
TNU Journal of Science and Technology
230(05): 353 - 360
http://jst.tnu.edu.vn 353 Email: jst@tnu.edu.vn
ALLELES FREQUENCY OF 21 STR LOCI OF VIETNAM KINH POPULATION
Duong Thi Thu Thuy1*, Le Thi Quynh2, Tran Van Cuong2, Le Thi Thu Thuy1, Bui Anh Tuan1
1Institute of Forensic Science - Ministry of Public Security
2People’s Security Academy - Ministry of Public Security
ARTICLE INFO
ABSTRACT
Received:
29/8/2024
To draw conclusions from forensic DNA typing to trace individuals or
paternity testing, it is necessary to include statistic probability based
on allele and genotype frequencies specific to each population. The
use of 21 core STR loci in DNA typing are widely implemented,
however data on extended STR loci in the Vietnamese (Kinh)
population is still lacking. In this study, the frequency and
polymorphism assessment indices of alleles in the studied population
were calculated and surveyed to build a table on the frequency of
alleles of 21 gene loci of Kinh population according to the GlobalFiler
kit. The results built an allele frequency table of 21 gene loci,
identified a number of typical genetic characteristics such as the
highest and the lowest polymorphism locus, and some common
alleles. Research results are an essential data, providing scientific
basis for each forensic DNA conclusion, serving litigation
requirements.
Revised:
06/02/2025
Published:
07/02/2025
KEYWORDS
DNA profiling
21 STR loci
GlobalFiler
Allele frequency
Vietnamese
NGHIÊN CỨU TẦN SUẤT CÁC ALEN CỦA 21 LOCUS STR
Ở NGƯỜI KINH VIỆT NAM
Dương Thị Thu Thủy1*, Lê Thị Quỳnh2, Trần Văn Cường2, Lê Thị Thu Thủy1, Bùi Anh Tuấn1
1Viện Khoa học hình sự - Bộ Công an, 2Học viện An ninh nhân dân - Bộ Công an
THÔNG TIN BÀI BÁO
TÓM TẮT
Ngày nhận bài:
29/8/2024
Để đưa ra kết luận giám định ADN phục vụ truy nguyên cá thể hoặc
xác định quan hệ huyết thống, cần kèm theo con số xác suất dựa trên
dữ liệu tần suất alen và tần suất kiểu gen đặc trưng cho mỗi quần thể.
Việc sử dụng 21 locus STR lõi trong giám định ADN hình sự đã
được thực hiện rộng rãi trên thế giới và ở Việt Nam, tuy nhiên dữ liệu
của các locus STR mở rộng trên quần thể người Việt (Kinh) hiện vẫn
còn thiếu. Trong nghiên cứu này, tần suất và các chỉ số đánh giá tính
đa hình các alen trong quần thể nghiên cứu được tính toán khảo sát
nhằm xây dựng được bảng dữ liệu về tần suất các alen của 21 locus
gen của người Việt (Kinh) theo bộ kit GlobalFiler. Kết quả nghiên
cứu đã xây dựng được bảng tần suất alen của 21 locus gen, xác định
được một số đặc điểm di truyền đặc trưng như locus có tính đa hình
cao nhất và thấp nhất, một số alen phổ biến. Kết quả nghiên cứu là
nguồn dữ liệu thiết yếu, cung cấp căn cứ khoa học cho mỗi kết luận
giám định ADN, phục vụ các yêu cầu tố tụng.
Ngày hoàn thiện:
06/02/2025
Ngày đăng:
07/02/2025
TỪ KHÓA
Giám định gen (DNA)
21 locus gen
GlobalFiler
Tần suất các alen
Người Việt Nam
DOI: https://doi.org/10.34238/tnu-jst.11032
* Corresponding author. Email: thuthuysinhhoc@gmail.com

TNU Journal of Science and Technology
230(05): 353 - 360
http://jst.tnu.edu.vn 354 Email: jst@tnu.edu.vn
1. Giới thiệu
Giám định DNA là phương pháp nghiên cứu, phân tích ở mức độ phân tử (nghiên cứu đặc
điểm cấu trúc phân tử DNA) từ các dấu vết, mẫu vật có nguồn gốc sinh vật bằng các kỹ thuật
sinh học phân tử. Việc ứng dụng kỹ thuật phân tích DNA đã giúp ích rất nhiều cho công tác điều
tra, xét xử tội phạm [1]. Đây là lĩnh vực giám định cho phép truy nguyên cá thể với độ chính xác
cao hơn hẳn các phương pháp nhận dạng truyền thống.
Theo lý thuyết di truyền học, mỗi quần thể người (dân tộc, tộc người) khác nhau có những đặc
điểm di truyền đặc trưng, thể hiện bằng sự phân bố tần suất các alen trong mỗi quần thể là khác
nhau và không thể áp dụng cơ sở dữ liệu của quần thể này cho một quần thể khác [2], [3]. Trong
giám định DNA các nhà khoa học hình sự phải xem xét và chọn lọc những gen có tính đa alen
cao, khảo sát tần suất phân bố các alen xuất hiện trong từng quần thể, từ đó làm cơ sở để phân
tích, đánh giá tính toán xác suất và đưa ra kết luận giám định [4] - [6]. Việc thống kê tần suất
alen, tần suất dị hợp tử, chỉ số đa hình, khả năng phân biệt, khả năng loại trừ của từng locus STR
(Short Tandem Repeat) cùng các chỉ số kết hợp có vai tr quan trọng giúp đánh giá đúng mức độ
tin cậy của php phân tích trong từng trường hợp cụ thể từ đó đưa ra kết luận giám định một cách
chính xác, khoa học [7] - [9].
Bộ kit GlobalFiler bao gồm 13 locus thuộc hệ CODIS, có khả năng phân biệt cao, độ nhạy
cao, hạn chế các chất ức chế và cho kết quả tối ưu với các mẫu bị phân hủy. Hiên nay, bộ kit
GlobalFiler với 24 locus gen (gồm 21 locus gen STR trên nhiễm sắc thể thường và 3 locus gen
trên nhiễm sắc thể giới tính) đã và đang được sử dụng rộng rãi phục vụ nhận dạng cá thể người
và xác định quan hệ huyết thống tại các phng thí nghiệm giám định DNA hình sự trên thế giới
và trong nước nên việc tính toán tần suất các alen của quần thể người ở Việt Nam theo bộ kit này
là vô cùng cần thiết và cấp thiết, làm cơ sở khoa học để phân tích, đánh giá và đưa ra kết luận
giám định trong giám định ADN hình sự được khách quan, khoa học.
2. Đối tượng và phương pháp nghiên cứu
2.1. Đối tượng nghiên cứu
250 mẫu máu được thu từ 250 cá thể người Việt (dân tộc Kinh) trên lãnh thổ Việt Nam, các
mẫu được thu thập ngẫu nhiên từ những người không có quan hệ huyết thống (người được thu
mẫu tình nguyện cung cấp mẫu và thông tin cá nhân), mẫu được lưu giữ vào thẻ giấy FTA@. 250
cá thể được điều tra về nguồn gốc quần thể thông qua hồ sơ nhân khẩu và căn cước, đảm bảo độ
tin cậy khi được thu mẫu.
2.2. Phương pháp nghiên cứu
2.2.1. Xác định hồ sơ kiểu gen của các mẫu
Toàn bộ các mẫu máu nghiên cứu được tiến hành tách chiết bằng phương pháp tách chiết vô
cơ (sử dụng Chelex® 100 Resin hãng Bio-rad), định lượng DNA (bằng bộ kit “Quantiblot
Human DNA Quantitation kit” của hãng Perkin Elmer), chạy phản ứng PCR (khuếch đại DNA
bằng bộ kit GlobalFiler trên máy luân nhiệt ProFlex (hãng Applied Biosystems, Mỹ)), điện di
huỳnh quang mao quản trên hệ thống máy giải trình tự ABI3500 để phát hiện sản phẩm PCR.
Các bước thí nghiệm được thực hiện theo quy trình giám định mẫu DNA tại Viện Khoa học hình
sự, Bộ Công an. Sau điện di, kết quả được xử lý bằng phần mềm Genemapper ID-x để xác định
các alen của mỗi locus.
2.2.2. Phân tích và tính tần suất alen
Chúng tôi sử dụng phương pháp đếm để thống kê số lượng alen trong toàn bộ kiểu gen phân
tích được từ 250 mẫu nghiên cứu sau đó, sử dụng phần mềm Excel (Microsoft Office) để xử lý số
liệu thống kê.

TNU Journal of Science and Technology
230(05): 353 - 360
http://jst.tnu.edu.vn 355 Email: jst@tnu.edu.vn
Để số liệu nghiên cứu về tần suất alen của các locus có thể ứng dụng được trong giám định
DNA hình sự, cần thiết phải đánh giá xem các locus được phân tích từ mẫu có đảm bảo cấu trúc
di truyền (tần số tương đối của các alen và tần số các kiểu gen) có ổn định hay không qua các thế
hệ, nghĩa là có tuân theo định luật Hardy-Weinberg hay không [10]. Do đó, cần kiểm tra sự phù
hợp giữa quần thể mẫu nghiên cứu với quần thể cân bằng l thuyết thông qua đánh giá chênh lệch
giữa tần số quan sát thực tế với phân bố l thuyết của các kiểu gen ở mỗi locus được nghiên cứu
có sai khác nhau hay không [2], [4].
2.2.2.1. Xác định và tính tần suất các alen
Tính tần suất các alen của từng locus theo số liệu thu được theo biểu thức sau:
𝑃𝑖 = ∑𝑖
𝑛
1
2𝑁
(1)
Trong đó: Pi: Tần suất của alen i; i: alen i quan sát thấy; n: cá thể thứ n; N: Tổng số cá thể (N = 250)
2.2.2.2. Phương pháp kiểm định giả thiết Khi bình phương ( χ2)
Công thức để tính giá trị χ2 như sau: χ2 = ∑(𝑶−𝑬)𝟐
𝑬
𝒌
𝟏 (2)
Trong đó: O: tần suất alen quan sát được từ thực nghiệm; E: tần suất quan sát được, tính theo
lý thuyết; k: số alen xác định được.
Giá trị χ2 được xác định tại bảng phân bố χ2 với các bậc tự do tương ứng với các mức xác suất
tương ứng. Trong các thí nghiệm sinh học, 3 mức xác suất thường được sử dụng là P = 0,05; P =
0,01 hoặc P = 0,001. Với 250 mẫu nghiên cứu, chúng tôi lựa chọn giá trị P = 0,05 là phù hợp [1],
[5], [8], [10].
Nếu khi bình phương tính được nh hơn khi bình phương l thuyết thì phân bố thực tế phù
hợp với phân phối l thuyết, nghĩa là mẫu phù hợp với quần thể l thuyết.
Sử dụng phần mềm Microsoft Excel để tính toán tần suất và các chỉ số đánh giá tính đa hình
các alen của quần thể nghiên cứu đồng thời xác định tần suất thu thập được đã đủ độ tin cậy để sử
dụng vào việc tính xác suất truy nguyên cá thể hoặc xác suất quan hệ huyết thống cha, mẹ - con
chưa. Các chỉ số được đánh giá gồm [1] - [6]:
- Tần suất dị hợp tử quan sát (Observed Heterozygosity - H(ob)) là tổng tần suất của từng locus
dị hợp tử quan sát được trong toàn bộ mẫu nghiên cứu:
H(ob) = Số cá thể dị hợp tử
Tổng số cá thể quan sát
(3)
- Tần suất dị hợp tử lý thuyết (Expected Heterozygosity (Hexp))
H(exp) = 1 − ℎ = 1 − ∑ pi2
𝑛
𝑖=1
(4)
Trong đó: h là số cá thể đồng hợp tử (homozygosity)
ℎ = ∑pi2
𝑛
𝑖=1
(5)
- Chỉ số đa hình (Polymorphism information content - PIC), chỉ mức độ đa hình của một locus:
PIC = 1 − ∑pi2
𝑛
𝑖=1 −(∑pi2
𝑛
𝑖=1 )2+∑pi4
𝑛
𝑖=1
(6)
- Khả năng phân biệt (Power of discrimination - PD): Chỉ số này cho ta biết khả năng phân
biệt giữa 2 cá thể không liên quan được xác định về kiểu gen trong quần thể nghiên cứu, chỉ số
này càng gần tới giá trị 1 thì khả năng phân biệt càng cao. Chỉ số PD có thể đánh giá khả năng
truy nguyên cá thể từ dấu vết.
PD = 1 − 2(∑pi2
n
i=1 )2+∑pi4
n
i=1
(7)
- Khả năng loại trừ (Power of exclusion - PE): Chỉ số khả năng loại trừ nhằm xác định khả
năng ngẫu nhiên 2 cá thể không có quan hệ huyết thống mà trên thực tế lại có thể có các alen
giống nhau. Giá trị của chỉ số càng gần tới 1 thì khả năng nhận định sai về huyết thống trên lý
thuyết càng nh. Mỗi locus có khả năng loại trừ khác nhau, vì vậy, nó có vai tr quan trọng khác
nhau trong việc tính toán độ tin cậy. Locus càng có khả năng loại trừ cao thì càng có nghĩa
trong giám định truy nguyên cá thể và xác định huyết thống cha - mẹ con.

TNU Journal of Science and Technology
230(05): 353 - 360
http://jst.tnu.edu.vn 356 Email: jst@tnu.edu.vn
PE = 1 − 2 ∑pi2
𝑛
𝑖=1 − 2(∑pi2
n
i=1 )2+ 2 ∑pi4
𝑛
𝑖=1 −∑pi3
𝑛
𝑖=1 + 3 ∑pi3∑pi3
𝑛
𝑖=1
n
i=1
(8)
- Chỉ số quan hệ huyết thống (Paternity index - PI): là giá trị tính toán được đưa ra từ một
locus, phản ánh khả năng gấp bao nhiêu lần cá thể đang được phân tích là người cha (mẹ) sinh
học so với một cá thể được lựa chọn ngẫu nhiên trong cùng quần thể. Nếu PI ≤ 1, locus đó hoàn
toàn không có nghĩa trong việc xác định huyết thống cha, mẹ - con. Nếu PI >1, thì locus đó có
giá trị trong việc xác định huyết thống cha, mẹ - con. Tính đa hình của locus đó càng lớn thì giá
trị này càng cao và càng có giá trị cao trong việc xác định huyết thống cha, mẹ - con.
PI (TPI)= H+h
2h =(1−h)+h
2h =1
2h =1
2(∑pi2)
𝑛
𝑖=1
(9)
Trong đó: pi: là tần suất của alen thứ i trong quần thể có n alen; h = đồng hợp tử; H = dị hợp tử.
2.2.2.3. Các chỉ số kết hợp đánh giá giá trị bảng tần suất alen
- Chỉ số kết hợp khả năng loại trừ (Combined power of exclusion - CPE): Mỗi một bảng tần
suất có một giá trị kết hợp khả năng loại trừ khác nhau dựa vào tần suất alen và số alen của tộc
người tính được. Trong thang đánh giá, các chỉ số CPE có giá trị cao có nghĩa hơn giá trị CPE
thấp. L tưởng nhất là CPE càng gần giá trị 1,00 càng tốt, nếu chỉ số CPE là 1,00 có nghĩa là
không có khả năng buộc tội sai cho một nghi phạm nào đó khi có hai hồ sơ DNA giống nhau.
CPE = 1 - (1 - PE1)×(1 - PE2)×(1 - PE3)…(1 - PEn)
(10)
Trong đó: PEi là khả năng loại trừ của từng locus trong bảng tần suất
- Chỉ số kết hợp khả năng phân biệt (Power of discrimination - CPD) là chỉ số quan trọng để
đánh giá giá trị sử dụng của từng locus DNA trong bảng tần suất được tính.
CPD = 1 - (1 - PD1)×(1 - PD2) × (1 - PD3) ×… × (1 - PDn)
(11)
Trong đó: PDi là khả năng phân biệt của từng locus trong bảng tần suất
- Chỉ số kết hợp xác định quan hệ huyết thống đặc trưng (Combined Paternity index - CPI): là
chỉ số kết hợp giá trị PI của toàn bộ các locus được phân tích, phản ánh khả năng gấp bao nhiêu
lần cá thể đang được phân tích là người cha (mẹ) sinh học so với một cá thể được lựa chọn ngẫu
nhiên trong cùng quần thể. CPI = PI1 × PI2 × PI3 ×…× PIn (12)
3. Kết quả và bàn luận
Sau khi điện di kết quả thu được các alen của từng locus, chúng tôi so sánh với các alen trong
thang alen chuẩn [10] để xác định các alen đặc biệt đặc trưng, đồng thời tiến hành tính toán các
chỉ số đánh giá độ đa hình và xác suất thống kê (tần suất alen, các chỉ số H(ob), H(ex), PIC, PD, PE,
PI) đặc trưng cho quần thể mẫu nghiên cứu.
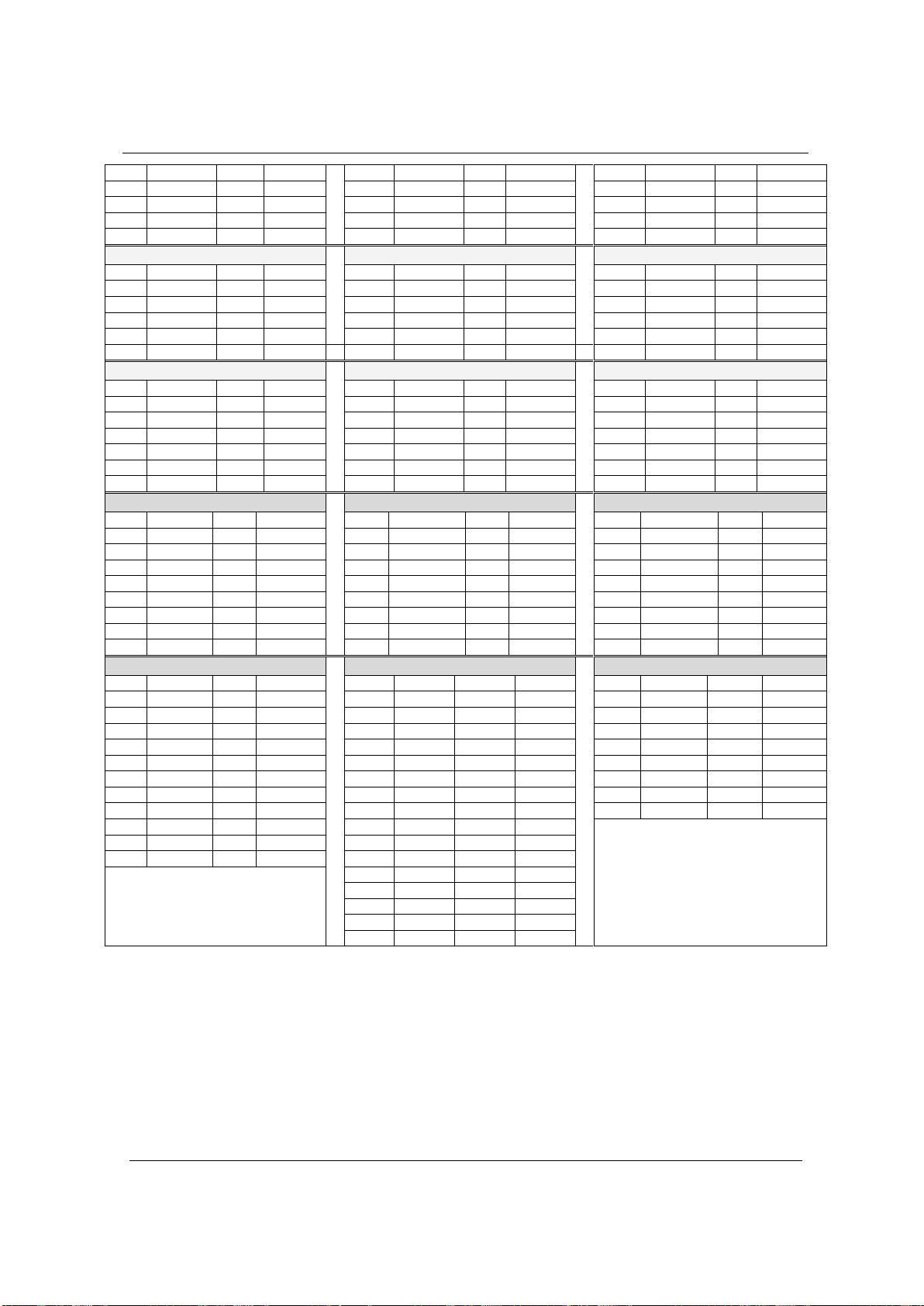
3.1. Bảng tần suất các alen của 21 locus STR trong quần thể nghiên cứu
Kết quả phân tích 250 hồ sơ kiểu gen STR của 250 cá thể người Kinh Việt Nam, cho thấy có
tổng số 10.500 alen (không kể các alen của locus trên các nhiễm sắc thể giới tính), gồm 62 loại
alen (từ 6 đến 35.2). Kết quả được thể hiện ở Bảng 1.
Bảng 1. Tần suất alen (%) của 21 locus trong quần thể nghiên cứu (N = 250) (1)
1.) Locus D3S1358
5.) Locus TPOX
11.) Locus TH01
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
14
4.0
17
25.0
7
0.2*
10
4.0
6
13.8
9
38.8**
15
31.0
18
5.0
8
55.4**
11
27.4
7
28.4
9.3
4.2*
16
34.0**
19
1.0*
9
10.8
12
2.2
8
5.8
10
9.0
3.) Locus D16S539
13.) Locus D22S1045
14.) Locus D5S818
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
8
0.4
11.2
0.2*
11
15.6
15
31.8**
7
2.4
12
22.6
9
24.6
12
24.8**
12
2.8
16
19.0
9
5.2
13
14.8
10
10.4
13
10.2
13
0.4*
17
24.0
10
23.8
14
0.6
11
28.0
14
1.4
14
6.4
18
2.6
11
30.4**
16
0.2*
15.) Locus D13S317
2.) Locus vWA
4.) Locus CSF1PO
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
TNU Journal of Science and Technology
230(05): 353 - 360
http://jst.tnu.edu.vn 357 Email: jst@tnu.edu.vn
(Ghi chú: *: tần suất alen thấp nhất **: tần suất alen cao nhất)
3.2. Đặc điểm các alen của 21 locus STR so với thang alen chuẩn trong quần thể nghiên cứu
Theo Bảng 1, các locus có các alen có tần suất xuất hiện cao nhất là: locus D16S539 với hai
alen có tần suất xuất hiện tương ứng là alen 9 và alen 12 (24,6% và 24,8%); locus D8S1179 có
alen 14 và alen 15 có tần suất xuất hiện cao nhất (tương ứng là 16,0% và 15,6%); D21S11 có alen
30 tần suất là 24,6%; alen 15 ở locus D18S51 là alen có tần suất cao nhất là 24,6%; D2S1338 tần
suất xuất hiện cao nhất ở alen 11 là 24,8%; locus D19S433 có alen số 13 và 14 là hai alen có tần
suất xuất hiện cao nhất đều lần lượt là 22,8% và 27,4%; alen 22 ở locus FGA có tần suất xuất
hiện cao nhất là 17,8%; locus D22S1045 có hai alen 16 và 17 trong quần thể nghiên cứu xuất
7
0.2*
11
23.0
14
28.2**
18
22.0
7
0.8
12
36.8**
8
31.0**
12
12.2
15
1.6
19
11.2
9
2.6
12.1
0.6*
9
13.4
13
3.2
15.2
0.2*
20
2.0
10
19.0
13
7.8
10
16.2
14
0.8
16
14.8
21
0.2*
11
30.6
14
1.8
17
19.8
16.) Locus D7S820
18.) Locus D10S1248
20.) Locus D12S391
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
7 7
0.8
11
36.0**
10
0.2*
15
24.4
15
1.8*
21
13.4
8
16.8
12
20.4
11
0.2*
16
9.6
17
9.6
22
10.4
9
6.2
13
2.4
12
7.0
17
1.4
18
16.0
23
10.2
9.1
1.0
14
0.2*
13
36.2**
18
0.4
19
18.2
24
1.8*
10
16.2
14
20.6
20
18.6**
6.) Locus D8S1179
9.) Locus D2S441
21.) Locus D2S1338
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
8
0.4
13.3
0.4
9
1.0
12
14.6
16
2.2
22
4.2
10
14.6
14
16.0**
9.1
1.8
12.3
0.2*
17
10.6
23
16.8
11
13.8
15
15.6
10
19.2
13
2.6
18
7.4
24
15.4
12
12.8
16
9.6
10.1
0.2*
13.1
0.2
19
19.6**
25
6.4
12.3
0.2*
17
0.8
11
24.8**
14
16.4
20
12.2
26
0.2*
13
15.4
18
0.4
11.3
17.8
15
1.2
21
5.0
7.) Locus D21S11
8.) Locus D18S51
10.) Locus D19S433
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
26
0.2*
31.2
9.0
10
0.2*
18
4.8
9
0.2*
14.2
10.0
28
4.8
32
3.4
11
0.4
19
4.0
10
0
15
8.6
29
24.2
32.2
17.2
12
5.4
20
2.4
11
0.2*
15.2
16.8
30
24.6**
33
1.0
13
14.6
21
1.2
12
3.4
16
0.4
30.2
1.6
33.2
6.0
14
18.8
22
1.6
12.2
0.6
16.2
4.0
30.3
0.2*
34.2
1.2
15
24.6**
23
0.2*
13
22.8
17
0
31
6.6
16
12.8
24
0.4
13.2
5.2
17.2
0.2*
17
8.4
25
0.2*
14
27.4**
18.2
0.2*
12.) Locus FGA
17.) Locus SE33
19.) Locus D1S1656
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
Alen
Tần suất
13
0.2*
23.2
1.8
8
0.2*
22.2
2.6
10
0.2*
16.3
0.8
16
0.6
24
13.8
11
0.2*
23
0.4
11
6.8
17
5.6
18
1.8
24.2
3.6
12
0.4
23.2
5.8
12
4.8
17.3
7.4
19
10.2
25
11.6
13.2
0.2*
24
0.2*
13
7.6
18
2.4
20
6.0
25.2
0.8
14
0.2*
24.2
7.0
14
8.2
18.3
1.2
20.2
0.2*
26
3.2
14.2
0.6
25.2
7.6
15
31.6**
19
1.2
21
12.2
26.2
0.4
15
1.2
26.2
9.2**
15.3
0.6
19.3
0.2*
21.2
1.4
27
0.6
16
2.4
27.2
7.0
16
21.4
22
17.8**
28
0.2*
17
3.2
28.2
7.8
22.2
1.2
29
0.2*
18
5.2
29.2
8.6
23
12.2
19
6.6
30.2
4.4
20
5.0
31.2
4.8
20.2
0.6
32.2
1.8
21
2.2
33.2
0.4
21.2
1.6
35.2
0.2*
22
2.4

























