Giới thiệu tài liệu
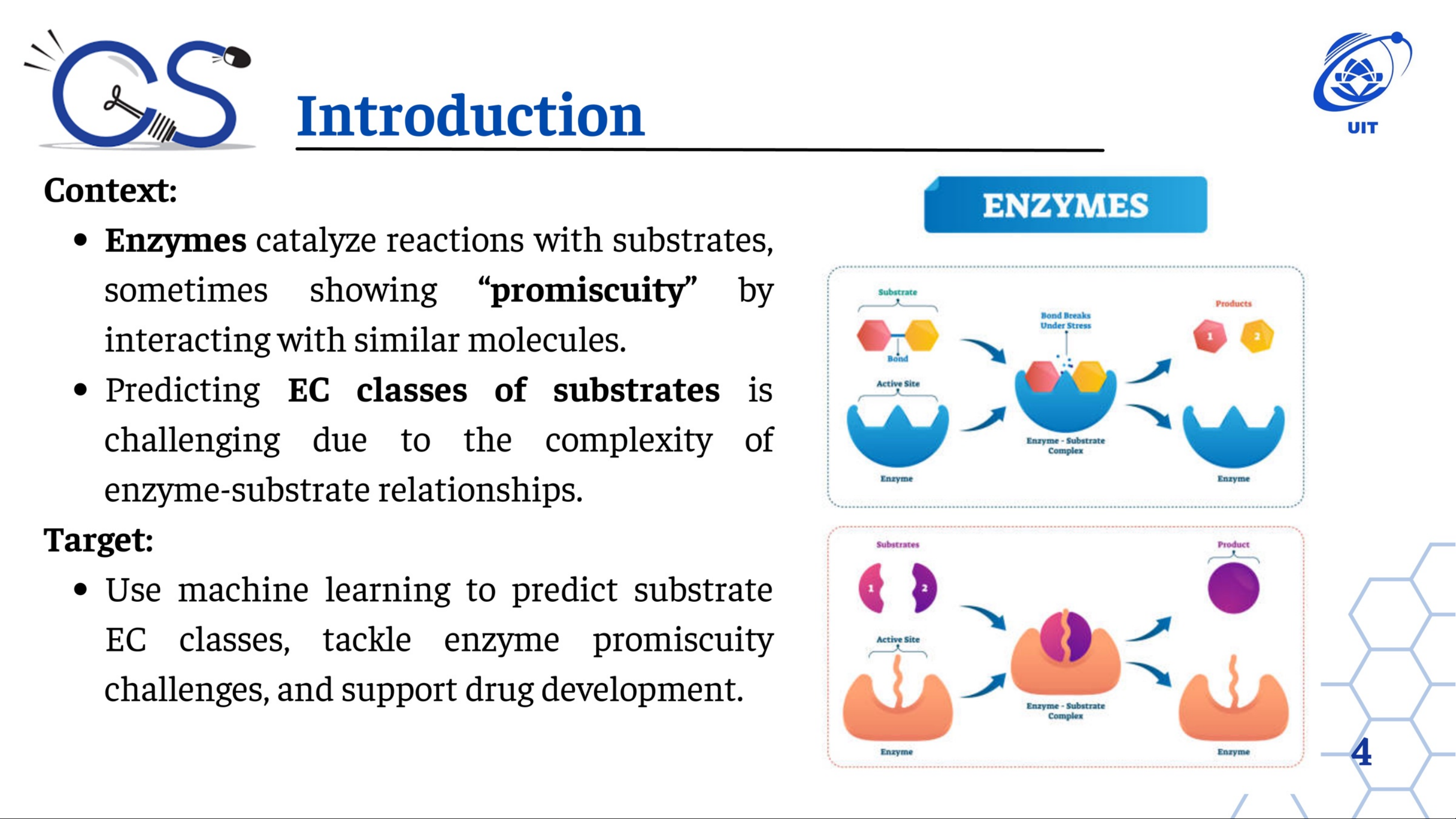
Bài trình bày này giới thiệu về việc phân loại đa nhãn các chất nền enzyme sử dụng khai phá dữ liệu và các thuật toán học máy. Mục tiêu là dự đoán các lớp EC (Enzyme Commission) của chất nền, giải quyết các thách thức về tính không đặc hiệu của enzyme và hỗ trợ phát triển thuốc.
Đối tượng sử dụng
Sinh viên và nhà nghiên cứu quan tâm đến khai phá dữ liệu, học máy và tin sinh học, đặc biệt là trong lĩnh vực enzyme và chất nền.
Nội dung tóm tắt
Bài trình bày này tập trung vào việc phân loại đa nhãn các chất nền enzyme, một vấn đề phức tạp do tính không đặc hiệu của enzyme và mối quan hệ phức tạp giữa enzyme và chất nền. Mục tiêu chính là sử dụng học máy để dự đoán các lớp EC của chất nền, từ đó giải quyết các thách thức liên quan đến tính không đặc hiệu của enzyme và hỗ trợ quá trình phát triển thuốc. Dữ liệu được sử dụng bao gồm 31 đặc trưng hóa học mô tả tính chất và cấu trúc của phân tử, cùng với 6 nhãn nhị phân tương ứng với 6 lớp EC. Các thuật toán học máy như XGBoost, SVM và MLP được áp dụng, kết hợp với các kỹ thuật tiền xử lý dữ liệu như xử lý ngoại lệ (IQR), biến đổi log và SMOTE để cải thiện hiệu suất mô hình. Bài trình bày cũng đề cập đến việc lựa chọn đặc trưng bằng Random Forest và RFE, cũng như việc tăng cường đặc trưng bằng cách tạo thêm các đặc trưng mới từ các đặc trưng quan trọng. Kết quả cho thấy việc kết hợp các phương pháp này với XGBoost cải thiện đáng kể khả năng dự đoán lớp EC, nhấn mạnh tiềm năng của mô hình và sự cần thiết của việc tiền xử lý dữ liệu phù hợp để giải quyết các thách thức trong dữ liệu thực tế. Các hướng nghiên cứu tương lai bao gồm thử nghiệm với các kỹ thuật xử lý dữ liệu khác và mở rộng mô hình với các thuật toán học máy khác.