
CHƯƠNG 1: ÔN TẬP
1.1. Trung bình mẫu – Phương sai mẫu
1.1.1. Trung bình mẫu
Trong phân tích dữ liệu, cũng như trong cuộc sống hàng ngày, chúng ta thường nói
đến chiều cao trung bình, thu nhập trung bình, vân vân. Đó chính là trung bình mẫu.
Hãy xét ví dụ sau:
Ví dụ 1.1: Bảng quan sát nhiệt độ ở Đà Lạt
Thứ 2 Thứ 3 Thứ 4 Thứ 5
(x
(
)
o
x5.1918202119
4
1=+++=⇒
Một cách khái quát, trung bình mẫu được tính bằng công thức sau:
()
Nxxxx
N
x++++= ......
1321
Hay: ∑
=
=N
n
n
x
N
x
1
1
1.1.2. Phương sai mẫu
Phương sai mẫu [ký hiệu ] bằng trung bình của tổng bình phương độ lệch giữa giá
trị quan sát so với giá trị trung bình:
2
X
s
()
(
)
(
)
⎥
⎦
⎤
⎢
⎣
⎡++ −−−
=xxxxxx
N
sN
X
2
2
2
1
2
2......
1
Hay:
(
)
∑
=−
=N
n
n
Xxx
N
s
1
2
21
Chẳng hạn, về trung bình mà nói thì khí hậu ở sa mạc rất nóng. Hơn nữa nhiệt độ
giao động rất lớn giữa ngày và đêm. Để thể hiện được sự khắc nghiệt của khí hậu sa
mạc, chúng ta không những chỉ sử dụng trung bình (mẫu) về nhiệt độ, mà cả sự giao
1) (x2) (x3) (x4)
19o21o20o18o
1
động của nhiệt độ theo từng thời điểm so với trung bình. Đó chính là khái niệm về
phương sai mẫu nói trên.
1.2. Hàm mật độ xác suất, hàm phân bố xác suất
1.2.1. Tần suất và xác suất
Để có sự hình dung về tần suất, hãy xét ví dụ sau:
Ví dụ 1.2: Xếp hạng tốc độ gia tăng giá cổ phiếu trên thị trường chứng khoán Việt
Nam.
Gọi X là tỉ lệ phần trăm mức tăng giá cổ phiếu trung bình trong 3 tháng đầu tiên sau
khi “lên sàn”; gọi P là phần trăm các công ty có mức tăng giá cổ phiếu tương ứng với
giá trị của X
X Y
(x1) 50% 10%
(x2) 40% 20%
(x3) 30% 35%
(x4) 20% 25%
Con số P= 10%, X= 50% có nghĩa là có 10% trong tổng số các công ty có mức tăng
giá trong 3 tháng đầu sau khi phát hành cổ phiếu ra công chúng là 50%. Đó chính là ví
dụ về tần suất
Ví dụ 1.3: Trò chơi tung đồng xu.
Giả sử bạn tham gia cuộc chơi tung đồng xu tại hội chợ. Nếu là mặt sấp, bạn sẽ được
$100. Ngược lại, nếu là mặt ngửa, bạn được $0. Với thể lệ đó, bạn sẵn sàng trả bao
nhiêu đôla để tham gia trò chơi?
Để cho tiện, hãy kí hiệu mặt sấp là 1, mặt ngửa là 0. Giả sử kết quả tung xu sau 10 lần
là như sau:
X P
1 3/10
0 7/10
Con số 3/10 chính là tần suất xuất hiện mặt sấp (X = 1). Nghĩa là, trong 10 lần tung
xu, có 3 lần xuất hiện mặt sấp. Và do đó, có 7 lần xuất hiện mặt ngửa.
Số tiền bạn bỏ ra cho việc tham dự 10 lần tung xu là: $50 x 10 = $500.
Số tiền nhận được trong cuộc chơi: $100 x 3 + $0 x 7 = $300.
2

Æ Do vậy, cuộc chơi không hứng thú đối với bạn ($500 > $300).
Tuy nhiên, nếu giả sử rằng bạn tham dự cuộc chơi vô hạn lần. Khi đó, số lần xuất hiện
mặt sấp và mặt ngửa là như nhau, và bằng ½. Khi đó, kỳ vọng đượccuộc sẽ là:
$100x1/2 + $0x1/2 = $50; và bằng chính số tiền lớn nhất bạn sẵn sàng trả để tham dự
cuộc chơi.
Điều chúng ta cần phân biệt là con số P = 3/10 trong ví dụ nêu trên là tần suất xuất
hiện mặt sấp trong 10 lần thử. Và con số ½ là xác suất xuất hiện mặt sấp (hoặc ngửa).
Khái niệm tần suất ứng với từng mẫu thử; còn xác suất tương ứng với tổng thể.
1.2.2. Biến ngẫu nhiên rời rạc và liên tục
2.2.1. Biến ngẫu nhiên rời rạc:
Một biến ngẫu nhiên là rời rạc nếu các giá trị có thể có của nó lập nên một tập hợp
hữu hạn hoặc đếm được, nghĩa là có thể liệt kê được tất cả các giá trị có thể có của nó.
Cuộc chơi tung xu nêu trên là ví dụ về biến ngẫu nhiên rời rạc.
Một cách hình thức hóa, ta có thể nói như sau. Giả sử đối tượng quan sát X có thể
xuất hiện trong K sự kiện khác nhau [trong ví dụ tung xu, K = 2]. Ta ký hiệu các sự
kiện đó là .
K
xxx ,...,, 21
Tần suất xuất hiện một biến cố trong N phép thử, ký hiệu là , là tỉ số giữa số
lần xuất hiện biến cố cụ thể đó so với N phép thử được thực hiện.
k
xk
p
Với mọi chỉ số, , ta có thể viết như sau:
Kk ,...,3,2,1
=
X x x x … x
123 K
P p p p … p
123 K
p , p
1 2, p ,… p
3K > 0, và
p1 + p2 + p + …… + p
3K = 1, hay cũng vậy,
1
1
=
∑
=
K
k
k
p
Nếu số mẫu N là đủ lớn (tiến đến vô hạn), khái niệm tần suất xuất hiện một biến cố
được thay bằng khái niệm xác suất xuất hiện biến cố, ký hiệu bởi:
Trong đó, là hàm mật độ xác suất của .,..,2,1),( Kkxff kk == )( k
xf ....2,1, Kkxk=
3
Ta cũng có,
f , f , f ,… f
1 2 3 K > 0, và
1
1
=
∑
=
K
k
k
f
2.2.2. Biến ngẫu nhiên liên tục
Một biến ngẫu nhiên là liên tục nếu các giá trị có thể có của nó lắp đầy một khỏang
trên trục số, nghĩa là không thể liệt kê và đếm được tất cả các giá trị có thể có của nó.
Tương tự với trường hợp phân bố xác suất rời rạc, nếu gọi X là một biến ngẫu nhiên
liên tục; và f(x) là hàm mật độ xác suất của X. Khi đó:
1)(
0)(
=
≥
∫∞+
∞− dxxf
x
f
Ta định nghĩa hàm phân bố xác suất của X là:
∫∞−
=xdttfxF )()(
Điều đó có nghĩa là, xác suất của biến ngẫu nhiên X nhận giá trị trong khoảng
sẽ là:
],[ ba
)()()( )( aFbFbXaP b
adxxf −==≤≤ ∫
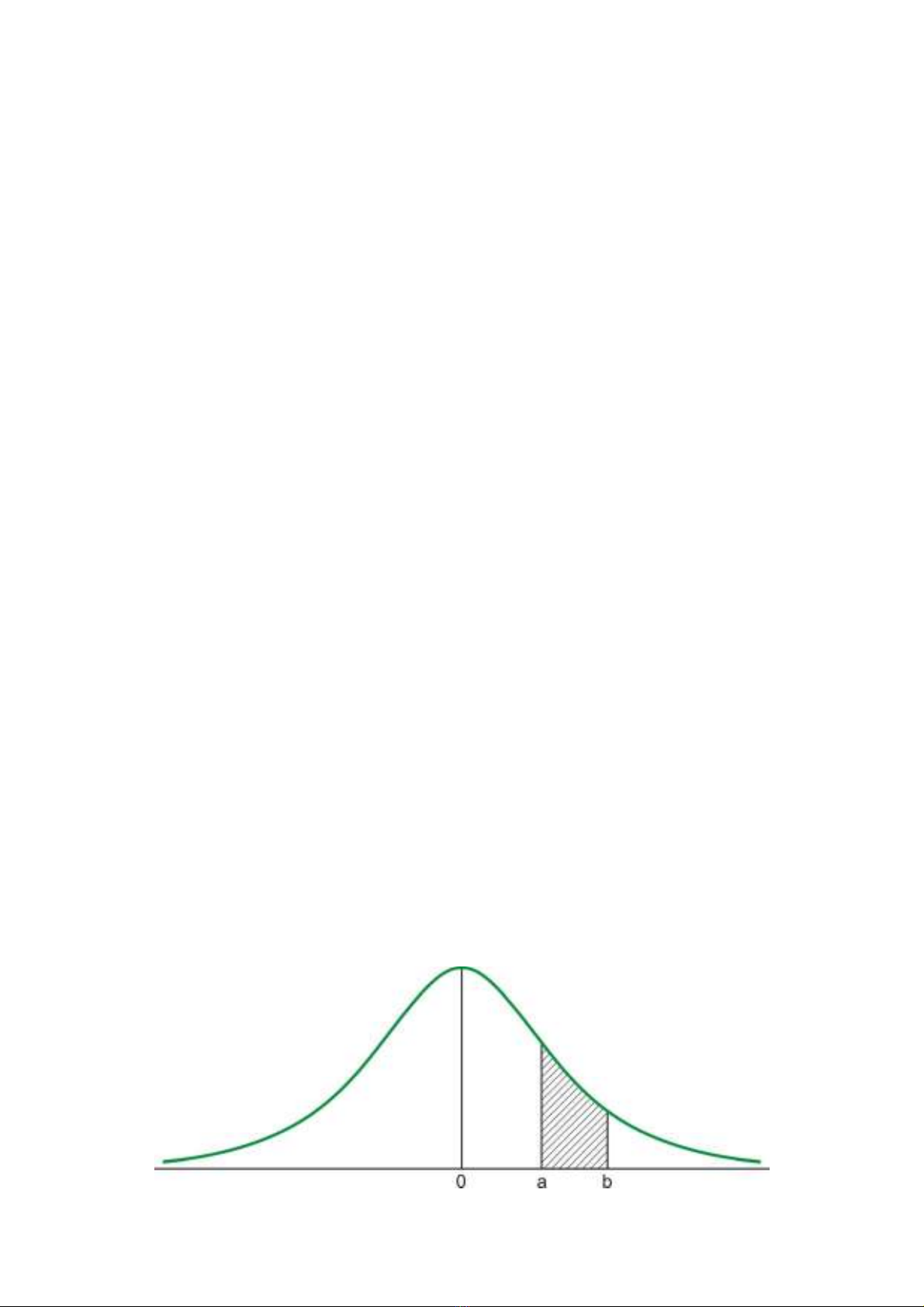
Ví dụ, trong phân bố chuẩn, về đồ thị ta có thể biểu diễn công thức tính xác suất này
như sau:
Đồ thị 1.1: Phân bố xác suất
4

Phần tô đậm chính là xác suất )( bXaP
≤
≤
, được tính bởi tích phân:
.
)()()( aFbF
b
adxxf −=
∫
1.3. Phân bố xác suất đồng thời
Nhiều khi chúng ta muốn đưa ra một đánh giá xác suất đồng thời cho một số biến
lượng ngẫu nhiên. Ví dụ, bảng thống kê có ghi lại dữ kiện về thất nghiệp (u) và lạm
phát (п). Cả hai biến lượng này đều là biến ngẫu nhiên, rất nhiều khả năng là chính
phủ muốn hỏi những nhà kinh tế câu hỏi sau đây: “Liệu khả năng lạm phát thấp hơn
8% và mức độ thất nghiệp nhỏ hơn 6% vào năm sau là bao nhiêu?”. Điều đó có nghĩa
là, ta cần phải xác định xác suất đồng thời:
P (п < 8, u < 6) = ?
Để trả lời được những câu hỏi như vậy, chúng ta cần phải xác định hàm mật độ xác
suất đồng thời [joint probability density function].
1.3.1. Hàm mật độ xác suất đồng thời
Định nghĩa: Giả sử X và Y là 2 biến ngẫu nhiên. Hàm mật độ xác suất đồng thời của x
và y là:
),(),( y
Y
x
X
P
y
x
f
=
==
Hàm số đó cần thỏa mãn điều kiện:
0),( ≥y
x
f
, và
1),( =
∑∑
xy yxf nếu X, Y rời rạc
dxdyyxf
xy .),(
∫∫ nếu X, Y liên tục
Khi đó,
∑
∑
≤≤≤≤
=≤≤≤≤
bxadyc
yxfdycbxaP ),(),( , nếu X, Y là biến ngẫu nhiên rời rạc, và
5






![Tài liệu học kinh tế lượng [mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2013/20130423/sonlam_gst/135x160/6461366717688.jpg)



![Giáo Trình Kinh Tế Vi Mô Kế Toán Doanh Nghiệp Cao Đẳng [Mới Nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260526/alfredodistefano10/135x160/26731780297773.jpg)
![Giáo Trình Kinh Tế Vi Mô: Nắm Vững Nguyên Tắc Cơ Bản [A-Z]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260526/alfredodistefano10/135x160/23961780297774.jpg)





![Giáo trình Kinh tế lao động - TS. Trương Thị Tâm [chuẩn nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260508/hoatrami2026/135x160/25661778559564.jpg)

![Tài liệu học tập Phân tích lao động xã hội - TS. Trần Thị Minh Phương [mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260508/hoatrami2026/135x160/10581778638569.jpg)
![Đề cương ôn tập Khoa học quản lý [năm học] chi tiết, chuẩn nhất](https://cdn.tailieu.vn/images/document/thumbnail/2026/20260506/camtucau2026/135x160/62691778123105.jpg)





%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23fff;%20}%20.st1%20{%20fill:%20%237800fa;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st1'%20d='M117.78,12.18H43.11c2.9,3.47,4.65,7.94,4.65,12.82,0,5.6-2.3,10.66-6.01,14.29h76.02l7.22-13.56-7.22-13.56Z'/%3e%3cg%3e%3cpath%20class='st0'%20d='M53.58,26.17h-.59v-1.46h.59v-4.96h2.83c1.78,0,2.67.94,2.67,2.82v5.76c0,1.87-.89,2.81-2.67,2.81h-2.83v-4.96ZM55.36,21.37v3.34h1.1v1.46h-1.1v3.34h1.01c.61,0,.91-.37.91-1.1v-5.93c0-.74-.3-1.1-.91-1.1h-1.01Z'/%3e%3cpath%20class='st0'%20d='M65.99,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM65.28,18.04c-.25.46-.51.77-.75.94-.21.15-.47.22-.79.22-.26,0-.57-.07-.92-.22l-.38-.15c-.14-.05-.26-.07-.37-.07-.3,0-.53.18-.71.54l-.91-.68c.25-.46.51-.77.75-.94.21-.14.48-.21.79-.21.26,0,.57.07.92.21l.38.15c.14.05.26.07.37.07.3,0,.53-.18.71-.54l.91.68ZM61.91,27.52h1.73l-.87-5.76-.87,5.76Z'/%3e%3cpath%20class='st0'%20d='M74.53,26.89v1.52c0,1.91-.89,2.86-2.67,2.86s-2.67-.95-2.67-2.86v-5.93c0-1.91.89-2.86,2.67-2.86s2.67.95,2.67,2.86v1.11h-1.69v-1.22c0-.75-.31-1.12-.93-1.12s-.93.37-.93,1.12v6.15c0,.74.31,1.11.93,1.11s.93-.37.93-1.11v-1.63h1.69Z'/%3e%3cpath%20class='st0'%20d='M81.4,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM75.9,19.2l1.52-1.91h1.71l1.51,1.91h-1.61l-.76-.95-.75.95h-1.61ZM77.32,27.52h1.73l-.87-5.76-.87,5.76ZM83.1,15.99l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M84.86,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM84.01,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M93.51,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM92.66,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M98.8,31.14h-1.79v-11.39h1.79v4.88h2.03v-4.88h1.83v11.39h-1.83v-4.88h-2.03v4.88Z'/%3e%3cpath%20class='st0'%20d='M105.36,24.55h2.46v1.62h-2.46v3.34h3.09v1.63h-4.88v-11.39h4.88v1.63h-3.09v3.18ZM108.17,17.29l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M112.2,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM111.35,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3c/g%3e%3ccircle%20class='st1'%20cx='25'%20cy='25'%20r='20'/%3e%3cpath%20class='st0'%20d='M32.78,19.27c2.92,0,4.43,2.55,5.28,5.33l.71,2.17c.14.38-.33.75-.71.75h-5.61c.19-.33.24-.71.09-1.08l-.75-2.45c-.43-1.32-.99-2.64-1.79-3.77.75-.57,1.65-.94,2.78-.94h0ZM25,18.38c3.25,0,4.9,2.78,5.89,5.89l.76,2.45c.14.42-.33.8-.8.8h-11.69c-.42,0-.94-.38-.8-.8l.75-2.45c.99-3.11,2.64-5.89,5.89-5.89h0ZM25,11.35c1.74,0,3.11,1.37,3.11,3.11s-1.37,3.11-3.11,3.11-3.11-1.41-3.11-3.11,1.41-3.11,3.11-3.11h0ZM17.27,19.27c1.08,0,1.98.38,2.73.94-.8,1.13-1.37,2.45-1.74,3.77l-.8,2.45c-.14.38-.05.75.09,1.08h-5.56c-.42,0-.9-.38-.75-.75l.71-2.17c.9-2.78,2.41-5.33,5.33-5.33h0ZM17.27,12.91c1.51,0,2.78,1.27,2.78,2.83s-1.27,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM32.78,12.91c1.56,0,2.78,1.27,2.78,2.83s-1.23,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM27.07,28.56v.09c0,.57-.24,1.08-.61,1.46h0v.05c-.38.33-.9.57-1.46.57s-1.08-.24-1.46-.61h0c-.38-.38-.61-.9-.61-1.46v-.09h1.41v.09c0,.19.05.38.19.47v.05c.09.09.28.19.47.19s.38-.09.47-.19v-.05c.14-.09.24-.28.24-.47t-.05-.09h1.41ZM30.99,28.56v.09c0,1.65-.66,3.16-1.74,4.24-1.08,1.08-2.59,1.79-4.24,1.79s-3.16-.71-4.24-1.79l-.05-.05c-1.04-1.08-1.7-2.55-1.7-4.2v-.09h1.41v.09c0,1.27.47,2.4,1.27,3.25h.05c.85.85,1.98,1.37,3.25,1.37s2.4-.52,3.25-1.37c.85-.8,1.37-1.98,1.37-3.25v-.09h1.37ZM34.99,28.56v.09c0,2.78-1.13,5.28-2.92,7.07-1.79,1.79-4.29,2.92-7.07,2.92s-5.23-1.13-7.07-2.92c-1.79-1.79-2.92-4.29-2.92-7.07v-.09h1.41v.09c0,2.4.94,4.53,2.5,6.08,1.56,1.56,3.72,2.5,6.08,2.5s4.52-.94,6.08-2.5c1.56-1.56,2.5-3.68,2.5-6.08v-.09h1.41Z'/%3e%3c/svg%3e)