổi từ 30 trở lên nằm
ở nút còn lại.
Kích thước của cây có thể phát triển để thích ứng với sự phức tạp của vấn đề phân
loại (Alpaydin 2010). Khi các nút lá thỏa mãn một số chỉ số như Gini và Entropy, quá trình
phân nhánh dừng lại và quá trình cắt tỉa cây có thể được thực hiện để đơn giản hóa cây
bằng cách cắt tỉa và loại bỏ các biến không cung cấp những thông tin mới đáng kể cho việc
phân loại.
Khác với các kỹ thuật học máy như Mạng Neural nhân tạo hoặc Bayesian, cây quyết
định có thể cung cấp một lời giải thích dễ hiểu cho lý do đưa ra quyết định của nó. Sau khi
việc phân loại được thực hiện và một khách hàng đã được phân loại bởi cây quyết định này,
cán bộ tín dụng có thể theo dõi tất cả các câu hỏi được trả lời bởi các biến số của khách
hàng này (ví dụ thông tin nhân khẩu hoặc giao dịch) để hiểu được lý do khách hàng được
cây quyết định dán nhãn là tốt hoặc xấu.
Có nhiều thuật toán được sử dụng để xây dựng cây quyết định, phổ biến như:
– Thuật toán ID3 (Iterative Dichotomiser 3): được phát triển vào năm 1986 bởi Ross
Quinlan. ID3 được áp dụng cho các bài toán phân lớp mà tất cả các biến đều ở dạng
biến định tính. Thuật toán tạo ra một cây nhiều đường, tìm kiếm cho mỗi nút (thuật
toán tham lam), tính năng phân loại của thuật toán sẽ mang lại mức tăng thông tin lớn
nhất cho các mục tiêu phân loại. Cây được trồng với kích thước tối đa và sau đó một
bước cắt tỉa được áp dụng để cải thiện hiệu quả của cây.
– Thuật toán C4.5: là thuật toán kế thừa ID3, được Quinlan phát triển vào năm 1993.
C4.5 sử dụng cơ chế lưu trữ dữ liệu thường trú trong bộ nhớ, do đó C4.5 chỉ thích hợp
với những cơ sở dữ liệu nhỏ.
– Thuật toán C5.0: là phiên bản mới nhất của Quinlan, theo giấy phép độc quyền. C5.0
sử dụng ít bộ nhớ hơn và xây dựng các quy tắc nhỏ hơn so với thuật toán C4.5, nhưng
độ chính xác cao hơn.
– Thuật toán CART (Classification and Regression Trees): ra đời năm 1984 bởi một
nhóm các nhà thống kê (Breiman, Friedman, Olshen và Stone) đã xuất bản sách
“Classification and Regression Trees”. CART rất giống với C4.5, nhưng nó hỗ trợ cho
cả các biến đầu ra dạng hồi quy. CART xây dựng cây nhị phân bằng cách sử dụng các
biến và ngưỡng phân loại có mức tăng thông tin lớn nhất tại mỗi nút.
![Tài liệu ôn tập Quản lý rủi ro [chuẩn nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20250704/113646935453687751956/135x160/78_tai-lieu-quan-ly-rui-ro.jpg)





![Ảnh hưởng của lãnh đạo nữ đến rủi ro công ty: Nghiên cứu tại Việt Nam [2024]](https://cdn.tailieu.vn/images/document/thumbnail/2022/20220704/vichristinelagarde/135x160/1721656929150.jpg)


















