
MINISTRY OF EDUCATION AND TRAINING
HANOI UNIVERSITY OF SCIENCE AND TECNOLOGY
LE VAN HUNG
3D OBJECT DETECTIONS AND RECOGNITIONS:
ASSISTING VISUALLY IMPAIRED PEOPLE IN
DAILY ACTIVITIES
Major: Computer Science
Code: 9480101
ABSTRACT OF DOCTORAL DISSERTATION
COMPUTER SCIENCE
Hanoi −2018

The dissertation is completed at:
Hanoi University of Science and Technology
Supervisors:
1. Dr. Vu Hai
2. Assoc. Prof. Nguyen Thi Thuy
Reviewer 1: Assoc. Prof. Luong Chi Mai
Reviewer 2: Assoc. Prof. Le Thanh Ha
Reviewer 3: Assoc. Prof. Nguyen Quang Hoan
The dissertation will be defended before approval committee
at Hanoi University of Science and Technology:
Time..........., date.......month.......year.......
The dissertation can be found at:
1. Ta Quang Buu Library
2. Vietnam National Library

INTRODUCTION
Motivation
Visually Impaired People (VIPs) face many difficulties in their daily living. Nowa-
days, many aided systems for the VIPs have been deployed such as navigation services,
obstacle detection (iNavBelt, GuideCane products in Andreas et al. IROS, 2014; Ri-
mon et al.,2016), object recognition in supermarket (EyeRing at MIT’s Media Lab).
The most common situation is that the VIPs need to locate home facilities. However,
even for a simple activity such as querying common objects (e.g., a bottle, a coffee-cup,
jars, so on) in a conventional environment (e.g., in kitchen, cafeteria room), it may be
a challenging task. In term of deploying an aided system for the VIPs, not only the
object’s position must be provided but also more information about the queried object
(e.g., its size, grabbing objects on a flat surface such as bowls, coffee cups in a kitchen
table) is required.
Let us consider a real scenario, as shown in Fig. 1, to look for a tea or coffee
cup, he (she) goes into the kitchen, touches any surrounded object and picks up the
right one. In term of an aided system, that person just makes a query ”Where is a
coffee cup?”, ”What is the size of the cup?”, ”The cup is lying or standing on the
table?”. The aided system should provide the information for the VIPs so that they
can grasp the objects and avoid accidents such as being burned. Even when doing
3-D objects detection, recognition on 2-D image data and more information on depth
images as presented in (Bo et al. NIPS 2010, Bo et al. CVPR 2011, Bo et al. IROS
2011), only information about the objects label is provided. At the same time the
information that the system captured from the environment is the image frames of the
environment. Therefore the data of the objects on the table gives only a visible part of
the object like the front of cup, box or fruit. While the information that the VIPs need
are the information about the position, size and direction for safely grasping. From
this, we use the ”3-D objects estimation method” to estimate the information of the
objects.
By knowing the queried object is a coffee cup which is usually a cylindrical shape
and lying on a flat surface (table plane), the aided system could resolve the query by
fitting a primitive shape to the collected point cloud from the object. The objects in
the kitchen or tea room are usually placed on the tables such as cups, bowls, jars, fruit,
funnels, etc. Therefore, these objects can be simplified by the primitive shapes. The
problem of detecting and recognizing the complex objects in the scene is not considered
in the dissertation. The prior knowledge observed from the current scene such as a
1

Figure 1 Illustration of a real scenario: a VIP comes to the Kitchen and gives a
query: ”Where is a coffee cup? ” on the table. Left panel shows a Kinect mounted on
the human’s chest. Right panel: the developed system is build on a Laptop PC.
cup normally stands on the table, contextual constraints such as walls in the scene are
perpendicular to the table plane; the size/height of the queried object is limited, would
be valuable cues to improve the system performances.
Generally, we realize that the queried objects could be identified through simpli-
fying geometric shapes: planar segments (boxes), cylinders (coffee mugs, soda cans),
sphere (balls), cones, without utilizing conventional 3-D features. Approaching these
ideas, a pipeline of the work ”3-D Object Detection and Recognition for Assisting Visu-
ally Impaired People” is proposed. It consists of several tasks, including: (1) separating
the queried objects from table plane detection result by using the transformation orig-
inal coordinate system technique; (2) detecting candidates for the interested objects
using appearance features; and (3) estimating a model of the queried object from a
3-D point cloud. Wherein the last one plays an important role. Instead of matching
the queried objects into 3-D models as conventional learning-based approaches do, this
research work focuses on constructing a simplified geometrical model of the queried
objects from an unstructured set of point clouds collected by a RGB and range sensor.
Objective
In this dissertation, we aim to propose a robust 3-D object detection and recogni-
tion system. As a feasible solution to deploy a real application, the proposed framework
should be simple, robust and friendly to the VIPs. However, it is necessary to notice
that there are critical issues that might affect the performance of the proposed sys-
tem. Particularly, some of them are: (1) objects are queried in a complex scene where
cluster and occlusion issue may appear; (2) noises from collected data; and (3) high
computational cost due to huge number of points in the cloud data. Although in the
literature, a number of relevant works of 3-D object detection and recognition has been
attempted for a long time, in this study, we will not attempt to solve these issues sep-
arately. Instead of that, we aim to build an unified solution. To this end, the concrete
objectives are:
2
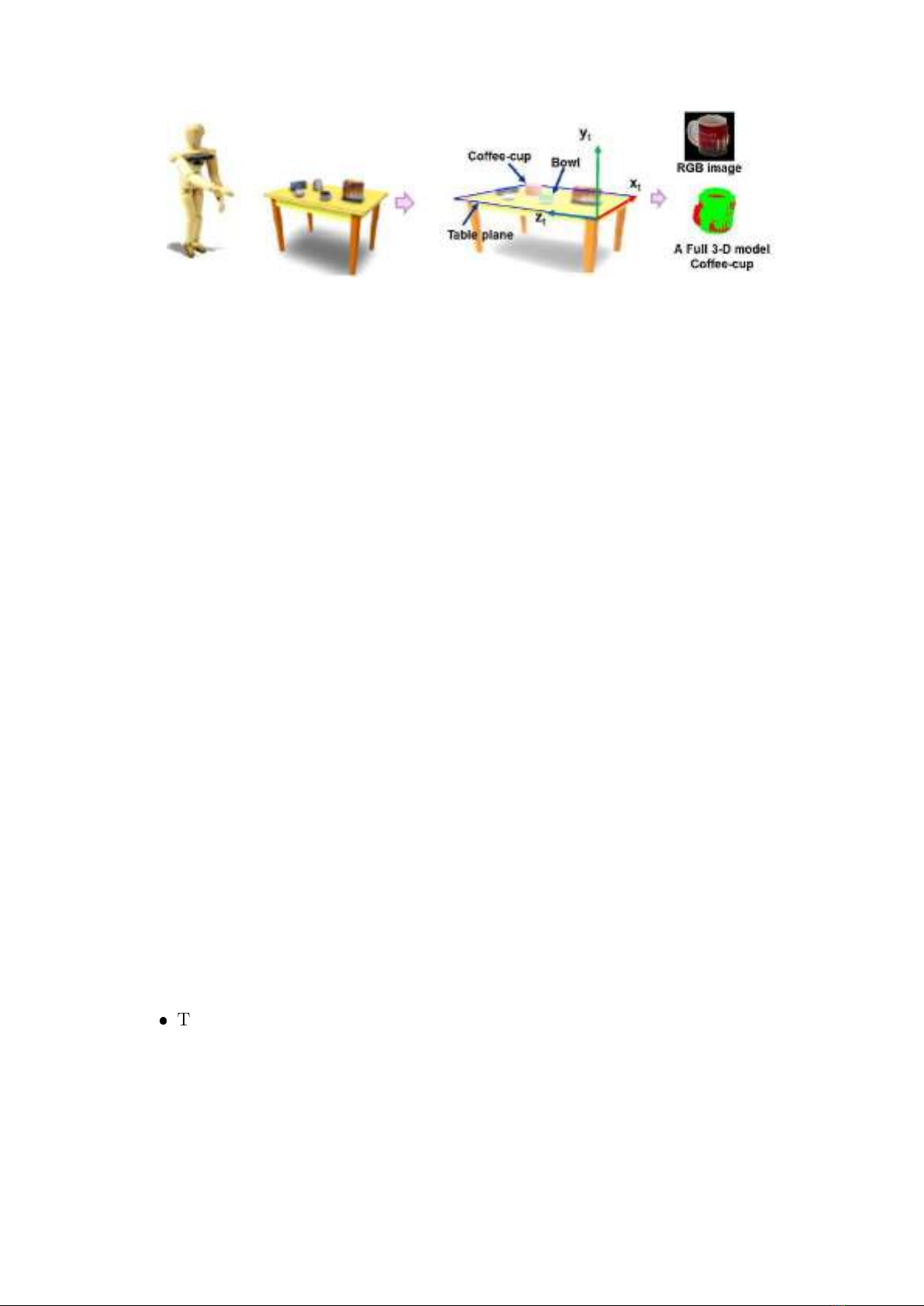
Figure 2 Illustration of the process of 3-D query-based object in the indoor environ-
ment. The full object model is the estimated green cylinder from the point cloud of
coffee-cup (red points).
- To propose a completed 3-D query-based object detection system in supporting
the VIPs with high accuracy. Figure 2 illustrates the processes of 3-D query-based
object detection in an indoor environment.
- To deploy a real application to locate and describe objects’ information in sup-
porting the VIPs grasping objects. The application is evaluated in practical
scenarios such as finding objects in a sharing-room, a kitchen room.
An available extension from this research is to give the VIPs a feeling or a way
of interaction in a simple form. The fact that the VIPs want to make optimal use of
all their senses (i.e., audition, touch, and kinesthetic feedback). By doing this study,
informative information extracted from cameras (i.e. position, size, safely directions
for object grasping) is available. As a result, the proposed method can offer an effective
way so that the a large amount of the collected data is valuable as feasible resource.
Context, constraints and challenges
Figure 1 shows the context when a VIP comes to a cafeteria and using an aided
system for locating an object on the table. The input of system is a query and output
is object position in a 3-D coordination and object’s information (size, height). The
proposed system operates with a MS Kinect sensor version 1. The Kinect sensor is
mounted on the chest of the VIPs and the laptop is warped in the backpack as shown
in Fig. 1-bottom. For deploying a real application, we have some constraints for the
scenario as the following:
❼
The MS Kinect sensor:
–A MS Kinect sensor is mounted on VIP’s chest and he/she moves slowly
around the table. This is to collect the data of the environment.
–A MS Kinect sensor captures RGB and Depth images at a normal frame rate
(from 10 to 30 fps) with image resolution of 640×480 pixels for both of those
image types. With each frame obtained from Kinect an acceleration vector
3

























