
Khai Phá Dữ Liệu
Nguyễn Nhật Quang
quangnn-fit@mail.hut.edu.vn
Viện Công nghệ Thông tin và Truyền thông
Trường Đại học Bách Khoa Hà Nội
Năm học 2010-2011

Nội dung môn học:
Giới thiệu về Khai phá dữ liệu
ề
Giới thiệu v
ề
công cụ WEK
A
Tiền xử lý dữ liệu
Phát hiện các luật kết hợp
Các kỹthuật phân lớpvàdự đoán
Các
kỹ
thuật
phân
lớp
và
dự
đoán
Học dựa trên các láng giềng gần nhất
Học bằng mạng nơ-ron nhân tạo
Các kỹ thuật phân nhóm
2
Khai Phá Dữ Liệu

Học dựa trên các láng giềng gần nhất
Một số tên gọi khác của phương pháp học dựa trên các láng
giềng gần nhất (Nearest neighbor learning)
•Instance-based learning
•Lazy learning
•
Memory
-
based learning
Memory
based
learning
Ý tưởng của phương pháp học dựa trên các láng giềng gần nhất
•Với m
ộ
t t
ập
các ví d
ụ
h
ọ
c
ộ ậpụ ọ
─(Đơn giản là) lưu lại các ví dụ học
─Không cần xây dựng một mô hình (mô tả) rõ ràng và tổng quát
của hàm mụctiêucầnhọc
của
hàm
mục
tiêu
cần
học
•Đối với một ví dụ cần phân loại/dự đoán
─Xét quan hệ giữa ví dụ đó với các ví dụ học để gán giá trị của
hàm mục tiêu (một nhãn lớp, hoặc một giá trị thực)
3
Khai Phá Dữ Liệu

Học dựa trên các láng giềng gần nhất
Biểu diễn đầu vào của bài toán
•Mỗi ví dụ xđược biểu diễn là một vectơ
n
chiều tron
g
khôn
g
g
ian
ggg
các vectơ X∈Rn
•x= (x1,x2,…,xn), trong đó xi(∈R) là một số thực
Cể ả ể
C
ó th
ể
áp dụng được với c
ả
2 ki
ể
u bài toán học
•Bài toán phân lớp (classification)
─
Hàm m
ụ
c tiêu có
g
iá tr
ị
rời r
ạ
c
(
a discrete-valued tar
g
et function
)
ụgị ạ (
g)
─Đầu ra của hệ thống là một trong số các giá trị rời rạc đã xác định
trước (một trong các nhãn lớp)
•
Bài toán
dự đoán/hồi quy (prediction/regression)
•
Bài
toán
dự
đoán/hồi
quy
(prediction/regression)
─Hàm mục tiêu có giá trị liên tục (a continuous-valued target function)
─Đầu ra của hệ thống là một giá trị số thực
4
Khai Phá Dữ Liệu
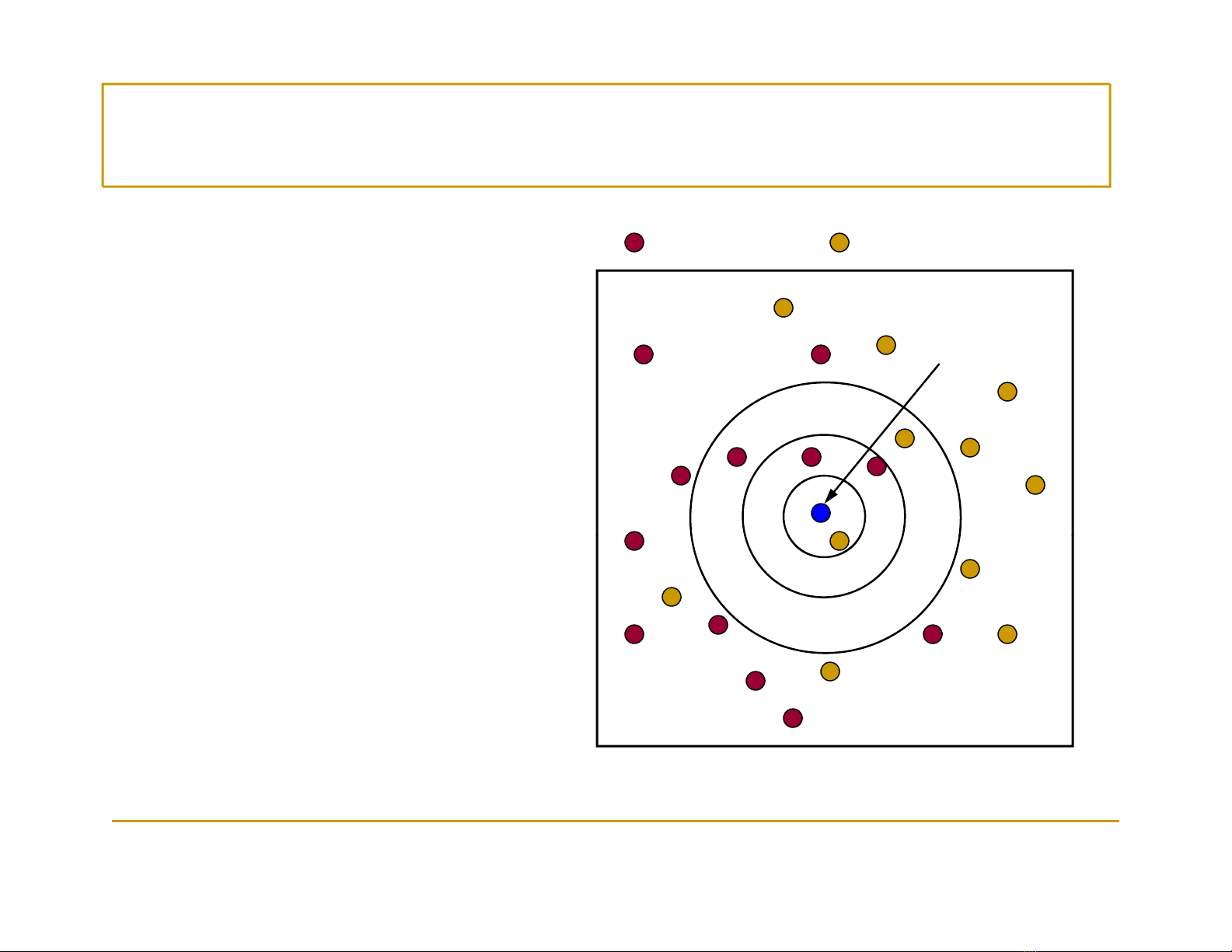
Ví dụbài toán phân lớp
Xét 1 láng giềng gầnLớp c1 Lớp c2
nhất
→Gán zvào lớpc2
Ví dụ cần
phân lớp z
Xét 3 láng giềng gần
nhất
→
Gán
z
vào
lớp
c1
→
Gán
z
vào
lớp
c1
Xét 5 láng giềng gần
nhất
nhất
→Gán zvào lớpc1
5
Khai Phá Dữ Liệu






![Bài giảng Khai phá dữ liệu (Data mining): Introduction - Trịnh Tấn Đạt [Mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2023/20230918/diepkhinhchau/135x160/1792158917.jpg)





![Câu hỏi trắc nghiệm Lập trình C [mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20251012/quangle7706@gmail.com/135x160/91191760326106.jpg)












