
Journal of Water Resources & Environmental Engineering - No. 87 (12/2023)
39
Double Deep Q-Network algorithm for solving
traffic congestion on one-way highways
Nguyen Tuan Thanh Le
1*
, Dat Tran-Anh
1
, Quoc-Bao Bui
2
, Linh Manh Pham
3
Abstract: The problem of reducing traffi
c congestion on highways is one of the conundrums that the
transport industry as well as the government would like to solve. With the great development of high
technologies, especially in the fields of deep learning and reinforcement learning, the system u
sing
multi-
agent deep reinforcement learning (MADRL) has become an effective method to solve this
problem. MADRL is a method that combines reinforcement learning and multi-
agent modeling and
simulation approaches. In this article, we apply the Double Deep Q-
Network (DDQN) algorithm to a
multi-agent model of traffic congestion and compare it with two other algorithms.
Keywords: Traffic congestion problem, multi-agent deep reinforcement learning, agent-b
ased
simulation, autonomous vehicles
1. Introduction
*
Reinforcement learning (RL) is increasingly
becoming one of the areas of great interest, with
the advent of deep reinforcement learning (DRL),
when (Mnih et al., 2015) used a construct called
Deep Q-Network (DQN) to create an agent
capable of outperforming a professional player in
a series of 49 classic Atari games. Reinforcement
learning has also confirmed its position through a
number of achievements: AlphaFold tool,
developed by DeepMind (a subsidiary of Google)
successfully predicted the structure of proteins,
Self-Playing Game Agents have been successful
in training self-playing agents to beat professional
athletes in the game of Go. In addition, automated
robots are trained to drive autonomously, control
robots in space environments, and recognize and
interact with humans.
In reinforcement learning, an agent interacts
with an environment and performs actions to
1
Thuy loi University
2
School of Applied Mathematics and Informatics, Hanoi
University of Science and Technology, Hanoi, Vietnam
3
VNU University of Engineering and Technology
*
Corresponding author, ORCID ID: 0000-0002-3527-4066
Received 14
th
Aug. 2023
Accepted 3
rd
Dec. 2023
Available online 31
st
Dec. 2023
achieve some goals. The system receives
rewards from the environment based on its
actions. The goal of reinforcement learning is to
maximize the total reward value during the
interaction, which can be seen as an extension
of machine learning, where the system not only
learns from static data but also from dynamic
interactions with the environment. Key
challenges include stability, instability, and
dimensional curses. Standalone Q-Learning
divides state action value functionality into
independent tasks performed by individual
agents to solve the dimensional curse. However,
given a dynamic environment that is common
because agents can change their policies
concurrently, the learning process can be
volatile and variable. To enable information
sharing between actors, a suitable
communication mechanism is required. This is
important because it determines the
content/amount of information that each agent
can observe and learn from its neighbors, which
directly impacts the amount of information
uncertainty that can be minimized. Common
approaches include allowing neighboring agents
to i) exchange their information with each other
and directly use partial observations during the

Journal of Water Resources & Environmental Engineering - No. 87 (12/2023)
40
learning process (Tantawy et al., 2013); or ii) to
share hidden states as information (Wang et al.,
2020). While enabling communication is
important for stabilizing the training process,
existing methods have not yet examined the
impact of the content/amount of information
shared. For example, as each agent shares more
information with the others, the network needs
to manage a larger number of parameters and
thus converge at a slower rate, which actually
reduces stability. As reported by (Hasan et al.,
2020), additional information does not always
lead to better results. Therefore, it is very
important to choose the right information to
share. This approach is a machine learning
method that focuses on training the algorithm in
the direction of “cut and try” by trial and error.
The agent algorithm will evaluate a situation in
the current state. Perform an action and get the
result from the post-action impact environment.
Positive feedback will be called a reward, and
negative feedback will be a punishment for
making mistakes.
Traffic congestion is a big problem in
modern cities. While the use of traffic signals
reduces congestion to a certain extent, most
traffic signals are controlled by timers. Timing
systems are simple, but their performance can
deteriorate at intersections with inconsistent
traffic. Therefore, it is necessary to have an
adaptive traffic signal control method,
especially the simultaneous control of many
intersections. Therefore, applying reinforcement
learning to traffic control on highways is
necessary. In fact, reinforcement learning
models have recently been applied to effectively
solve the problem of reducing traffic congestion
on expressways (Saleem et al., 2022). In this
article, we take advantage of deep learning
network topologies, by combining DRL and
MAS (i.e., Multi-Agent System) techniques, for
traffic congestion reduction problem. The main
contribution of our study is to propose an
approach to applying the MADRL technique to
the problem of traffic congestion on highways.
The rest of the article is organized into four
sections. Firstly, Section 2 presents the related
works. Then, Section 3 introduces our MADRL
model for the traffic congestion problem (TCP).
Experiments and results are presented in Section
4. Finally, Section 5 presents conclusions and
future studies.
2. Related works
The problem of reducing traffic congestion
on highways can be divided into two main
categories: i) based on computer vision (Vision-
based approach), and ii) based on reinforcement
learning (RL-based approach).
2.1. Methods based on computer vision
In this approach, the television is used as the
primary instrument for recording the input
data. The advantage of using a television set is
that there is no need to wear any equipment
and it helps to reduce the cost of the system.
Moreover, the limited viewing angle of the
camera is very large, making it possible to
capture many people in the conversation at the
same time. Besides, these days smartphones are
all equipped with high-resolution television
sets which can be great potential for data input
of recognition systems. Therefore, computer
vision-based approaches to traffic control
systems for the day-to-day communication of
traffic operators are better and more convenient
to use. Due to the benefits mentioned above,
there have been many researchers focusing on
the proposal of visual-based traffic control by
various regions such as Russia (Makhmutova et
al., 2020), China (Xu and Mao, 2020), Korea
(Lee et al., 2019) and Vietnam (Huu et al.,
2022). In the article of (Makhmutova et al.,
2020), the author studied two new feature
extraction techniques of Combined Orient
Histogram and Statistical and Wavelet features
for vehicle identification in Russia. The
features are combined and fed into a neural
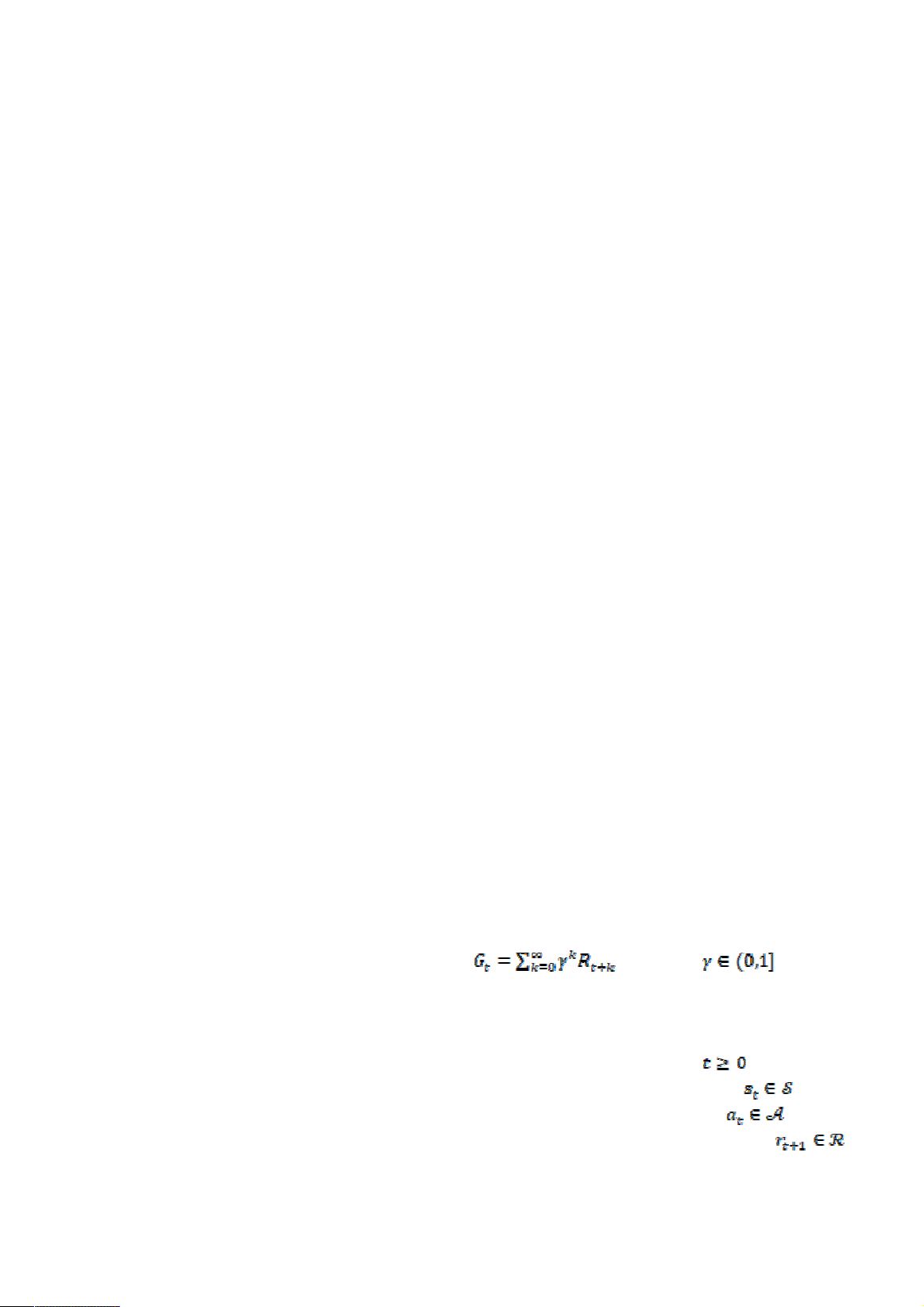
Journal of Water Resources & Environmental Engineering - No. 87 (12/2023)
41
network for training. The author of (Xu and
Mao, 2020) implemented both spatial and
temporal information capture in a traffic
classification model in China. First, a feature
extraction model of traffic objects is
performed, and the features are input to the
SVM classifier to identify 30 types of traffic
vehicles in China. Their results show that the
Linear kernel SVM is the classifier best suited
for vehicle identification. For means of
transport in Vietnam, the author of (Huu et al.,
2022) used local descriptions. In the feature
extraction module, they extract spatial and
contextual features to describe objects in
images. Then a set of features is learned by the
SVM classifier. Evaluation of their data set
results in an accuracy of 86.61%. From a
computer vision approach, vehicle recognition
is seen as a branch of action recognition that
restricts the movement of certain parts of the
road. There is a trend in the traffic object
recognition community where researchers are
trying to replace manual features with deep
learning models to improve accuracy and
reliability. In the article of (Lee et al., 2019),
the authors developed a license plate
recognition system in Korea based on a
convolutional neural network CNN from video
input. Their dataset consists of 10 words
selected from the Korean data. In (Krishnan et
al., 2022), the end-to-end embedding of a CNN
into a Hidden Markov Model (HMM) was
introduced.
2.2. Methods based on reinforcement
learning
Reinforcement learning is an attempt to
improve performance metrics to achieve one or
more long-term goals by learning to control a
system in more than one way. Get feedback
from an action or prediction via supervised
machine learning methods. Furthermore, the
future states of the system can be completely
changed by the predictions made. As a result,
the key role here is timing. Therefore, a
number of practical applications of
reinforcement learning have attracted the
attention of researchers through Artificial
Intelligence (Das and Rad, 2020).
Reinforcement learning can be divided into two
ways: i) Single-agent Reinforcement Learning
(SARL) (Kazmi et al., 2019); and ii) Multi-
agent Reinforcement Learning (MARL)
(Krishnan et al., 2022). For SARL, the
environment and actions are performed by a
single agent. In some practical problems, one
agent is not enough to process all the
information. So we thought of MARL which
has many agents and can solve many real-
world problems. Many research groups,
including (Wang et al., 2021-I), have formulated
the traffic signal problem (TSP) in the form of
discounting the cost Markov Decision Process
(MDP) and dynamic traffic signal policies
obtained by MARL. The article (Wang et al.,
2021-II) proposed a new MARL called
Collaborative Dual Q-Learning (Co-DQL),
which has many distinctive features. Co-DQL is
also based on the Q-Learning approach, instead,
it is highly scalable because it implements an
independent dual Q-Learning technique. In
(Razzaghi et al., 2022), the authors used group
collision avoidance and collision avoidance
strategies to improve traffic flow.
3. Proposed madrl model for tcp
3.1. RL components of our traffic model
RL is a learning method that helps an agent
to maximize its long-term return
, where is the
discount factor. This approach models the
learning process of the agent as a Markov
Decision Process (MDP) (Sutton and Barto,
2018). At the time step , the agent
observes the environment's state (state
space), then performs an action (action
space), and receives next reward
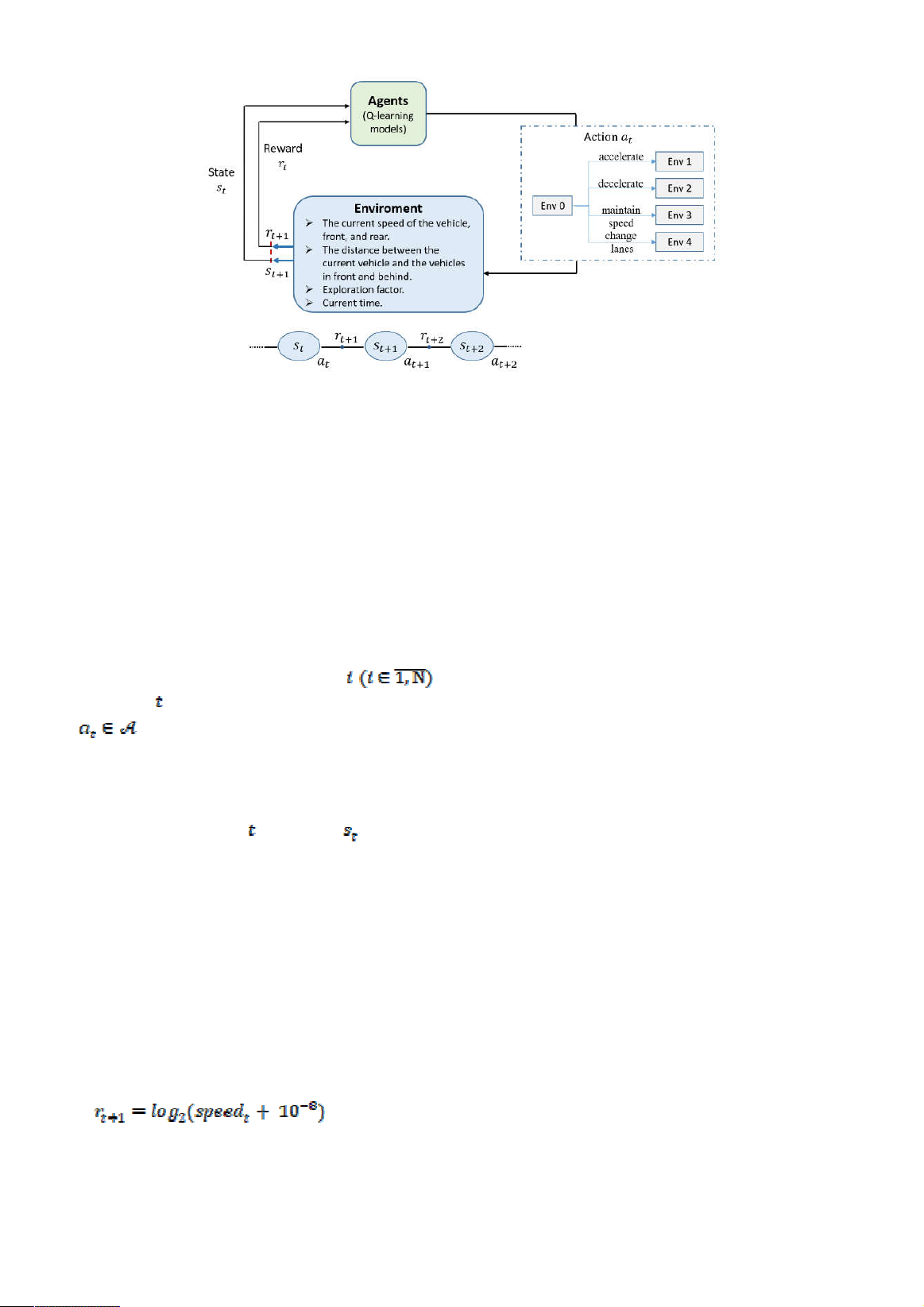
(reward space), as shown in Figure 1.
Journal of Water Resources & Environmental Engineering - No. 87 (12/2023)
42
Figure 1. The interactive loop between the Agent and Environment in our model
In particular, our model's four key
components of RL consist of agent, action,
state, and reward, which are described in detail,
as follows.
a. Agent
In our model, the agents are indexed
sequentially from 1 to N, which represent the
cars participating in traffic on the highway.
b. Action
In this model, each vehicle at
timestep can choose to perform an action
as one of the following four options: 1)
accelerate; 2) decelerate; 3) maintain speed; or
4) change lanes.
c. State
At each time step the states of an agent
are represented as a set of seven elements: 1)
current speed of the vehicle; 2) distance to the
vehicle ahead in the same lane; 3) current speed
of the vehicle ahead in the same lane; 4) distance
to the vehicle behind in the same lane; 5) current
speed of the vehicle behind in the same lane; 6)
exploration factor; and 7) current time.
d. Reward
The agent's reward is defined as a function of
the vehicle's speed at time t, as follows:
(Eq. 1)
3.2. Move strategies
The strategies implemented and used in this
study are techniques for guiding transportation
vehicles, including reinforcement learning
strategies such as Deep Q-Learning (DQL),
Deep Q-Network (DQN), and Double Deep Q-
Network (DDQN).
Q-learning is a fundamental reinforcement
learning algorithm that aims to learn an action-
value function (Q-function) representing the
expected cumulative rewards an agent can
obtain by taking a certain action in a given state.
It iteratively updates Q-values based on the
Bellman equation, which relates the Q-value of
a state-action pair to the immediate reward and
the Q-value of the next state. Q-Learning works
well for small state spaces but can struggle in
more complex environments due to its reliance
on tabular representation, which becomes
infeasible when dealing with large state spaces.
Meanwhile, DQN and DDQN are
advancements variations of the Q-Learning
algorithm in the field of reinforcement learning.
Both of these approaches employ deep neural
networks to approximate the Q-value function
and have demonstrated remarkable success in
solving complex problems. DQN extends the
traditional Q-learning method by employing
deep neural networks to estimate the Q-value
function instead of relying on a Q-table. On the
other hand, Double DQN is an enhancement of

Journal of Water Resources & Environmental Engineering - No. 87 (12/2023)
43
DQN that addresses the issue of “overestimation
bias” in Q-value estimation, where Q-values
tend to be higher than their actual values (Van
Hasselt et al., 2016). By utilizing two separate
neural networks, one for Q-value estimation and
another for action selection, Double DQN
mitigates the overestimation bias and improves
the overall algorithm's performance.
The algorithm provided below outlines the
general procedure for both DQN and DDQN:
1. Input data N, , , c
2. Result θ
3. Initialize replay memory D to capacity N.
Initialize network Q with random weights θ.
Initialize target
with random weights .
For each episode do
1. Initialize t 0
2. Use policy to select .
3. Perform action and move to the next stage and observe reward .
4. Store this transition ( in D.
5. Get sample random minibatch of transitions ( from D.
6. Set
7. Perform a gradient descent step on w.r.t θ.
8. In each step, reset = Q, = θ
9. Repeat from step 2
End
At step 2 of the above algorithm, we select as follows:
=
In DQN algorithm, at step 6, we set the target value according to the following equation:
In the case of Double DQN, we set the target with:
4. Experimental results
4.1. Experiment setup
The interface of our traffic model is divided
into three main areas:
1. Parameter adjustment area for input
settings
2. Simulation result area
3. Observation area for monitoring the
simulation process
a. Parameter adjustment area
To conduct simulations for this model, we
represent adjustable input parameters during the
experiments, including variables of the
environment and parameters of the
reinforcement learning algorithms. Regarding
the environmental variables, they encompass: 1)
number of vehicles; 2) number of lanes; 3)
acceleration coefficient; 4) deceleration

















![Bài Tập Cơ Lưu Chất: Ôn Thi & Giải Nhanh [Mới Nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20250812/oursky04/135x160/76691768845471.jpg)





![Bài tập thủy lực: Giải pháp kênh mương và ống dẫn [chuẩn nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20250812/oursky04/135x160/25391768845475.jpg)

