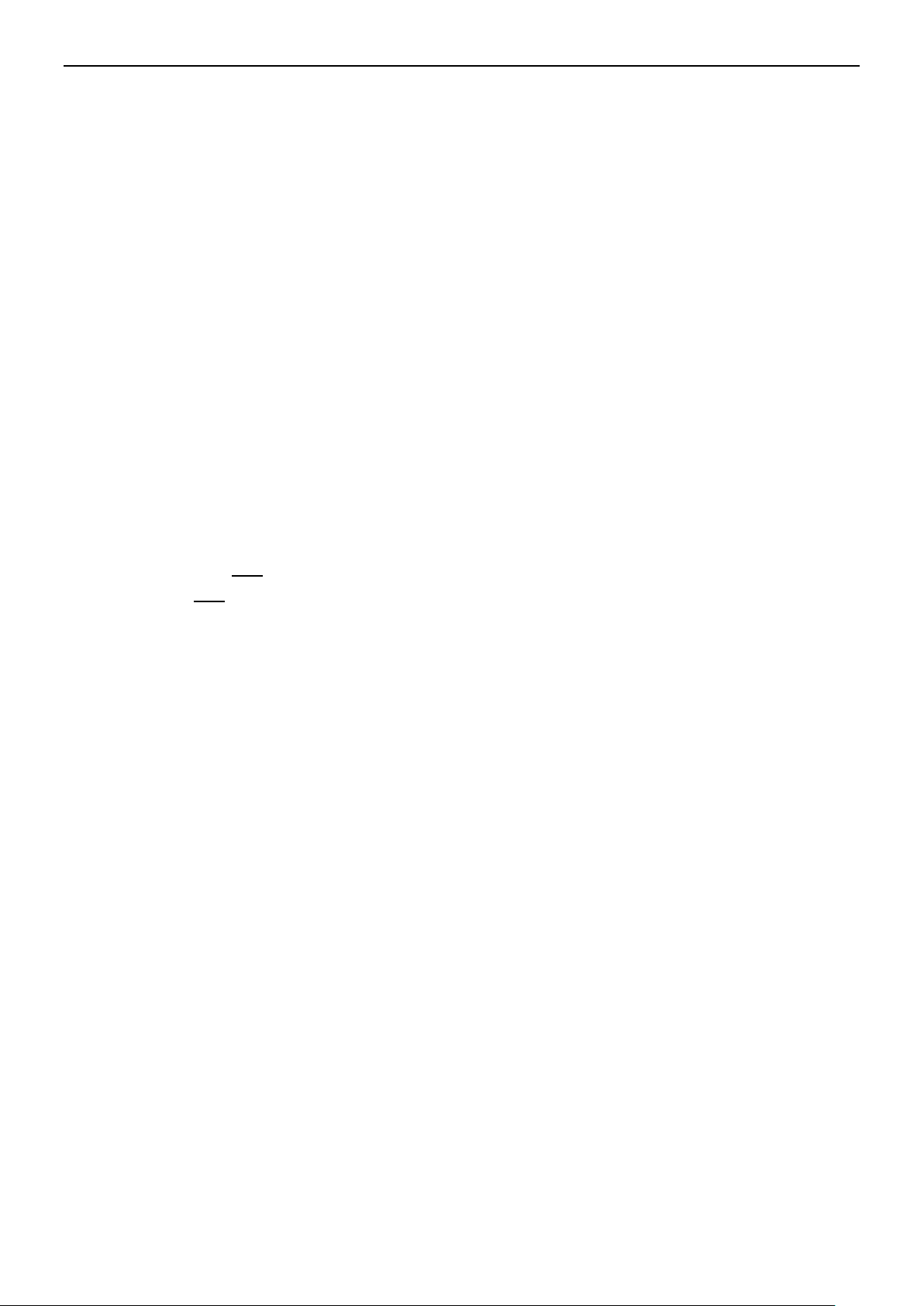
Tuyển tập Hội nghị Khoa học thường niên năm 2015. ISBN : 978-604-82-1710-5
79
CẢI THIỆN HIỆU QUẢ CỦA MÔ HÌNH HỌC MÁY THỐNG KÊ
BỞI LUẬT KẾT HỢP VÀ ỨNG DỤNG TRONG BÀI TOÁN
KHỬ NHẬP NHẰNG NGHĨA TỪ TIẾNG VIỆT
Đinh Phú Hùng
Đại học Thuỷ lợi, email: hungdp@tlu.edu.vn
1. GIỚI THIỆU
Bài toán khử nhập nhằng nghĩa từ (WSD)
chính là việc đi xác định nghĩa phù hợp trong
tất cả các nghĩa của từ đa nghĩa mà từ này
nằm trong một ngữ cảnh xác định. Ví dụ, đối
với động từ "câu" trong tiếng Việt, chúng ta
xem 2 ví dụ sau:
Anh ta đang "câu" ngoài bờ ao.
Đại bác "câu" trúng lô cốt.
Động từ "câu" trong hai câu trên rõ ràng
mang hai nghĩa phân biệt. Việc giải quyết
tốt bài toán này sẽ nâng cao được hiệu quả
cho các bài toán khác của xử lý ngôn ngữ
tự nhiên.
Các phương pháp tiếp cận để giải quyết
bài toán WSD có thể được phân vào hai
nhóm tiếp cận chính là: Tiếp cận dựa trên tri
thức và tiếp cận dựa trên học máy. Cho đến
nay, mặc dù các phương pháp tiếp cận dựa
trên học máy thống kê áp dụng giải quyết cho
bài toán WSD đã cho thấy được những ưu
điểm khi so sánh với các phương pháp khác.
Tuy nhiên, vẫn còn vài trường hợp mà mô
hình học máy thống kê chưa thể giải quyết
được. Theo quan sát của chúng tôi, điều này
có thể được giải thích như sau: Thứ nhất, mô
hình học máy thống kê được xây dựng dựa
trên các kho ngữ liệu ít và không đủ bao quát
tất cả các trường hợp xảy ra trong thực tế.
Thứ hai, trong bất kỳ ngôn ngữ nào vẫn tồn
tại những trường hợp ngoại lệ không tuân
theo nguyên lý hay mô hình thống kê. Chính
vì vậy, chúng tôi đề xuất việc sử dụng các
luật kết hợp khai phá được từ những ngữ
cảnh mà mô hình học máy thống kê phân lớp
không đúng để sửa những lỗi phân lớp cho
mô hình học máy. Chính những luật kết hợp
này sẽ giúp cải thiện hiệu năng của mô hình
học máy thống kê.
Bài báo này được tổ chức thành năm phần
bao gồm cả phần giới thiệu. Trong phần 2,
chúng tôi trình bày một số kiến thức cơ bản
liên quan đến phân lớp dựa trên luật kết hợp
và mô hình học máy thống kê Naive Bayes
(NB) mà chúng tôi lựa chọn. Sau đó, chi tiết
về mô hình mà chúng tôi đề xuất sẽ được
trình bày trong phần 3. Chuẩn bị dữ liệu và
kết quả thực nghiệm được chúng tôi trình bày
trong phần 4. Cuối cùng, kết luận về bài báo
được chúng tôi trình bày trong phần 5.
2. KIẾN THỨC CƠ SỞ
2.1. Phân lớp dựa trên luật kết hợp
Phân lớp dựa trên luật kết hợp hay còn
được gọi là phân lớp kết hợp chính là việc
ứng dụng các luật kết hợp để giải quyết cho
bài toán phân lớp. Một số thuật toán phân lớp
kết hợp đã được đề xuất như: CBA [1],
CMAR [2], CPAR [3], v…v.
2.2. Giải thuật CMAR
Trong phần này, chúng tôi trình bày tóm
tắt giải thuật CMAR. Giải thuật này được
chia ra làm 2 giai đoạn cơ bản: Khai phá luật
kết hợp và phân lớp.
Trong giai đoạn thứ nhất, CMAR sẽ tìm tất
cả các luật tham gia vào quá trình phân lớp.
Trong giai đoạn thứ hai, CMAR thực hiện
phân lớp cho một đối tượng.
Tuyển tập Hội nghị Khoa học thường niên năm 2015. ISBN : 978-604-82-1710-5
80
2.3. Giải thuật Naïve Bayes
Phương pháp NB được sử dụng lần đầu
tiên cho bài toán WSD được đề xuất bởi Gale
[4], phương pháp này dựa trên giả thiết tất cả
các đặc trưng là độc lập. Cho w là một từ
nhập nhằng, giả sử tập S = {s1, s2,…, sm} là
tập các nghĩa có thể có của từ được tìm
thấy trong từ điển. Gọi F = {f1, f2,…, fn} là
tập các đặc trưng được trích rút từ ngữ cảnh
của từ w. Theo phương pháp NB, từ w sẽ
được phân vào lớp nếu xác suất có điều
kiện P (S1k|F) đạt giá trị lớn nhất. Nghĩa là:
Sk = argmaxP(sj|F), j
{1, …, m} (1)
3. ĐỀ XUẤT MÔ HÌNH
Mô hình này bao gồm 2 quá trình, quá
trình huấn luyện và quá trình kiểm tra.
3.1. Quá trình huấn luyện
Đầu vào: Tập dữ liệu huấn luyện D11 và
tập dữ liệu phát triển D12 chứa các ngữ cảnh
của từ đa nghĩa đã được gán nhãn bằng tay.
Bước 1: Tạo tập dữ liệu phát triển thô D12a
bằng cách bỏ nhãn từ tập dữ liệu phát
triển D12.
Bước 2: Sử dụng tập dữ liệu huấn luyện
D11 để huấn luyện lên mô hình phân lớp NB.
Sau đó, sử dụng chính mô hình này để phân
lớp cho tập dữ liệu D12a thu được ở bước 1.
Kết quả thu được tập dữ liệu có nhãn D12b.
Bước 3: So sánh hai tập dữ liệu D12 và
D12b để xác định được những ngữ cảnh bị gán
nhãn sai bởi mô hình NB ở trên.
Đầu ra: Danh sách các ngữ cảnh bị phân
lớp sai.
Hình 1. Quá trình phát hiện lỗi
Trong giai đoạn thứ hai, chúng tôi sử dụng
chính các ngữ cảnh bị phân lớp sai ở giai
đoạn 1 để khai phá ra các luật kết hợp theo
giải thuật CMAR [2].
Hình 2. Quá trình tạo luật kết hợp
3.2. Quá trình kiểm tra
Trong quá trình này chúng tôi sử dụng các
luật kết hợp có được trong quá trình huấn
luyện như sau:
Đầu vào: Tập dữ liệu kiểm tra D2 và tập
các luật kết hợp
Bước 1: Tạo ra tập dữ liệu chưa có nhãn
D21 bằng cách loại bỏ nhãn từ tập dữ liệu D2.
Bước 2: Áp dụng mô hình phân lớp NB
đối với tập dữ liệu D21, thu được một tập dữ
liệu D21. Tập dữ liệu này bao gồm tập dữ liệu
được gán nhãn đúng D21a và tập dữ liệu bị
gán nhãn sai D21b.
Bước 3: Áp dụng danh sách các luật kết
hợp thu được trong quá trình huấn luyện đối
với tập dữ liệu D21b thu được một tập dữ liệu
mới D22.
Bước 4: So sánh tập dữ liệu D21a D22 với
tập dữ liệu D2 để đánh giá độ chính xác của
mô hình.
Đầu ra: Độ chính xác của mô hình đã
đề xuất.
Hình 2. Quá trình kiểm tra
4. THỰC NGHIỆM
4.1. Dữ liệu thực nghiệm
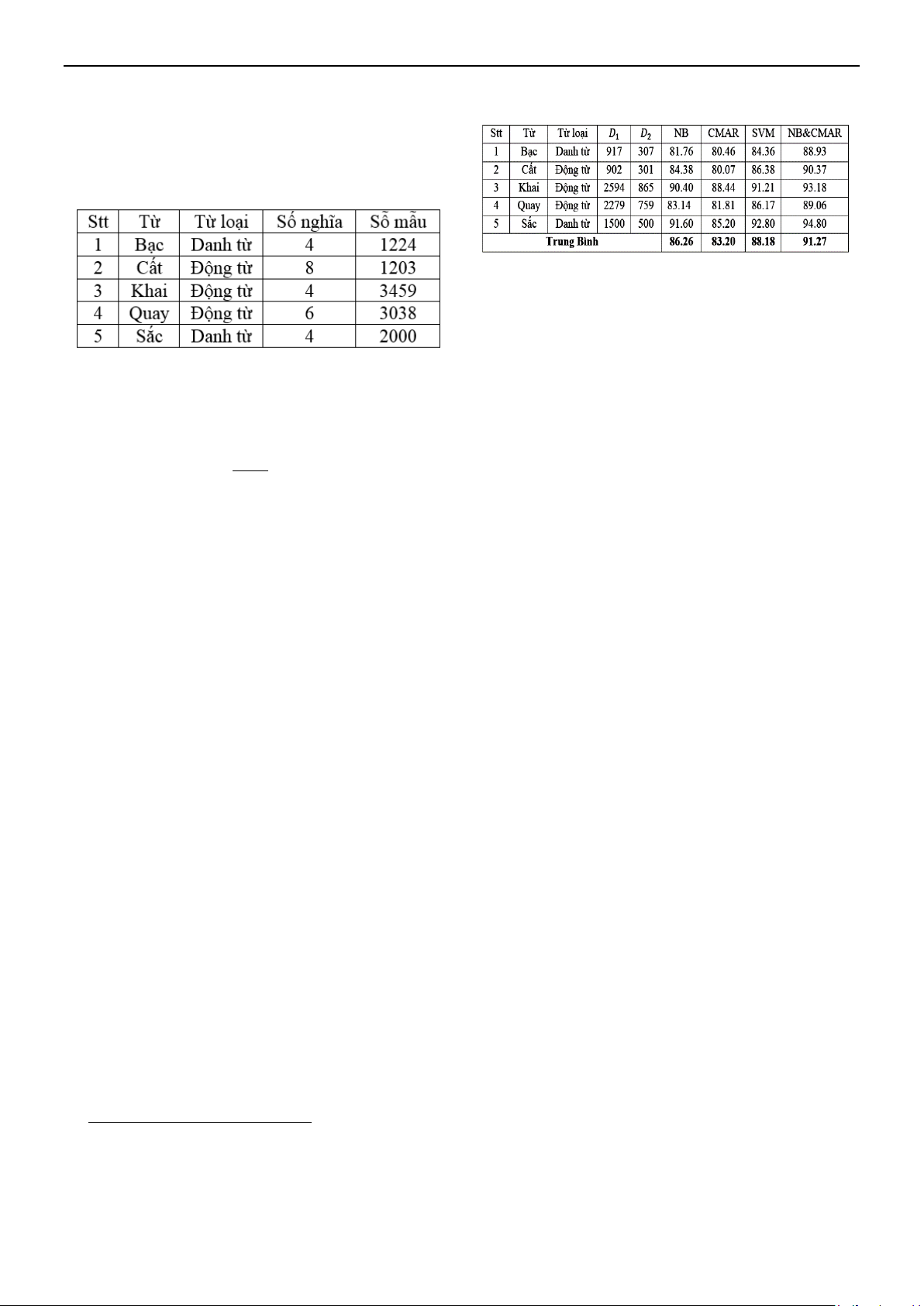
Chúng tôi thu thập dữ liệu từ hơn 50 các
trang báo tin tức tiếng Việt. Sau đó, trích rút
Tuyển tập Hội nghị Khoa học thường niên năm 2015. ISBN : 978-604-82-1710-5
81
ngữ cảnh cho 5 từ nhập nhằng. Từ những ngữ
cảnh này, chúng tôi tiến hành gán nhãn bằng
tay và thu được kho ngữ liệu D như bảng 1.
Bảng 1. Thống kê dữ liệu gán nhãn
Để có thể thu được một tập luật kết hợp
tốt trong quá trình huấn luyện, chúng tôi
chia ngẫu nhiên 10 lần kho ngữ liệu D1
thành hai phần theo tỉ lệ 3:1 thu được 10 bộ
iu
11 12
(D ,D )
với i =
1,10
.
4.2. Công cụ thực nghiệm
Chúng tôi xây dựng mô hình phân lớp NB
theo giải thuật trình bày ở mục 2.3. Đối với mô
hình phân lớp CMAR, chúng tôi sử dụng phần
mềm LUCS-KDD
1
được phát triển bởi Đại học
Liverpool, nó có sẵn mã nguồn cần thiết cho
phép kết hợp với mô hình NB để xây dựng lên
mô hình NB&CMAR mà chúng tôi đề xuất.
Riêng đối với mô hình SVM, chúng tôi sử
dụng công cụ Libsvm
2
cho phần thực nghiệm.
4.3. Kết quả thực nghiệm
Các Trong phần này, chúng tôi trình bày
kết quả thực nghiệm trên các mô hình sau:
NB, CMAR, SVM, và mô hình chúng tôi đề
xuất (NB&CMAR). Các đặc trưng mà chúng
tôi sử dụng là Túi từ, và cụm từ [5].
Đầu tiên, chúng tôi sử dụng tập dữ liệu D1
để huấn luyện lên các mô hình NB, CMAR,
SVM. Sau đó chúng tôi sử dụng tập dữ liệu
D2 để kiểm tra cho các mô hình này. Độ
chính xác trung bình cho 5 từ nhập nhằng đối
với các mô hình NB, CMAR, SVM lần lượt
là 86.26%, 83.20%, 88.18%.
1
Xem chi tiết về LUCS-KDD tại
http://cgi.csc.liv.ac.uk/~frans/KDD/Software/CMA
R/cmar.html
2
Xem chi tiết về Libsvm tại
http://www.csie.ntu.edu.tw/~cjlin/libsvm/
Bảng 2. Bảng kết quả thực nghiệm
5. KẾT LUẬN
Trong bài báo này, chúng tôi đã đề xuất một
phương pháp mới cho việc giải quyết bài toán
WSD. Chúng tôi đã áp dụng phương pháp này
để giải quyết bài toán WSD đối với tiếng Việt.
Kết quả thực nghiệm trên 5 từ nhập nhằng trong
tiếng Việt mà chúng tôi lựa chọn ngẫu nhiên
cho thấy độ chính xác tăng lần lượt là 5.01%,
8.07%, 3.09% khi so sánh với kết quả các
phương pháp NB, CMAR, SVM tương ứng.
Kết quả này cho thấy rằng các luật kết hợp
có hiệu quả trong việc cải thiện hiệu năng của
mô hình học máy thống kê. Hơn nữa, phương
pháp mà chúng tôi đề xuất có thể áp dụng cho
bài toán WSD đối các ngôn ngữ khác và nó
cũng có thể được áp dụng để giải quyết các bài
toán khác của xử lý ngôn ngữ tự nhiên như:
gán nhãn từ loại, phân tích cú pháp, v...v.
6. TÀI LIỆU THAM KHẢO
[1] Liu, B., Hsu, W., Ma, Y. (1998),
"Integrating classification and association
rule mining," in Knowledge Discovery and
Data Mining, New York, USA.
[2] Li, W., Han, J., Pei, J. (2001), "Cmar:
Accurate and efficient classification based
on multiple class-association rules," in
Proceedings of the 2001 IEEE International,
Washington, DC, USA.
[3] Yin, X., Han, J.(2003), "Classification based
on Predictive Association Rules," in SDM,
San Francisco,CA,USA.
[4] Gale, W. A., Church K. W., Yarowsky D.
(1992), "A method for disambiguating word
senses in a large corpus," Computers and the
Humanities, vol. 26, no. 5-6, pp. 415-439.
[5] Dinh, P.H., Nguyen, N.K., Le, A.C. (2012),
"Combining statistical machine learning
with transformation rule learning for
vietnamese word sense disambiguation," in
IEEE - RIVF, Ho Chi Minh, Vietnam.

Tuyển tập Hội nghị Khoa học thường niên năm 2015. ISBN : 978-604-82-1710-5
82









![Bài giảng Học máy thống kê: Tổng quan về máy học [Mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20250515/hoatrongguong03/135x160/6511747304171.jpg)














![Quyển ghi Xác suất và Thống kê [chuẩn nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20251030/anh26012006/135x160/68811762164229.jpg)
