
Tuyển tập Hội nghị Khoa học thường niên năm 2015. ISBN : 978-604-82-1710-5
88
QUẢN LÝ SIÊU DỮ LIỆU VÀ HIỆN THỰC HÓA
TÀI LIỆU KẾT HỢP
Lý Anh Tuấn1, Trần Thị Minh Hoàn2
1Đại học Thủy lợi, email: tuanla@tlu.edu.vn
2Đại học Thủy lợi, email: hoantm@tlu.edu.vn
1. GIỚI THIỆU
Thư viện số là một hạ tầng cơ sở mạng hỗ
trợ việc tạo và phối các dịch vụ nội dung số.
Trong đó thao tác tạo tài liệu cho phép người
dùng tạo một tài liệu mới hoặc từ đầu hoặc
bằng cách sửa đổi và sử dụng lại các tài liệu
sẵn có. Nếu được tạo từ đầu tài liệu là nguyên
tử ngược lại là kết hợp. Theo tiếp cận của
chúng tôi một tài liệu kết hợp là một tài liệu
ảo có cấu trúc cây, trong đó mỗi nút có một
mô tả về nội dung nó biểu diễn.
Công việc của chúng tôi trong bài báo này
tập trung vào việc quản lý siêu dữ liệu và
hiện thực hóa tài liệu kết hợp. Trước hết
chúng tôi đề xuất một cải tiến cho mô hình
suy diễn siêu dữ liệu của các tài liệu kết hợp
trong [1]. Mô hình trong [1] cho phép siêu dữ
liệu được suy diễn hoàn toàn tự động, còn với
mô hình cải tiến, tác giả là người quyết định
mô tả đăng kí của tài liệu. Tiếp đó, chúng tôi
mô tả công việc hiện thực hóa tài liệu kết hợp
(tức là tạo ra một "phiên bản giấy" của tài
liệu kết hợp) và đề xuất các thuật toán tạo
bảng nội dung, tạo chỉ mục giúp hiện thực
hóa tài liệu kết hợp.
2. MÔ HÌNH TÀI LIỆU KẾT HỢP VÀ
CÁC MÔ TẢ
2.1. Biểu diễn tài liệu
Mô hình của chúng tôi không xét đến nội
dung của tài liệu mà chỉ quan tâm đến cấu
trúc của tài liệu và các mô tả [1][2].
Định nghĩa 1 (Biểu diễn tài liệu). Một
tài liệu bao gồm một định danh d và một tập
các tài liệu là các phần của d, ký hiệu là
parts(d). Nếu parts(d) = ∅ thì d được gọi là
tài liệu nguyên tử, ngược lại d được gọi là
tài liệu kết hợp.
Chúng ta có thể viết d = d1 + d2 + … + dn
thay cho parts(d) = {d1, d2, …, dn}.
Định nghĩa 2 (Thành phần của tài liệu).
Giả sử d = d1 + d2 + … + dn. Tập các thành
phần của d, ký hiệu là comp(d), được định
nghĩa đệ quy như sau:
Nếu d là tài liệu nguyên tử thì comp(d)=
∅; ngược lại comp(d) = parts(d) ∪ comp(d1)
∪ comp(d2) ∪ ... ∪ comp(dn).
Giả sử rằng tất cả tài liệu kết hợp d đều là
cây với d là gốc và comp(d) là tập các nút.
Lưu ý, mô hình của chúng tôi không quan
tâm đến trật tự các phần của tài liệu kết hợp.
2.2. Cây phân loại và mô tả
Thông thường mô tả nội dung tài liệu là
tập thuật ngữ lấy từ một cây phân loại.
Định nghĩa 3 (Cây phân loại). Giả sử T là
một tập thuật ngữ, hoặc từ khóa. Một cây
phân loại P được định nghĩa trên T là một bộ
(T, ≼) trong đó ≼ là một quan hệ nhị phân
phản xạ và bắc cầu trên T được gọi là quan
hệ bao hàm.
Cho hai thuật ngữ s và t, nếu s≼t thì chúng
ta nói rằng s được bao hàm bởi t, hoặc t bao
hàm s.
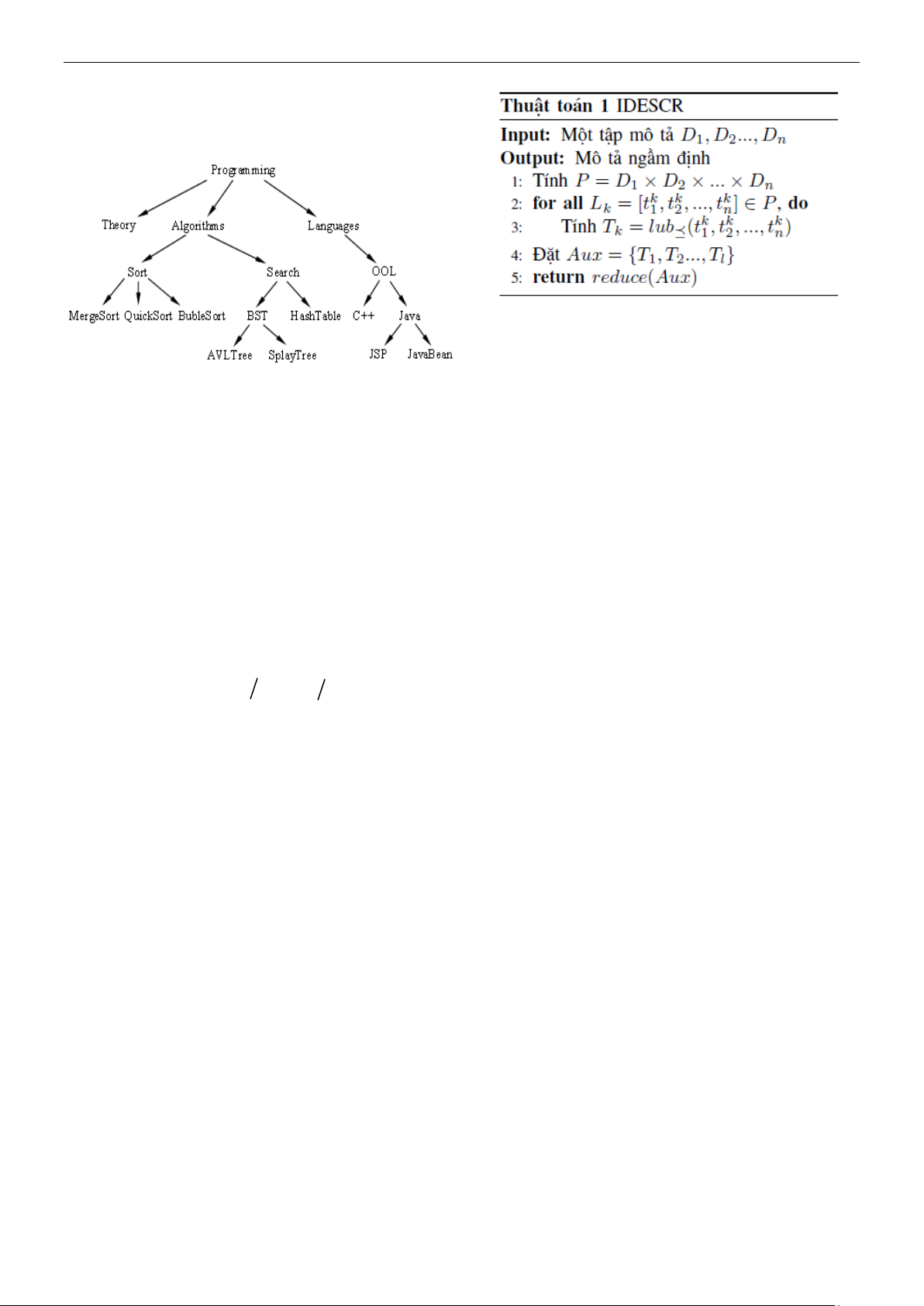
Hình 1 trình bày một cây phân loại, trong
đó thuật ngữ Algorithms bao hàm thuật ngữ
Sort và Search, OOL bao hàm Java và C++,
v.v... Do tính bắc cầu của mối quan hệ bao
Tuyển tập Hội nghị Khoa học thường niên năm 2015. ISBN : 978-604-82-1710-5
89
hàm, thuật ngữ Programming bao hàm tất cả
các thuật ngữ trong cây.
Hình 1. Một cây phân loại
Định nghĩa 4 (Mô tả). Cho một cây phân
loại (T, ≼), một mô tả trong T là bất kỳ tập
thuật ngữ nào từ T.
Một mô tả là dư thừa nếu nó chứa một vài
thuật ngữ được bao hàm bởi các thuật ngữ
khác. Chẳng hạn, {Sort, QuickSort, Java} là
dư thừa, vì Sort bao hàm QuickSort.
Định nghĩa 5 (Mô tả rút gọn). Cho một
cây phân loại (T, ≼), tập thuật ngữ D từ T
được gọi là rút gọn nếu với các thuật ngữ s
và t bất kỳ trong D, s ≼ t và t≼ s.
Có thể tạo ra mô tả rút gọn bằng cách loại
bỏ tất cả thuật ngữ trừ các thuật ngữ bé nhất,
hoặc loại bỏ tất cả thuật ngữ trừ các thuật ngữ
lớn nhất. Trong đó cách đầu tạo ra mô tả
chính xác hơn. Ví dụ, {QuickSort, Java}
chính xác hơn {Sort, Java}.
Định nghĩa 6 (Quan hệ mịn). Giả sử D và
D' là hai mô tả. Chúng ta nói rằng D mịn hơn
D', ký hiệu là D ⊑ D', nếu và chỉ nếu với mỗi
t' trong D', tồn tại t trong D sao cho t ≼t'.
Nói cách khác, D là mịn hơn D’ nếu tất cả
thuật ngữ của D’ đều bao hàm thuật ngữ nào
đó của D. Ví dụ, {QuickSort, Java,
AVLTree} mịn hơn {Algorithms, OOL}.
Định nghĩa 7 (Mô tả ngầm định). Giả sử
D = {D1, ..., Dn} là một tập các mô tả trong
T. Mô tả ngầm định của D, ký hiệu là
IDescr(D), là cận trên bé nhất của D trong ⊑,
tức là IDescr(D)=lub(D, ⊑).
Để tính toán mô tả ngầm định, chúng tôi
sử dụng thuật toán sau đây [1].
Ví dụ: Xét tài liệu gồm hai phần với các
mô tả D1 = {QuickSort, Java} và D2 =
{AVLTree, C++}. Mô tả ngầm định của tài
liệu là {Algorithms,OOL}.
Mô tả ngầm định được sử dụng để gợi ý
cho tác giả lựa chọn mô tả đăng ký khi đăng
ký tài liệu với thư viện số [2].
3. HIỆN THỰC HÓA TÀI LIỆU KẾT HỢP
Hiện thực hóa đơn giản là đặt các nội
dung có thể được truy cập thông qua nút
theo một tuần tự để tạo ra một tài liệu thông
thường. Chúng ta dễ dàng thiết kế giao diện
để người dùng thực hiện công việc này. Một
công việc quan trọng khác là rút ra bảng nội
dung và chỉ mục của tài liệu kết hợp từ trật
tự tuyến tính của các nút ở thời điểm hiện
thực hóa.
Định nghĩa 8 (Bảng nội dung). Giả sử
descr1, …, descrn là tập các mô tả nút trong
toàn bộ cây, ở đó mỗi descri liên kết với nút
ddi để tạo ra dòng thứ i của bảng nội dung
của tài liệu kết hợp.
Định nghĩa 9 (Chỉ mục). Giả sử k1, …,
km là tập tất cả các thuật ngữ có trong cây,
mỗi thuật ngữ xuất hiện trong một hoặc
nhiều mô tả nút. Liên kết mỗi ki với một
danh sách các nút ở đó mô tả ki xuất hiện,
để tạo ra dòng thứ i của chỉ mục. Tập tất cả
các dòng như vậy tạo nên chỉ mục của tài
liệu kết hợp.
Hình 2 trình bày một tài liệu kết hợp
dạng cây. Mỗi nút của cây liên kết với một
mô tả về nội dung nó biểu diễn. Mô tả liên
kết với nút lá được cung cấp bởi tác giả,
trong khi mô tả liên kết với nút trung gian
do người dùng quyết định với sự gợi ý của
hệ thống.

Tuyển tập Hội nghị Khoa học thường niên năm 2015. ISBN : 978-604-82-1710-5
90
Hình 2. Cấu trúc của một tài liệu kết hợp
Mỗi nút trong cây sẽ bao gồm các trường:
URI (định danh), description (mô tả), child
(danh sách nút con), birthorder (thứ tự sinh),
path (đường dẫn dựa trên thứ tự sinh).
Thuật toán 2 sinh ra bảng nội dung. Áp
dụng thuật toán cho cây trong hình 2 thu
được bảng nội dung trong hình 3a.
Để sinh ra chỉ mục chúng ta sử dụng một
mảng gồm hai trường là key (từ khóa) và
lspath (danh sách đường dẫn) để lưu kết quả
tạm thời. Thuật toán 4 sử dụng Thuật toán 3
để tạo mảng, sau đó nó sắp xếp mảng và in ra
chỉ mục. Áp dụng thuật toán cho cây trong
hình 2 thu được chỉ mục trong hình 3b.
Hình 3. Bảng nội dung và chỉ mục
4. KẾT LUẬN
Trong bài báo chúng tôi đã trình bày một
số cải tiến cho mô hình suy diễn siêu dữ liệu
của các tài liệu kết hợp. Theo đó các mô tả
ngầm định sẽ được hệ thống tính toán một
cách tự động và được sử dụng để gợi ý cho
người dùng chọn mô tả đăng ký khi đăng ký
tài liệu kết hợp với thư viện số.
Chúng tôi cũng trình bày các định nghĩa và
các thuật toán giúp tạo bảng nội dung và chỉ
mục cho tài liệu kết hợp từ các mô tả đăng
ký. Đây là những khâu quan trọng của quá
trình hiện thực hóa tài liệu kết hợp.
5. TÀI LIỆU THAM KHẢO
[1] Rigaux, P., Spyratos, N., Metadata inference
for document retrieval in a distributed
repository. In: Maher, M.J. (ed.) ASIAN
2004. LNCS, vol. 3321, pp. 418-436.
[2] Tsuyoshi Sugibuchi, Anh Tuan Ly, and
Nicolas Spyratos, Metadata inference for
description authoring in a document
composition environment. Proceedings of
the 8th Italian Research Conference on
Digital Libraries, Bari, Italy, Feb. 2012, pp.
69-80, CCIS, Springer.

Tuyển tập Hội nghị Khoa học thường niên năm 2015. ISBN : 978-604-82-1710-5

























