Nội dung
Giới thiệu phân lớp
Phân lớp học giám sát
Phân lớp học bán giám sát
2

3
Phân lớp: Một vài bài toán ví dụ
⚫1. Bài toán phân lớp kết quả xét nghiệm
▪Miền dữ liệu I = {phiếu xét nghiệm},
▪Biến mục tiêu “tập hợp lớp” O = {dương tinh, âm tính}
▪Ánh xạ f: I →O, fchưa biết
▪Input: Tập ví dụ mẫu ILgồm phiếu xét nghiệm đã có nhãn
dương tình/âm tính.
▪Output: Ánh xạ xấp xỉ tốt nhất f* để xây dựng chương trình
tự động gán nhãn cho mọi phiếu xét nghiệm.
⚫2. Bài toán phân lớp cam kết khách hàng
▪Miền dữ liệu:Tập thông tin mua hàng khách hàng RFM
▪Mục tiêu “tập hợp lớp” O = {Trung thành cao, Trung thành
thấp, Bình thường}
▪Ánh xạ f: I →O, fchưa biết
▪Input: Tập ví dụ mẫu ILgồm khách hàng với RFM và nhãn
tương ứng.
▪Output: Ánh xạ xấp xỉ tốt nhất f* để xây dựng chương trình
tự động gán nhãn cho mọi khách hàng.

4
Phân lớp: Một vài bài toán ví dụ
⚫3. Bài toán phân lớp quan điểm
▪Miền dữ liệu I = {nhận xét sản phẩm A},
▪Mục tiêu “tập hợp lớp” O = {khen, chê}
▪Ánh xạ f: I →O, fchưa biết
▪Input: Tập ví dụ mẫu ILgồm đánh giá đã có nhãn khen/chê.
▪Output: Ánh xạ xấp xỉ tốt nhất f* để xây dựng chương trình
tự động gán nhãn cho mọi nhận xét.
⚫4. Bài toán phân lớp trang web
▪Miền dữ liệu:Tập các trang web miền lính vực quan tâm
▪Mục tiêu “tập hợp lớp” O = {Kinh tế, Thế giới, Thể thao, Giáo
dục, v.v.}
▪Ánh xạ f: I →O, fchưa biết
▪Input: Tập ví dụ mẫu ILgồm trang web có nhãn thuộc O.
▪Output: Ánh xạ xấp xỉ tốt nhất f* để xây dựng chương trình
tự động gán nhãn cho mọi trang web mới tải về.
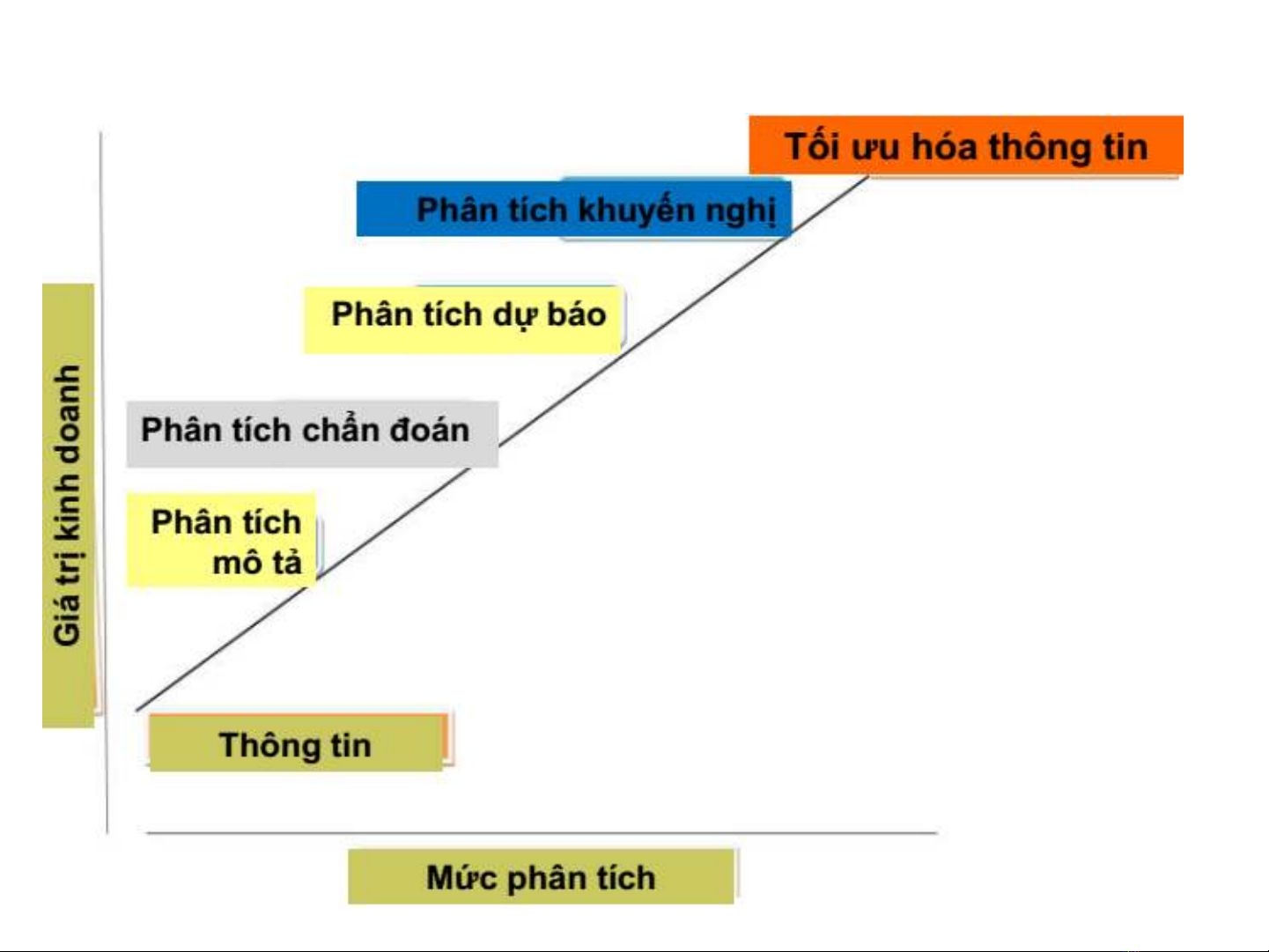
Các mức phân tích kinh doanh
5
Tối ưu hóa thông tin
Phân tích khuyến nghị
Phân tích dự báo
Phân tích chẩn đoán
Phân tích
mô tả
Thông tin
Giá trị kinh doanh
Điều gì đã xảy ra?
Vì sao điều đó xảy ra?
Khi nào nó sẽ xảy ra?
Làm gì khi nó xảy ra
một lần nữa?
-Hiểu sâu sắc thị trường và khách hàng,
-Hiểu vận hành nội bộ và nhân viên,
-Hiểu giá trị dữ liệu
KHAI PHÁ LUẬT KẾT HỢP
PHÂN CỤM
PHÂN LỚP