
ĐẠI HỌC QUỐC GIA HÀ NỘI
TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
PHẠM THỊ NGÂN
NGHIÊN CỨU CẢI TIẾN PHÂN LỚP ĐA NHÃN VĂN BẢN
VÀ ỨNG DỤNG
Chuyên ngành: Hệ thống thông tin
Mã số: 62.48.01.04
TÓM TẮT LUẬN ÁN TIẾN SĨ CÔNG NGHỆ THÔNG TIN
Hà Nội – 2017

Công trình được hoàn thành tại: Trường Đại học Công nghệ, Đại
học Quốc gia Hà Nội
Người hướng dẫn khoa học: PGS. TS. Hà Quang Thụy
PGS.TS. Phan Xuân Hiếu
Phản biện: PGS. TS Lương Chi Mai ...........................
Viện CNTT, Viện Hàn lâm KH&CNVN ........................
Phản biện: PGS.TS Đỗ Văn Thành .............................
Bộ Kế hoạch và Đầu tư ...................................................
Phản biện: TS. Nguyễn Thị Minh Huyền ...................
Trường Đại học Khoa học Tự nhiên, ĐHQGHN ............
Luận án được bảo vệ trước Hội đồng cấp Đại học Quốc gia
chấm luận án tiến sĩ họp tại Đại học Công nghệ, ĐHQGHN
vào hồi 09 giờ ngày 12 tháng 12 năm 2017
Có thể tìm hiểu luận án tại:
- Thư viện Quốc gia Việt Nam
- Trung tâm Thông tin - Thư viện, Đại học Quốc gia Hà

1
MỞ ĐẦU
Tính cấp thiết của luận án
Phân lớp là một trong những bài toán điển hình trong khai phá
dữ liệu; ứng dụng của phân lớp xuất hiện trong rất nhiều lĩnh vực của
đời sống. Tính ứng dụng cao của phân lớp làm cho bài toán phân lớp
được tiến hóa từ đơn giản tới phức tạp hơn theo hướng từ phân lớp
đơn nhãn tới phân lớp đa nhãn hoặc phân lớp đa thể hiện, và cho tới
phân lớp đa nhãn đa thể hiện. Phân lớp đơn nhãn (phân lớp truyền
thống) quy ước mỗi đối tượng dữ liệu có duy nhất một nhãn. Phân
lớp đa nhãn quy ước mỗi đối tượng dữ liệu có thể có hơn một nhãn.
Phân lớp đa thể hiện quy ước một đối tượng dữ liệu có thể tương ứng
với nhiều thể hiện và tương ứng với một nhãn. Phân lớp đa nhãn đa
thể hiện quy ước một đối tượng dữ liệu tương ứng với nhiều thể hiện
và các thể hiện này tương ứng với nhiều nhãn.
Phân lớp đa nhãn đòi hỏi những tiến hóa mới đối với các phương
pháp học máy cho các giải pháp thích hợp với các phần tử dữ liệu đa
nhãn như vấn đề mối quan hệ giữa các nhãn, chi phí tính toán của thuật
toán, vấn đề mất cân bằng nhãn, vấn đề đa chiều của dữ liệu... Phân
lớp đa nhãn là một chủ đề nghiên cứu, triển khai cuốn hút một cộng
đồng nghiên cứu rộng rãi với một số nhóm nghiên cứu nổi bật như các
nhóm nghiên cứu của Zhi-Hua Zhou, Min-Ling Zhang và cộng
sự, Ioannis P. Vlahavas, Grigorios Tsoumakas và cộng sự, Sebastián
Ventura Soto và cộng sự, v.v.
Luận án này tập trung vào chủ đề nghiên cứu phân lớp đa nhãn,
tiếp nối những nghiên cứu trước đó về bài toán phân lớp đa nhãn, các
phương pháp biểu diễn dữ liệu, lựa chọn đặc trưng và tiếp tục giải quyết
những vấn đề còn tồn tại liên quan đến bài toán phân lớp đa nhãn.

2
Luận án tập trung nghiên cứu về phân lớp đa nhãn và ứng dụng
vào phân lớp văn bản tiếng Việt.
Thứ nhất, luận án đề nghị một thuật toán phân lớp đa nhãn khai
thác đặc trưng riêng biệt dựa trên phân cụm bán giám sát (Thuật toán
MULTICS [PTNgan5], [PTNgan6]) trên cơ sở áp dụng một chiến
lược tham lam khi tích hợp hai thuật toán LIFT và TESC .
Thứ hai, luận án đề nghị hai mô hình biểu diễn dữ liệu cho phân lớp đa
nhãn là mô hình biểu diễn dữ liệu đồ thị khoảng cách [PTNgan4] khai thác
các thông tin bậc cao về trật tự và khoảng cách đặc trưng trong văn bản và
mô hình biểu diễn dữ liệu chủ đề ẩn [PTNgan3] khai thác các thông tin ngữ
nghĩa ẩn trong văn bản làm giàu thêm các đặc trưng cho mô hình.
Đồng thời, luận án cũng đề xuất hai mô hình phân lớp đơn nhãn
văn bản tiếng Việt tương ứng với hai bài toán ứng dụng thực tiễn bao
gồm mô hình gán nhãn thực thể có tên đề xuất trong [PTNgan1] và
mô hình hệ tư vấn xã hội đề xuất trong [PTNgan2].
Luận án cũng thực thi các thực nghiệm kiểm chứng các thuật toán
và mô hình đề xuất. Dữ liệu thực nghiệm được thu thập từ các trang web
tiếng Việt liên quan tới miền ứng dụng. Luận án cũng cung cấp một
nghiên cứu tổng quan về học máy đa nhãn.
Bố cục của luận án gồm phần mở đầu và bốn chương nội dung,
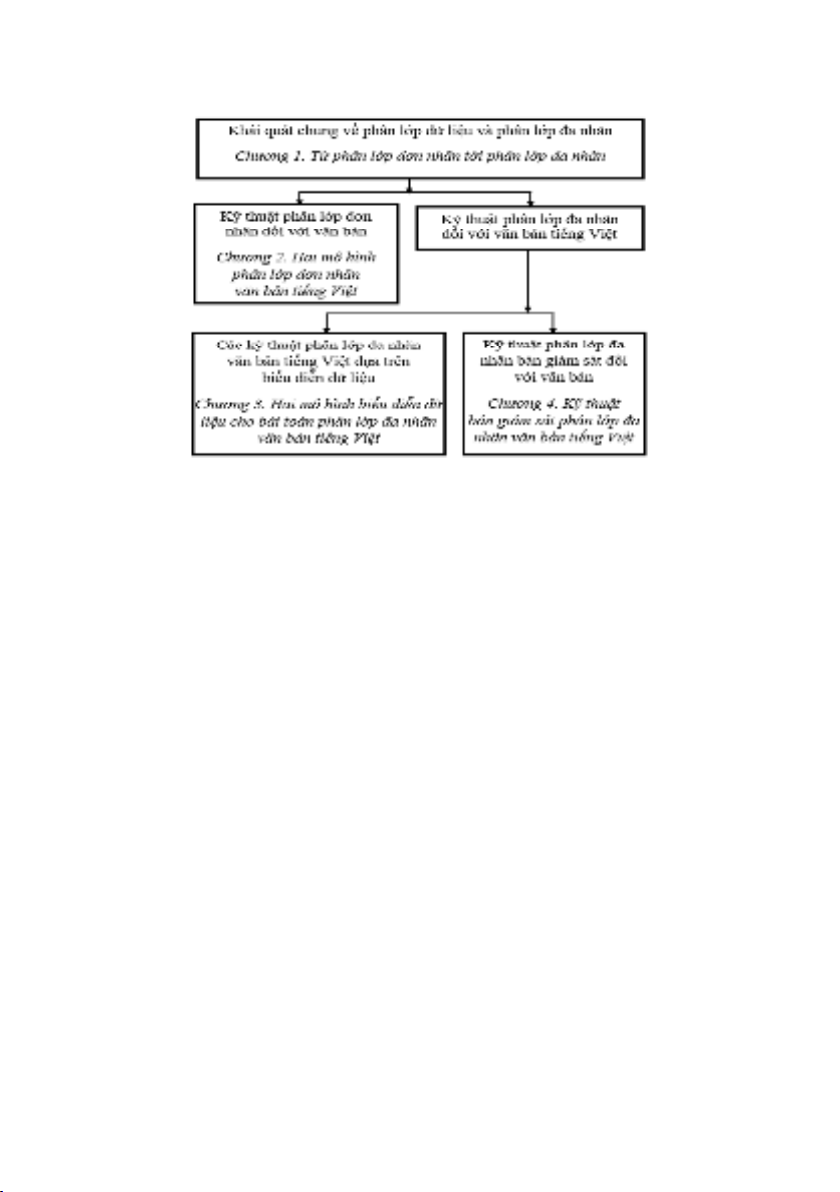
phần kết luận và danh mục tài liệu tham khảo. Hình 0.1 cung cấp một
khung nhìn sơ bộ về phân bố các chủ đề trong bốn chương của luận án.
Chương 1 cung cấp một khái quát từ phân lớp đơn nhãn tới phân lớp
đa nhãn; tập trung vào các vấn đề cơ bản của học đa nhãn bao gồm
phương pháp tiếp cận, rút gọn đặc trưng; độ đo và phương pháp đánh giá.
Chương 2 đề xuất hai mô hình phân lớp đơn nhãn thông qua hai
bài toán là gán nhãn thực thể có tên và hệ tư vấn xã hội tiếng Việt.
3
Hình 0.1 Phân bố các chủ đề trong các chương của luận án
Chương 3 đề xuất hai mô hình biểu diễn dữ liệu cho phân lớp đa
nhãn: sử dụng mô hình chủ đề ẩn LDA và mô hình đồ thị khoảng
cách kết hợp với mô hình LDA.
Chương 4 phân tích và đề xuất một tiếp cận phân lớp đa nhãn bán
giám sát với đặc trưng riêng biệt dựa trên kỹ thuật phân cụm.
Chương 1
TỪ PHÂN LỚP ĐƠN NHÃN TỚI PHÂN LỚP ĐA NHÃN
1.1. Từ phân lớp đơn nhãn đơn thể hiện tới phân lớp đa nhãn đa
thể hiện
Mục này cung cấp một khung tổng quát về sự tiến hóa trong bài
toán phân lớp từ phân lớp truyền thống đơn nhãn tới phân lớp đa
nhãn đơn thể hiện, phân lớp đơn nhãn đa thể hiện và phân lớp đa
nhãn đa thể hiện.
1.2. Giới thiệu chung về phân lớp đa nhãn
1.2.1. Kỹ thuật phân lớp đa nhãn
Kỹ thuật phân lớp đa nhãn được định hướng theo hai tiếp cận là

























