
Phân tích dữ liệu môi trường truyền thông xã hội và
dữ liệu có cấu trúc với BigInsights InfoSphere
Bạn có thể đã nghe nói về Big Data (dữ liệu lớn) và tác động của nó đối với việc phân tích kinh
doanh. Và có lẽ bạn đang tự hỏi tổ chức của mình có thể thu nhặt được những hiểu biết gì từ việc
nắm bắt, xử lý và quản lý dữ liệu lớn được thu thập từ các trang web, các cảm biến điện tử hoặc
các bản ghi nhật ký phần mềm, cùng với các dữ liệu truyền thống mà bạn đã có. Chắc chắn,
không thiếu các dự án của bên thứ ba và nguồn mở được thiết kế để giúp bạn giải quyết các khía
cạnh khác nhau của các dự án Big Data của mình. Nhưng hầu hết các dự án đều được hướng về
phía các lập trình viên, các quản trị viên và các chuyên gia kỹ thuật với các kỹ năng cụ thể.
Điều gì sẽ xảy ra nếu bạn muốn làm cho Big Data có thể tới được các nhà phân tích kinh doanh,
các nhà lãnh đạo ngành kinh doanh và các nhân viên khác, những người không phải là các lập
trình viên? BigSheets đáng giá hơn vẻ bề ngoài của nó. Đó là một công cụ kiểu-bảng tính đi kèm
với InfoSphere BigInsights, cho phép những người không phải là lập trình viên có thể khám phá,
thao tác và hiển thị trực quan dữ liệu được lưu trữ trong hệ thống tệp phân tán của bạn. Các ứng
dụng ví dụ mẫu kèm theo BigInsights giúp bạn thu thập và nhập dữ liệu từ nhiều nguồn khác
nhau. Trong bài này, chúng tôi sẽ giới thiệu cho bạn về BigSheets và hai ứng dụng ví dụ mẫu đi
kèm theo nó.
Nền tảng
BigInsights là một nền tảng phần mềm có thể giúp các công ty phát hiện và phân tích những hiểu
biết kinh doanh ẩn dấu trong các khối lượng lớn của rất nhiều lĩnh vực dữ liệu — dữ liệu thường
bị bỏ qua hoặc bị vứt bỏ vì nó quá không thực tế hoặc quá khó xử lý bằng cách sử dụng các
phương tiện truyền thống.
Để giúp các doanh nghiệp lấy được giá trị từ những dữ liệu đó một cách hiệu quả, Ấn bản Doanh
nghiệp của BigInsights bao gồm một số dự án nguồn mở, gồm có Apache Hadoop và một số
công nghệ đã phát triển của IBM, gồm BigSheets. Hadoop và các dự án liên quan của nó cung
cấp một framework phần mềm hiệu quả cho các ứng dụng chuyên về dữ liệu, khai thác các môi
trường tính toán phân tán để đạt được khả năng mở rộng quy mô cao.
Các công nghệ của IBM làm phong phú thêm framework nguồn mở này với phần mềm phân
tích, tích hợp phần mềm doanh nghiệp, các phần mở rộng nền tảng và các công cụ. Để biết thêm
thông tin về BigInsights, hãy xem phần Tài nguyên. BigSheets là một công cụ phân tích dựa trên
trình duyệt ban đầu được nhóm Emerging Technologies của IBM phát triển. Hiện nay, BigSheets
được gắn với BigInsights để cho phép những người dùng doanh nghiệp và không phải là lập
trình viên khám phá và phân tích dữ liệu trong các hệ thống tệp phân tán. BigSheets trình bày
một giao diện như-bảng tính để người dùng có thể mô hình hóa, lọc, kết hợp, khám phá và vẽ
biểu đồ dữ liệu được thu thập từ nhiều nguồn khác nhau. Giao diện bàn điều khiển web của
BigInsights gồm có một ngăn (tab) ở trên đỉnh để truy cập BigSheets. Xem phần Tài nguyên để
biết thêm chi tiết về giao diện bàn điều khiển web này.

Hình 1 mô tả một bộ sưu tập dữ liệu ví dụ mẫu trong BigSheets. Trong khi nó trông giống như
một bảng tính điển hình, bộ sưu tập này chứa các dữ liệu từ các blog được đăng lên các trang
web công cộng và các nhà phân tích thậm chí có thể nhấn chuột vào các liên kết có trong bộ sưu
tập để truy cập vào trang web đã xuất bản nội dung nguồn.
Hình 1. Bộ sưu tập ví dụ mẫu BigSheets dựa trên dữ liệu của môi trường truyền thông xã
hội, có các liên kết đến nội dung nguồn
Sau khi định nghĩa một bộ sưu tập BigSheets, một nhà phân tích có thể lọc hoặc chuyển đổi dữ
liệu của nó như mong muốn. Ở hậu trường, BigSheets dịch các lệnh của người dùng, được thể
hiện thông qua một giao diện đồ họa, thành các kịch bản lệnh Pig được thực hiện dựa vào một
tập hợp con của các dữ liệu bên dưới. Theo cách này, một nhà phân tích có thể nhiều lần khám
phá các biến đổi khác nhau một cách hiệu quả. Khi đã hài lòng, người sử dụng có thể lưu và chạy
bộ sưu tập, làm cho BigSheets bắt đầu công việc MapReduce trên bộ dữ liệu đầy đủ, viết các kết
quả vào hệ thống tệp phân tán và hiển thị các nội dung của bộ sưu tập mới. Các nhà phân tích có
thể lật trang và thao tác tập hợp dữ liệu đầy đủ như mong muốn.
Bổ sung cho BigSheets là một số ứng dụng ví dụ mẫu đã dựng sẵn mà những người dùng doanh
nghiệp có thể khởi chạy chúng từ giao diện bàn điều khiển web của BigInsights để thu thập dữ
liệu từ các trang web, các hệ thống quản lý cơ sở dữ liệu quan hệ (RDBMS), các hệ thống tệp từ
xa và các nguồn khác. Chúng tôi sẽ dựa vào hai ứng dụng như vậy cho công việc được mô tả ở
đây. Tuy nhiên, điều quan trọng cần hiểu rõ là các lập trình viên và các quản trị viên có thể sử
dụng các công nghệ BigInsights khác để thu thập, xử lý và chuẩn bị dữ liệu cho việc phân tích
tiếp theo trong BigSheets. Các công nghệ này gồm có Jaql, Flume, Pig, Hive, các ứng dụng
MapReduce và các công nghệ khác.
IBM Watson

IBM Watson là một dự án nghiên cứu mà nó thực hiện các phân tích phức tạp để trả lời các câu
hỏi được trình bày theo một ngôn ngữ tự nhiên. Phần mềm của Watson tra cứu dữ liệu được thu
thập từ nhiều nguồn khác nhau và sử dụng Hadoop để xử lý hiệu quả dữ liệu này qua một hệ
thống các máy chủ IBM Power 750. IBM Watson đầu tiên được dùng trong một cuộc thi trò chơi
trên truyền hình vào năm 2011, đánh bại hai người chơi dẫn đầu. Xem phần Tài nguyên để biết
thêm các chi tiết về IBM Watson và chương trình trò chơi Jeopardy!.
Trước khi bắt đầu, chúng ta hãy xem xét các kịch bản ứng dụng ví dụ mẫu. Việc này đòi hỏi
phân tích dữ liệu của môi trường truyền thông xã hội về IBM Watson và, cuối cùng, nối dữ liệu
này với dữ liệu nội bộ của IBM đã mô phỏng về các nỗ lực tiếp cận môi trường truyền thông
được trích ra từ một DBMS quan hệ. Ý tưởng là khám phá khả năng hiển thị, đưa tin và "lan
truyền" xung quanh một nhãn hàng, dịch vụ hay dự án nổi bật — một yêu cầu chung trong nhiều
tổ chức. Chúng tôi sẽ không trình bày hết các khả năng phân tích cho một ứng dụng như vậy ở
đây, do ý định của chúng tôi chỉ đơn giản là nêu bật cách các khía cạnh quan trọng của BigSheets
có thể giúp các nhà phân tích bắt đầu nhanh chóng công việc với dữ liệu lớn như thế nào. Tuy
nhiên, công việc mà chúng ta sẽ tìm hiểu sẽ giúp bạn hiểu những gì là có thể với một chút nỗ lực
— và có lẽ mang đến một hay hai bất ngờ về sự nổi tiếng của IBM Watson.
Về đầu trang
Bước 1: Thu thập dữ liệu của bạn
Trước khi khởi chạy BigSheets, bạn cần một số dữ liệu dùng cho việc phân tích của mình. Trước
hết, chúng ta sẽ tập trung vào việc thu thập dữ liệu của môi trường truyền thông xã hội.
Thu thập dữ liệu của môi trường truyền thông xã hội
Như bạn có thể dự kiến, việc thu thập và xử lý dữ liệu được trích ra từ các trang web của môi
trường truyền thông xã hội có thể là thách thức, do các trang web khác nhau nắm giữ thông tin
khác nhau và sử dụng các cấu trúc dữ liệu khác nhau. Hơn nữa, việc xác định và dò tìm qua rất
nhiều các trang web cá nhân có thể rất tốn thời gian.
Ở đây, chúng tôi đã sử dụng ứng dụng ví dụ mẫu BoardReader kèm theo BigInsights để khởi
chạy một tìm kiếm về các blog, các nguồn cấp tin tức, các diễn đàn thảo luận và các trang web
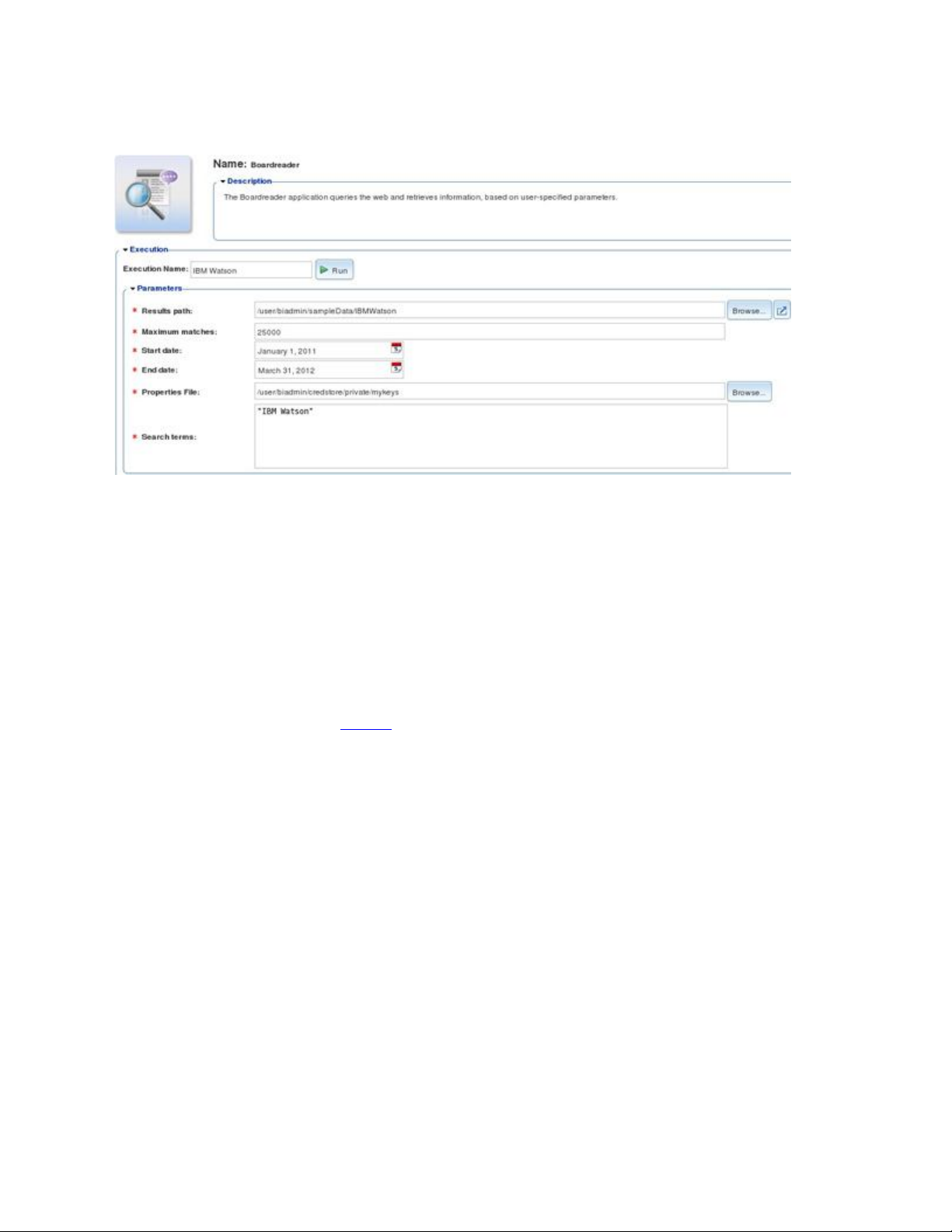
video. Hình 2 minh họa các tham số đầu vào mà chúng tôi đã cung cấp cho ứng dụng
BoardReader của BigInsights, chúng tôi đã khởi chạy nó từ trang Applications (Các ứng dụng
của) giao diện bàn điều khiển Web của BigInsights. Nếu bạn chưa quen với giao diện bàn điều
khiển web và danh mục các ứng dụng mẫu của nó, hãy xem phần Tài nguyên.
Hình 2. Gọi ứng dụng BoardReader từ giao diện bàn điều khiển web BigInsights
Hãy xem xét nhanh các tham số đầu vào được hiển thị trong Hình 2. Results Path (Đường dẫn
Các kết quả) chỉ rõ thư mục của hệ thống tệp phân tán Hadoop (HDFS) với kết quả của của ứng
dụng. Các tham số tiếp theo cho biết rằng chúng tôi đã hạn chế các kết quả được trả về tới tối đa
là 25.000 kết quả phù hợp và khoảng thời gian tìm kiếm bắt đầu từ 01.01.2011 đến cuối
31.03.2012. Properties File (Tệp Đặc tính) tham khảo kho lưu trữ thông tin của BigInsights mà
chúng tôi đã điền vào bằng khóa bản quyền của BoardReader của chúng tôi. (Mỗi khách hàng
phải liên hệ với BoardReader để nhận được một khóa bản quyền hợp lệ). Và "IBM Watson" là
chủ đề tìm kiếm của chúng ta.
Sau khi chạy ứng dụng, hệ thống tệp phân tán có chứa bốn tệp mới trong thư mục kết quả, như
được hiển thị ở dưới cùng của Hình 3.
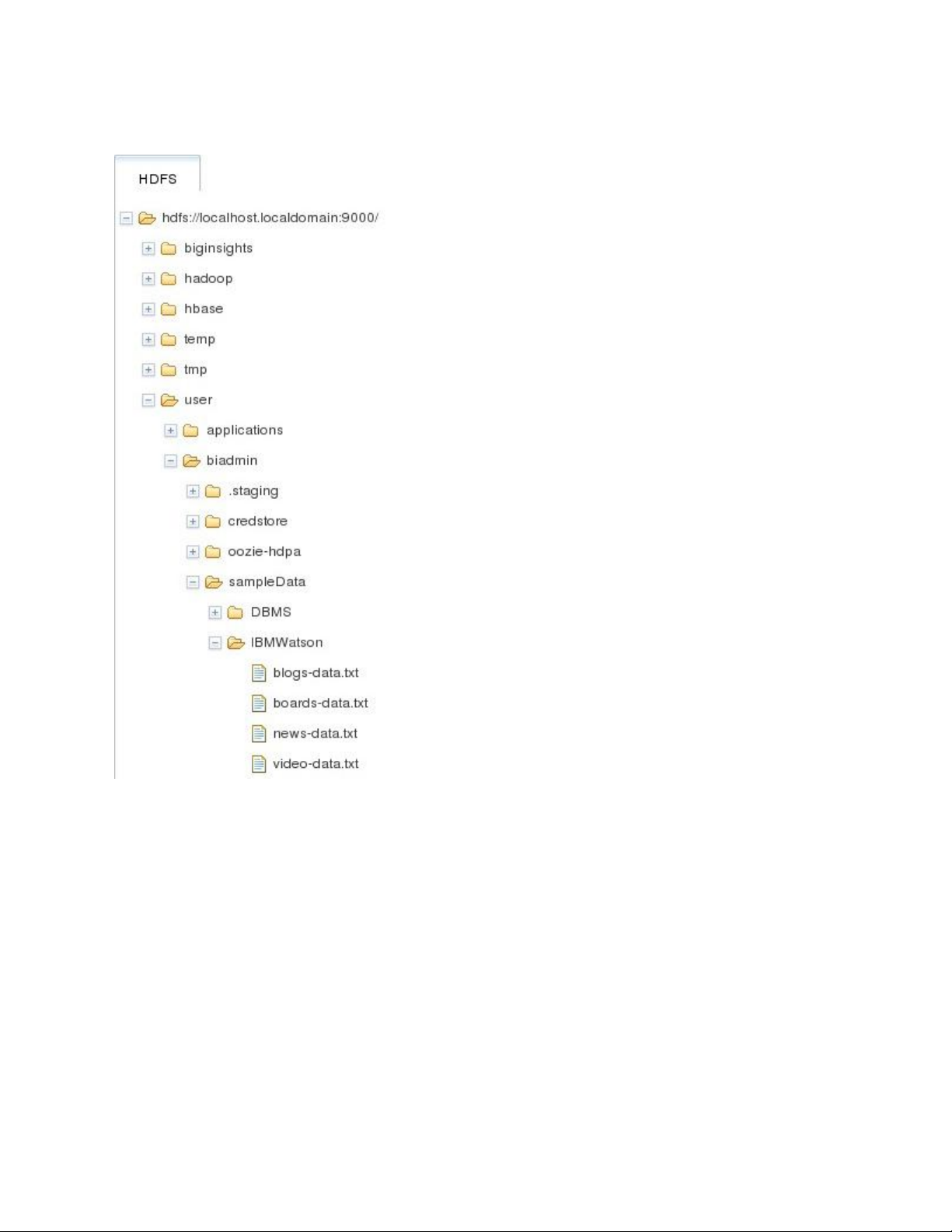
Hình 3. Kết quả của ứng dụng được lưu trữ trong BigInsights
Để giữ cho mọi thứ đơn giản, trong bài này, chúng tôi sẽ chỉ sử dụng dữ liệu tin tức và blog. Nếu
bạn muốn làm theo cùng với kịch bản ứng dụng ví dụ mẫu của chúng tôi, hãy thực hiện các ứng
dụng BoardReader với các tham số mà chúng tôi đã quy định hoặc tải về dữ liệu ví dụ mẫu. Lưu
ý rằng việc tệp tải xuống chỉ chứa một tập hợp con thông tin mà BoardReader thu thập từ các
nguồn cấp tin tức và các blog. Cụ thể là, chúng tôi đã loại bỏ nội dung toàn văn bản/HTML của
các bài đăng và các mục tin tức cũng như siêu dữ liệu cụ thể từ các tệp mẫu. Dữ liệu này không
cần thiết cho các nhiệm vụ phân tích được trình bày ở đây và chúng tôi cũng muốn giữ cho kích
cỡ của mỗi tệp ở mức dễ sử dụng.
Mỗi tệp được ứng dụng BoardReader trả về đều theo định dạng JSON. Bạn có thể hiển thị một
phần nhỏ của dữ liệu này như là văn bản trong trang Files (Các tệp) của giao diện bàn điều khiển
web của BigInsights, nhưng khó đọc các kết quả. Lúc này, bạn sẽ thấy cách chuyển đổi dữ liệu
này thành "các trang bảng tính" hoặc các bộ sưu tập dữ liệu BigSheets, đó là cách dễ hơn nhiều
để tìm hiểu. Nhưng điều đáng lưu ý là mỗi tệp có chứa một cấu trúc JSON hơi khác một chút —






![Mô Hình Chất Lượng Nước: Chương 5 [Phân Tích Chi Tiết]](https://cdn.tailieu.vn/images/document/thumbnail/2011/20110725/suatuoiconbo/135x160/mo_hinh_chat_luong_nc_5_0655.jpg)





![Bài giảng Hoá kỹ thuật môi trường 2 - Đại học Xây dựng Miền Tây [Mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260512/hoatulip0906/135x160/59431778724718.jpg)










![Giáo trình Tài nguyên năng lượng và bảo vệ môi trường - Trường CĐ Cơ điện Hà Nội [Mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260323/lionelmessi01/135x160/8121774378783.jpg)
![Đề cương bài giảng Kỹ thuật xử lý môi trường - Trường Cao đẳng Cơ điện Hà Nội [Chuẩn nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260323/lionelmessi01/135x160/75051774429892.jpg)

%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23fff;%20}%20.st1%20{%20fill:%20%237800fa;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st1'%20d='M117.78,12.18H43.11c2.9,3.47,4.65,7.94,4.65,12.82,0,5.6-2.3,10.66-6.01,14.29h76.02l7.22-13.56-7.22-13.56Z'/%3e%3cg%3e%3cpath%20class='st0'%20d='M53.58,26.17h-.59v-1.46h.59v-4.96h2.83c1.78,0,2.67.94,2.67,2.82v5.76c0,1.87-.89,2.81-2.67,2.81h-2.83v-4.96ZM55.36,21.37v3.34h1.1v1.46h-1.1v3.34h1.01c.61,0,.91-.37.91-1.1v-5.93c0-.74-.3-1.1-.91-1.1h-1.01Z'/%3e%3cpath%20class='st0'%20d='M65.99,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM65.28,18.04c-.25.46-.51.77-.75.94-.21.15-.47.22-.79.22-.26,0-.57-.07-.92-.22l-.38-.15c-.14-.05-.26-.07-.37-.07-.3,0-.53.18-.71.54l-.91-.68c.25-.46.51-.77.75-.94.21-.14.48-.21.79-.21.26,0,.57.07.92.21l.38.15c.14.05.26.07.37.07.3,0,.53-.18.71-.54l.91.68ZM61.91,27.52h1.73l-.87-5.76-.87,5.76Z'/%3e%3cpath%20class='st0'%20d='M74.53,26.89v1.52c0,1.91-.89,2.86-2.67,2.86s-2.67-.95-2.67-2.86v-5.93c0-1.91.89-2.86,2.67-2.86s2.67.95,2.67,2.86v1.11h-1.69v-1.22c0-.75-.31-1.12-.93-1.12s-.93.37-.93,1.12v6.15c0,.74.31,1.11.93,1.11s.93-.37.93-1.11v-1.63h1.69Z'/%3e%3cpath%20class='st0'%20d='M81.4,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM75.9,19.2l1.52-1.91h1.71l1.51,1.91h-1.61l-.76-.95-.75.95h-1.61ZM77.32,27.52h1.73l-.87-5.76-.87,5.76ZM83.1,15.99l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M84.86,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM84.01,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M93.51,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM92.66,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M98.8,31.14h-1.79v-11.39h1.79v4.88h2.03v-4.88h1.83v11.39h-1.83v-4.88h-2.03v4.88Z'/%3e%3cpath%20class='st0'%20d='M105.36,24.55h2.46v1.62h-2.46v3.34h3.09v1.63h-4.88v-11.39h4.88v1.63h-3.09v3.18ZM108.17,17.29l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M112.2,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM111.35,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3c/g%3e%3ccircle%20class='st1'%20cx='25'%20cy='25'%20r='20'/%3e%3cpath%20class='st0'%20d='M32.78,19.27c2.92,0,4.43,2.55,5.28,5.33l.71,2.17c.14.38-.33.75-.71.75h-5.61c.19-.33.24-.71.09-1.08l-.75-2.45c-.43-1.32-.99-2.64-1.79-3.77.75-.57,1.65-.94,2.78-.94h0ZM25,18.38c3.25,0,4.9,2.78,5.89,5.89l.76,2.45c.14.42-.33.8-.8.8h-11.69c-.42,0-.94-.38-.8-.8l.75-2.45c.99-3.11,2.64-5.89,5.89-5.89h0ZM25,11.35c1.74,0,3.11,1.37,3.11,3.11s-1.37,3.11-3.11,3.11-3.11-1.41-3.11-3.11,1.41-3.11,3.11-3.11h0ZM17.27,19.27c1.08,0,1.98.38,2.73.94-.8,1.13-1.37,2.45-1.74,3.77l-.8,2.45c-.14.38-.05.75.09,1.08h-5.56c-.42,0-.9-.38-.75-.75l.71-2.17c.9-2.78,2.41-5.33,5.33-5.33h0ZM17.27,12.91c1.51,0,2.78,1.27,2.78,2.83s-1.27,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM32.78,12.91c1.56,0,2.78,1.27,2.78,2.83s-1.23,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM27.07,28.56v.09c0,.57-.24,1.08-.61,1.46h0v.05c-.38.33-.9.57-1.46.57s-1.08-.24-1.46-.61h0c-.38-.38-.61-.9-.61-1.46v-.09h1.41v.09c0,.19.05.38.19.47v.05c.09.09.28.19.47.19s.38-.09.47-.19v-.05c.14-.09.24-.28.24-.47t-.05-.09h1.41ZM30.99,28.56v.09c0,1.65-.66,3.16-1.74,4.24-1.08,1.08-2.59,1.79-4.24,1.79s-3.16-.71-4.24-1.79l-.05-.05c-1.04-1.08-1.7-2.55-1.7-4.2v-.09h1.41v.09c0,1.27.47,2.4,1.27,3.25h.05c.85.85,1.98,1.37,3.25,1.37s2.4-.52,3.25-1.37c.85-.8,1.37-1.98,1.37-3.25v-.09h1.37ZM34.99,28.56v.09c0,2.78-1.13,5.28-2.92,7.07-1.79,1.79-4.29,2.92-7.07,2.92s-5.23-1.13-7.07-2.92c-1.79-1.79-2.92-4.29-2.92-7.07v-.09h1.41v.09c0,2.4.94,4.53,2.5,6.08,1.56,1.56,3.72,2.5,6.08,2.5s4.52-.94,6.08-2.5c1.56-1.56,2.5-3.68,2.5-6.08v-.09h1.41Z'/%3e%3c/svg%3e)