
1
Chương 4
Lưu trữ dữ liệu vật lý &Lưu trữ dữ liệu vật lý &
Các phương pháp truy xuấtCác phương pháp truy xuất
1
Nội dung
1. Một số khái niệm
2. Cách tổ chức file và phương pháp truy
xuất
3. Index
2
2
Các phương tiện lưu trữ DL
Cache (RAM)
Main memor
y
(
DRAM
)
Primary storage
Volatile storage:
mất thông tin khi
mất nguồn
CPU sử dụng để thi hành CT nhanh
CPU dùng DRAM để làm nơi load
CàC
y( )
Flash memory (MP3, USB)
Magnetic disk
Secondary storage/
On-line storage
Nonvolatile
storage
CT
+
DL
, t
hi
hà
n
h
CT
3
Optical disk (CD-ROM)
Magnetic tapes
Tốc độ
Giá thành
Tertiary storage/
Off-line storage
Storage Capacity
1015
nearline
tape &
optical
offline
tape
)
1013
1011
109
107
electronic
main
electronic
secondary
magnetic
optical
disks
online
tape
disks
c
al capacity (bytes
)
fG&Rt
4
10-9 10-6 10-3 10-0 103
access time (sec)
105
103
cache
typi
c
f
rom
G
ray
&
R
eu
t
e
r
3
Storage Cost
104cache
electronic
li
from Gray & Reuter
102
100
10-2
mainelectronic
secondary
magnetic
optical
disks
on
li
ne
tape
nearline
tape &
optical
disks
offline
dollars/MB
5
10-9 10-6 10-3 10-0 103
access time (sec)
10-4
tape
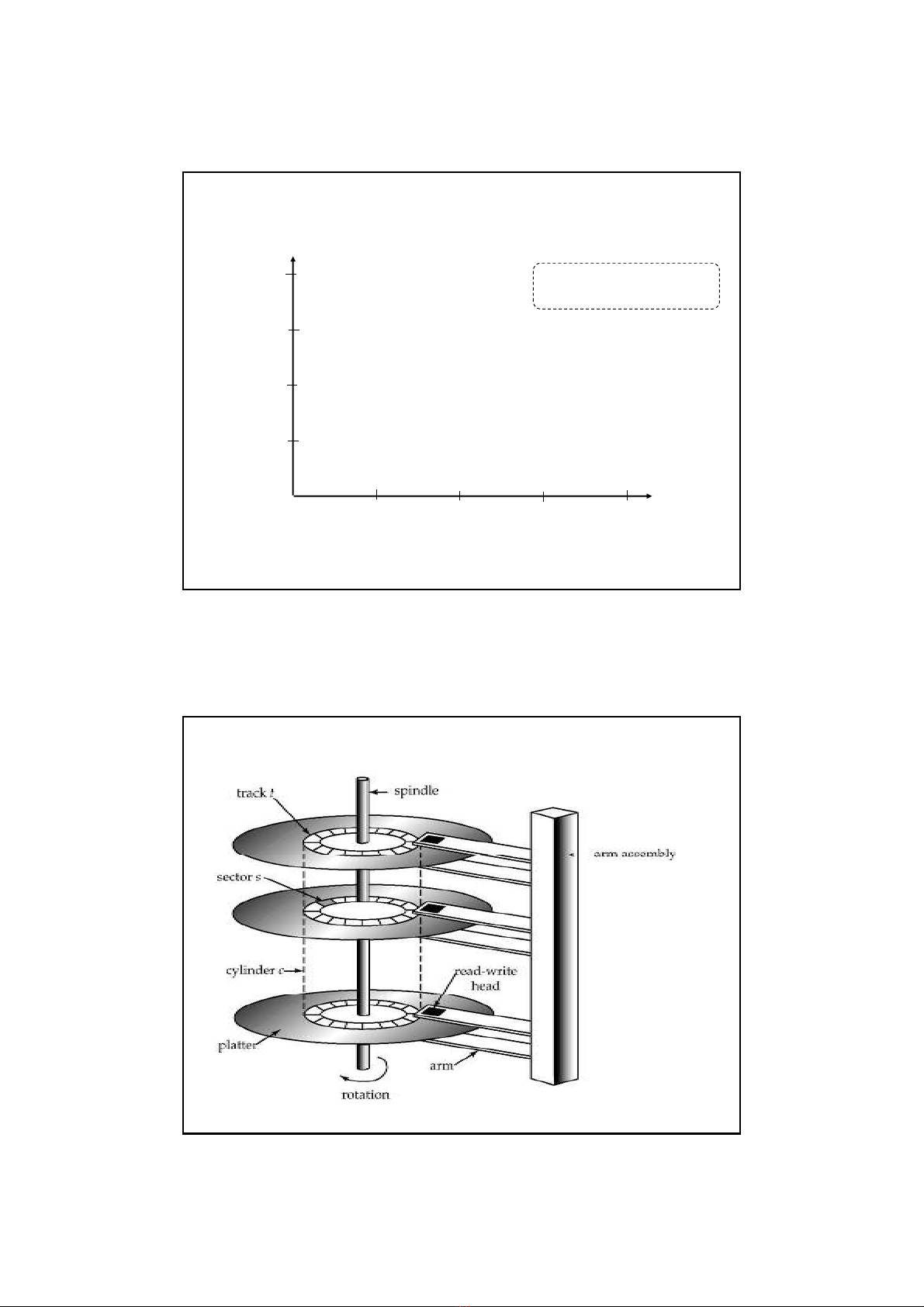
Đĩa từ (Magnetic disk)
6

4
Về cách quản lý đĩa
•1 mặt đĩa chia thành nhiều track, 1 track chia
thành nhiều block (page). 1 cluster = n block.
• Dùng đĩa từ (magnetic disk) để lưu cơ sở dữ liệu
vì:
Khốil l t ữlớ(khô thểlởbộhớhí h)
–
Khối
l
ượng
l
ưu
t
r
ữ
lớ
n
(khô
ng
thể
l
ưu
ở
bộ
n
hớ
c
hí
n
h)
–Lưu một cách bền bỉ, lâu dài, phục vụ cho truy cập và
xử lý lặp lại (bộ nhớ chính không đáp ứng được)
– Chi phí cho việc lưu trữ rẻ.
•Dữ liệu trên đĩa phải được chép vào bộ nhớ chính
khi cần xử lý. Nếu dữ liệu này có thay đổi thì sẽ
được ghi trởlạivàođĩa.
7
được
ghi
trở
lại
vào
đĩa.
•Bộ điều khiển đĩa (disk controller - DC): giao tiếp
giữa ổ đĩa và máy tính, nhận 1 lệnh I/O, định vị
đầu đọc và làm cho hành động R/W diễn ra.
• Block cũng là đơn vị để lưu trữ và chuyển dữ liệu.
Chuyển dữ liệu
–Thời gian trung bình để tìm và chuyển 1 block
= s + rd + btt
• Seek time (s): để DS định vị đầu đọc/ ghi đúng
track trung bình khỏang 7
10 msec (destop) 3
8
track
,
trung
bình
khỏang
7
-
10
msec
(destop)
,
3
-
8
msec (server).
• Rotational delay/latency (rd): để đầu đọc ở vị trí
block cần đọc, phụ thuộc rpm, trung bình khỏang 2
msec.
• Block transfer time (btt): để chuyển dữ liệu, phụ
th ộàbl ki t ki à
8
th
u
ộ
c v
à
o
bl
oc
k
s
i
ze,
t
rac
k
s
i
ze, v
à
rpm.
– Khi truy xuất đến các block liên tiếp thì tiết
kiệm được thời gian.
–Một số kỹ thuật tìm kiếm khai thác điều này.

5
Một số nguyên tắc
• DBS giảm thiểu số lượng block được
chuyển giữa đĩa và MM (main memory)→
g
iảm số lần tru
y
xuất đĩa
g y
–Lưu lại càng nhiều càng tốt các block dữ liệu
trên MM, tăng cơ hội tìm thấy block cần truy
xuất trên MM.
• Buffer là thành phần của MM dùng để chứa
các bản sao (version mới hơn) của các
ố
9
block được đọc lên/ lưu xu
ố
ng đĩa, do
Buffer manager quản lý.
Lưu tập tin trên đĩa
•CSDL được tổ chức trên đĩa thành một/nhiều
tập tin, mỗi tập tin gồm nhiều mẫu tin, mỗi mẫu
tin gồm nhiều trường.
Mẫti hảiđl t ữtê đĩ hkhi
•
Mẫ
u
ti
n p
hải
đ
ược
l
ưu
t
r
ữ
t
r
ê
n
đĩ
a sao c
h
o
khi
cần thì có thể truy cập được và truy cập một
cách hiệu quả.
– Cách tổ chức file chính (Primary file organization):
cho biết các mẫu tin định vị một cách vật lý như thế
nào trên đĩa
,
từ đó biết cách tru
y
xuất chún
g
.
10
, y g
– Cách tổ chức phụ (secondary organization/ auxiliary
access structure): để truy cập các mẫu tin trên file
hiệu quả.
![Cơ sở dữ liệu: Tập bài giảng Phần 1 [Full]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260306/hoaphuong0906/135x160/46691773028939.jpg)
























