
Tuyển tập Hội nghị Khoa học thường niên năm 2024. ISBN: 978-604-82-8175-5
104
ỨNG DỤNG CÁC BIẾN THỂ CỦA MÔ HÌNH HỌC SÂU
TRANSFORMER TRONG DỰ BÁO LƯU LƯỢNG
ĐẾN HỒ TẢ TRẠCH
Nguyễn Đắc Hiếu1, Hoàng Hải Đăng1, Đoàn Anh Hoàng2, Nguyễn Đắc Phương Thảo1
1Trường Đại học Thủy lợi, email: dachieu@tlu.edu.vn
2Trung tâm Công nghệ Phần mềm Thuỷ lợi, email: doananhhoang@cwrs.vn
Tả Trạch là một trong những hồ thủy lợi lớn
nhất Việt Nam, đóng vai trò quan trọng trong
việc kiểm soát lũ lụt và cung cấp nước tưới
tiêu. Trong bối cảnh biến đổi khí hậu và nguy
cơ lũ lụt ngày càng gia tăng, việc áp dụng các
phương pháp dự báo hiện đại trở nên cấp thiết
để bảo đảm an toàn cho người dân và tài sản.
Mục tiêu của nghiên cứu là so sánh và đánh
giá hiệu suất của các biến thể Transformer
như Reformer, Informer, Autoformer, và
PatchTST, nhằm cải thiện độ chính xác và tính
ứng dụng trong dự báo lưu lượng nước.
1. GIỚI THIỆU CHUNG
Hồ thủy lợi Tả Trạch tại thị xã Hương
Thủy (Thừa Thiên - Huế) là một trong 4 hồ
thủy lợi lớn nhất cả nước, với dung tích 646
triệu m³, do Ban Quản lý đầu tư và Xây dựng
Thủy lợi 5 quản lý. Vào năm 2021, mức nước
trong hồ chứa nước Tả Trạch, Thừa Thiên
Huế cao hơn mức bình thường cho phép, gây
úng ngập hàng trăm héc-ta keo, tràm chuối
của người dân đang trồng quanh hồ. Việc
đảm bảo an toàn cho người dân và tài sản
thông qua dự báo lũ lụt là nhiệm vụ thiết yếu
hiện nay, vì lịch sử đã cho thấy lũ lụt gây ảnh
hưởng nghiêm trọng đến tài sản và tính mạng
con người.
2. PHƯƠNG PHÁP NGHIÊN CỨU
Về phương pháp nghiên cứu này áp dụng
những biến thể hiện đại nhất của mạng học máy
Transformer: Reformer, Informer, Autoformer
và PatchTST.
2.1. Reformer
Các mô hình Transformer [1] thường đạt
được kết quả tiên tiến nhất trên một số nhiệm
vụ, nhưng việc huấn luyện những mô hình
này có thể rất tốn kém, đặc biệt là trên các
chuỗi dài. Reformer [5] ra đời để cải thiện
hiệu quả của Transformer.
Hình 1. Kiến trúc Reformer
Hashing attention
Mỗi vector Query và Key được hash thành
nhóm nhất định sử dụng LSH. Hàm băm này
sẽ đảm bảo các vector gần nhau nhất trong
không gian vector và gom chúng thành 1
nhóm. Việc sử dụng hàm băm này sẽ giúp
giảm đáng kể lượng data trong quá trình
training từ đó tăng hiệu quả bởi các nhóm dữ
liệu gần nhau.
Sau đó chúng sẽ được sắp xếp theo nhóm
và thực hiện attention theo nhóm này từ đó
giúp giảm query từ O (L2) O(L log L).
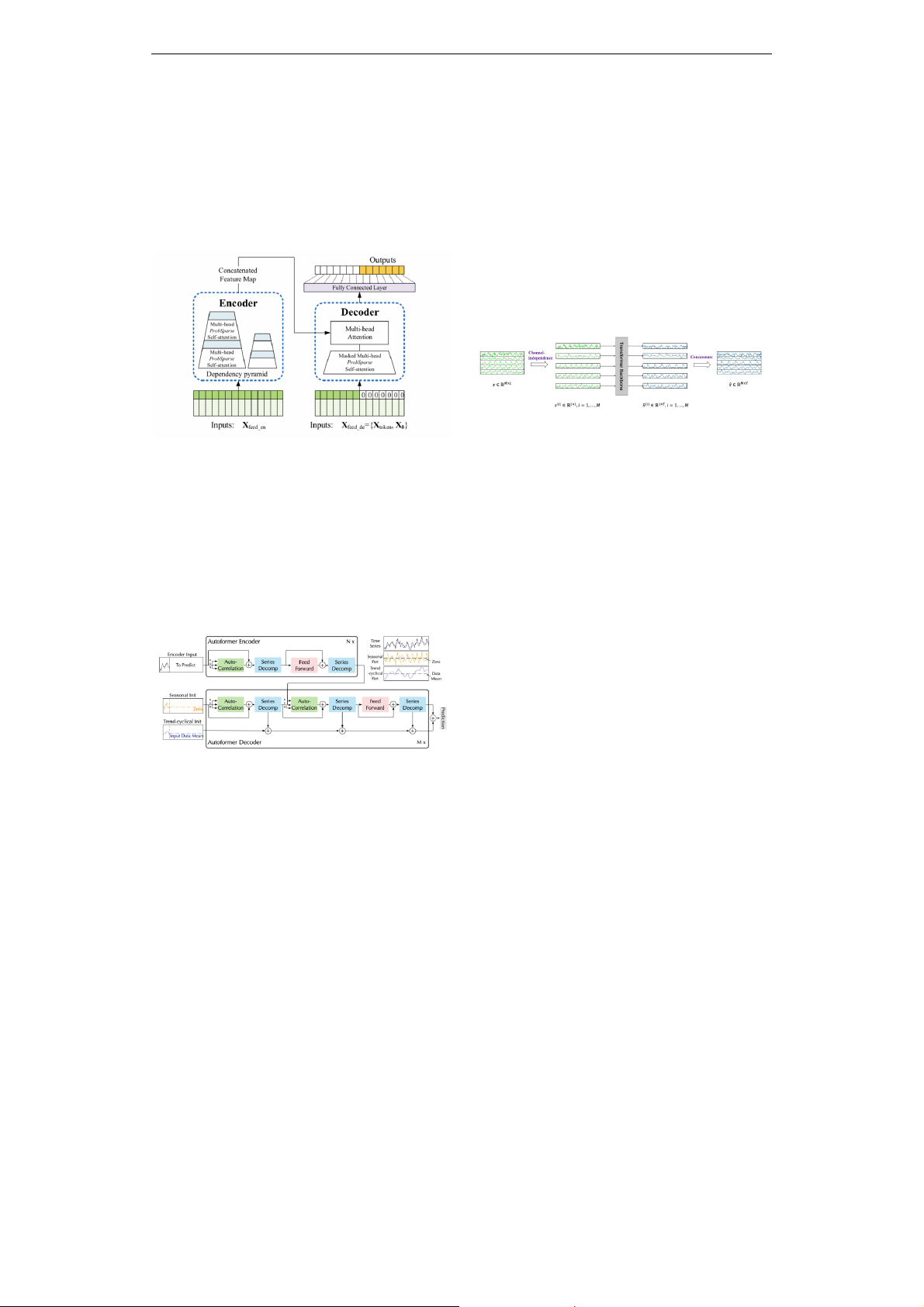
2.2. Informer
Dự đoán với chuỗi thời gian dài hạn là lý
do mà Informer [3] ra đời nhằm mục đích
thay thế những phương pháp cũ. Được xây
dựng trên nền tảng nổi tiếng Transformer,
Tuyển tập Hội nghị Khoa học thường niên năm 2024. ISBN: 978-604-82-8175-5
105
phương pháp Informer sinh ra với mục đích
giảm độ phức tạp thời gian cùng mức độ sử
dụng bộ nhớ cao hơn trong bài toán chuỗi
thời gian. Điểm đặc biệt so với những
phương pháp cũ là việc thiết lập số lượng các
điểm dữ liệu thời gian trong quá khứ để dự
đoán điểm thời gian tiếp theo việc thiết lập
này sẽ lấy rời rạc từng điểm data để thực hiện
cơ thế attention.
Hình 2. Kiến trúc Informer
2.3. Autoformer
Autoformer [2] mang lại kiến trúc khác so
với những phương pháp còn lại với cơ chế
attention trên miền dữ liệu cụ thể với 2 cơ
chế decomposition và auto-correalation với
độ phức tạp thuật toán là O(L log L).
Hình 3. Kiến trúc Autoformer
Cơ chế Auto-Correlation trong Autoformer
là một phương pháp mới để xử lý các mối
quan hệ phụ thuộc trong dữ liệu chuỗi thời
gian, mang lại những lợi thế so với các
phương pháp attention truyền thống. Trong
Transformer, trọng số chú ý được tính toán
trong miền thời gian và tổng hợp theo điểm.
Mặt khác, như có thể thấy trong hình trên,
Autoformer tính toán chúng trong miền chu
kỳ (sử dụng biến đổi phạm vi nhanh) và tổng
hợp chúng theo độ trễ thời gian.
2.4. PatchTST
Với ý tưởng bắt nguồn từ Vision Transformer
(ViT) trong xử lý ảnh. PatchTST [4] dựa trên
cơ chế chia dữ liệu thành các patch và thực
hiện attention trên các miền dữ liệu đó để
đảm bảo dữ liệu có tính liên kết với nhau cho
từng patch với. Tiếp sau đó kết hợp những
kết quả đã được attention lại với nhau. Độ
phức tạp thuật toán là O(L log L).
Hình 6. Kiến trúc PatchTST
3. KẾT QUẢ NGHIÊN CỨU
Dữ liệu lịch sử về thông tin lưu lượng
nước đến của hồ Tả Trạch được thu thập liên
tục từ 01/01/2017 đến ngày 31/12/2022, với
tổng số lượng dữ liệu là 52584 điểm dữ liệu,
bao gồm các số liệu quan trắc là lưu lượng
đến hồ, trạm đo mưa đầu mối, trạm đo mưa
đập thủy điện Thượng Nhật, trạm đo mưa lưu
vực thủy điện Thượng Nhật và trạm đo mưa
Khe Tre.
Để đánh giá độ chính xác mô hình, thực
nghiệm sử dụng thước đo MSE (Mean
Squared Error), MAE (Mean Absolute Error)
và R² (R-squared). Với MSE là trung bình
bình phương sai số giữa giá trị thực và giá trị
dự đoán, MAE đo sai số trung bình tuyệt đối
và R² đánh giá tỷ lệ giải thích của mô hình
ước lượng, với giá trị từ 0 đến 1. MSE và
MAE càng thấp, ngược lại R² càng cao, thì
mô hình càng chính xác.
Dữ liệu đầu vào của thực nghiệm bao gồm
24 mốc thời gian liên tiếp để dự đoán 4 mốc
thời gian là 1 giờ, 3 giờ, 6 giờ, 9 giờ trong
tương lai. Sau khi đào tạo dữ liệu trên 4 mô
hình PatchTST, Autoformer, Informer và
Reformer, thu được kết quả:
Tuyển tập Hội nghị Khoa học thường niên năm 2024. ISBN: 978-604-82-8175-5
106
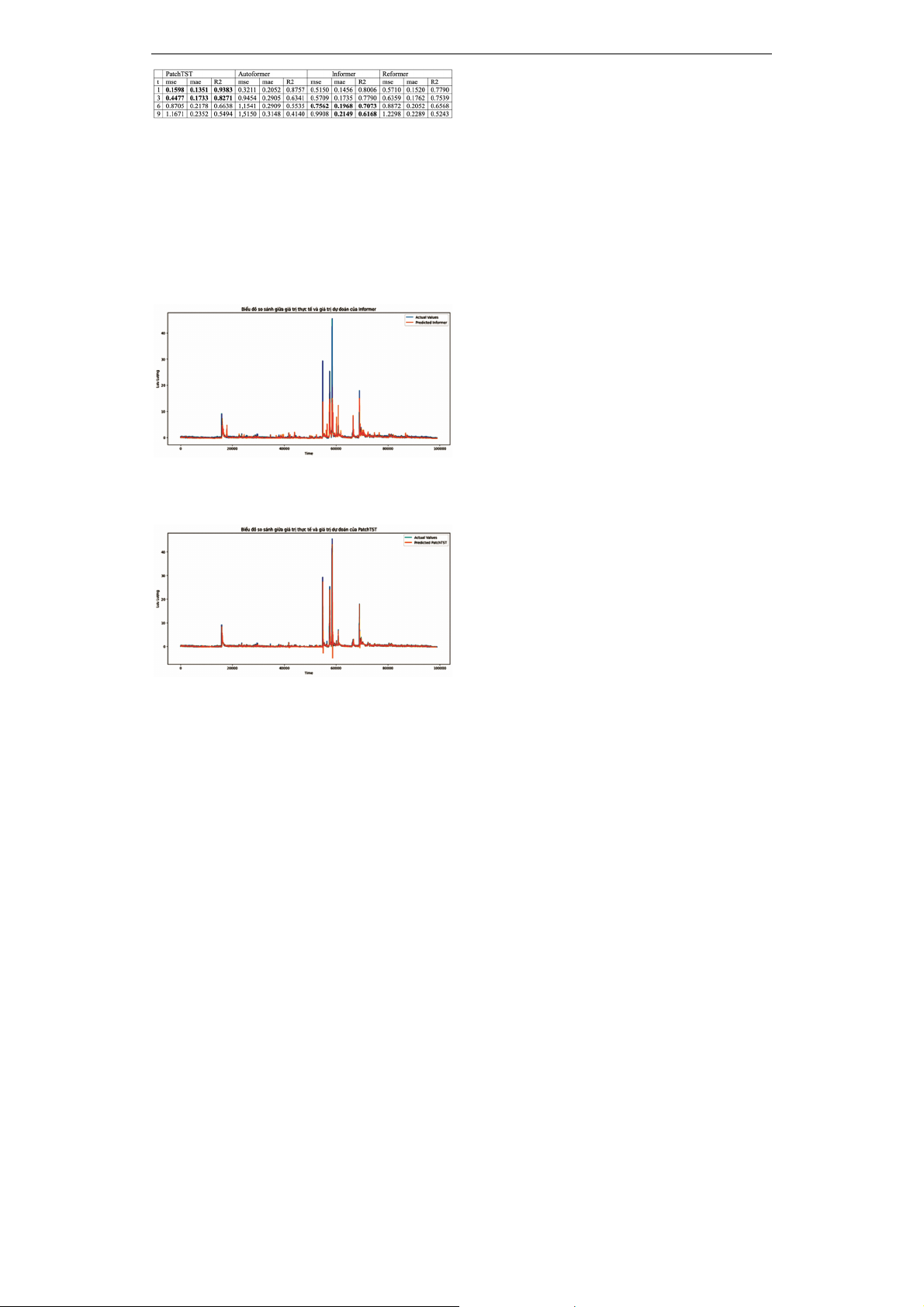
Hình 7. Kết quả thực nghiệm
Với mốc dự đoán lưu lượng nước tại mốc
thời gian gần 1 giờ và 3 giờ PatchTST đang
mang lại kết quả ưu việt hơn so với phương
pháp còn lại. Tại mốc thời gian 6 giờ và 9 giờ
Informer đang mang lại kết quả ưu việt hơn
so với phương pháp còn lại, nhưng dự báo
giá trị đỉnh không chính xác bằng PatchTST.
Hình 8. So sánh giá trị thực tế và dự đoán
Informer (dự đoán 9 giờ tiếp theo)
Hình 9. So sánh giá trị thực tế và dự đoán
PatchTST (dự đoán 9 giờ tiếp theo)
Kết luận, sau khi thử nghiệp trên 4 phương
pháp Reformer, Informer, Autoformer và
PatchTST để dự đoán mốc thời gian dài hạn.
PatchTST mang lại hiệu quả ưu việt hơn các
phương và tin cậy để thực nghiệm sử dụng
vào thực tế.
4. KẾT LUẬN
Trong bài báo này chúng tôi đã thử nghiệm
thành công các biến thể tiên tiến của mô hình
học sâu Transformer, bao gồm Reformer,
Informer, Autoformer và PatchTST, để dự
báo lưu lượng nước đến hồ Tả Trạch. Thực
nghiệm chỉ ra rằng PatchTST đạt kết quả tốt
nhất trên cả chỉ số độ đo sai số và dự báo
đỉnh lũ. Trong thời gian tới, chúng tôi sẽ
nghiên cứu các biến thể của Transformer và
các mô hình mạnh mạnh mẽ hơn trong việc
dự đoán mực nước.
5. TÀI LIỆU THAM KHẢO
[1] A. Vaswani, N. Shazeer, N. Parmar, J.
Uszkoreit, L. Jones, A. N. Gomez, and I.
Polosukhin. 2017. Attention is All You
Need. In I. Guyon, U. V. Luxburg, S.
Bengio, H. Wallach, R. Fergus, S.
Vishwanathan, and R. Garnett (Eds.),
Advances in Neural Information Processing
Systems, vol. 30.
[2] H. Wu, J. Xu, J. Wang, and M. Long. 2021.
Autoformer: Decomposition Transformers
with Auto-Correlation for Long-Term
Series Forecasting. Advances in Neural
Information Processing Systems (NeurIPS),
vol. 27, pp. 22419-22430.
[3] H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li,
H. Xiong, and W. Zhang. 2021. Informer:
Beyond Efficient Transformer for Long
Sequence Time-Series Forecasting. The
Thirty-Fifth AAAI Conference on Artificial
Intelligence (AAAI 2021), Virtual Conference,
vol. 35, pp. 11106-11115.
[4] Y. Nie, N. H. Nguyen, P. Sinthong,
and J. Kalagnanam. 2022. A Time
Series is Worth 64 Words: Long-term
Forecasting with Transformers. arXiv,
https://doi.org/10.48550/arxiv.2211.14730.
[5] N. Kitaev, Ł. Kaiser, and A. Levskaya. 2020.
Reformer: The Efficient Transformer. arXiv,
https://doi.org/10.48550/arxiv.2001.04451.













![Đề thi Con người và môi trường cuối kì 2 năm 2019-2020 có đáp án [kèm file tải]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20250523/oursky06/135x160/4691768897904.jpg)




![Đề cương ôn tập Giáo dục môi trường cho học sinh tiểu học [mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20251212/tambang1205/135x160/621768815662.jpg)






