
NGÔN NGỮ HỌC TÍNH TOÁN: NHỮNG XU HƯỚNG MỚI, TRIỂN VỌNG VÀ THÁCH THỨC | 413
...................................................................................................................................................................................
XÂY DỰNG TỰ ĐỘNG DỮ LIỆU
HÌNH ẢNH - VĂN BẢN CHO CHỮ HÁN - NÔM
CHU HOÀNG PHÚC* - HOÀNG THIÊN ĐỨC**
Tóm tắt: Bảo tồn chữ Hán-Nôm là một sứ mệnh thiết yếu hiện nay do sự xuống cấp
của các tài liệu lịch sử theo thời gian. Xử lí thủ công là một phương pháp truyền thống cho
công việc này, nhưng lại tốn nhiều công sức và dễ gặp sai sót. Để giải quyết vấn đề này, các
tác giả đề xuất một công cụ xây dựng tự động dữ liệu hình ảnh - văn bản hỗ trợ cho việc số
hóa, lưu giữ các văn bản Hán - Nôm. Công cụ sử dụng mô hình trí tuệ nhân tạo để phát hiện
và nhận diện văn bản, đồng thời trích xuất văn bản từ hình ảnh. Bài viết thử nghiệm các mô
hình khác nhau, sử dụng các bộ dữ liệu NomNaOCR [11] và SacPhongHCMUS [10] để huấn
luyện. Kết quả thử nghiệm chứng minh tính hiệu quả của các mô hình được đề xuất, với mô
hình phát hiện đạt được 85,41% và nhận diện đạt 41,23%. Mặc dù cần thêm sự cải tiến, công
cụ này cung cấp một bước quan trọng trong việc tự động hóa việc bảo quản các tài liệu Hán
- Nôm. Từ khóa: Chữ Hán - Nôm, phát hiện văn bản, nhận diện văn bản, gán nhãn dữ liệu,
công cụ tự động
1. GIỚI THIỆU
Chữ Hán-Nôm là một ngôn ngữ cổ đã từng được sử dụng ở Việt Nam và cũng là một
phần quan trọng trong văn hóa của người Việt Nam cần được bảo tồn. Tuy nhiên, do tuổi đời
của nhiều tài liệu lịch sử viết bằng chữ Hán-Nôm, các văn bản thường khó đọc hoặc bị hỏng,
khiến thế hệ trẻ khó tiếp cận và hiểu những văn bản này. Ngoài ra, vì hầu hết các tác phẩm văn
học chữ Nôm có nguồn gốc từ dân gian nên điều kiện bảo quản thường không tốt, dẫn đến
nhiều tác phẩm chữ Nôm bị mất đi nhiều đoạn và không đầy đủ. Do đó, việc bảo tồn di sản
Hán - Nôm là một việc làm quan trọng cần được quan tâm.
Thách thức chính của vấn đề nằm ở quá trình số hóa tài liệu để bảo quản cho tương lai.
Việc xử lý thủ công thường không hiệu quả, tốn thời gian và dễ mắc sai sót do chất lượng của
một số tác phẩm không tốt. Một trong những giải pháp được đề xuất là tạo ra một mô hình trí
tuệ nhân tạo có thể giúp phát hiện và nhận diện văn bản Hán - Nôm, giúp giảm khối lượng
công việc cho những người chịu trách nhiệm cho việc bảo quản văn bản.
Để giúp ích hơn cho việc bảo tồn, trong bài báo này, các tác giả muốn tạo ra một công
cụ tự động sử dụng những mô hình nhận diện kí tự quang học đã được huấn luyện để trích
xuất văn bản từ hình ảnh đầu vào, đồng thời cung cấp một bộ dữ liệu có nhãn giúp cải thiện
các bài toán nhận diện ký tự quang học, dịch thuật sắp tới, qua đó đẩy nhanh quá trình số hóa
cũng như đóng vai trò là dữ liệu nền tảng để đào tạo mô hình để nhận diện văn bản tốt hơn
* Trường ĐH Khoa học Tự nhiên - ĐHQG TP. HCM; Email: 21125130@student.hcmus.edu.vn
** Trường ĐH Khoa học Tự nhiên - ĐHQG TP. HCM; Email: 21125076@student.hcmus.edu.vn

414 | KỶ YẾU HỘI THẢO KHOA HỌC QUỐC GIA 2024
...................................................................................................................................................................................
trong tương lai. Bằng cách tự động hóa nhiệm vụ này, chúng ta có thể giảm công sức và thời
gian cần thiết của hầu hết các học giả và các nhà nghiên cứu. Điều này đảm bảo các học giả
có thể tập trung nhiều hơn vào việc nghiên cứu các văn bản, thay vì dành thời gian cho việc
xử lí thủ công.
Bài báo này sẽ đóng góp hai mô hình, một cho việc phát hiện, và mô hình còn lại cho
việc nhận diện kí tự. Phần còn lại của bài viết này có cấu trúc như sau: Phần 2 tóm tắt các cách
khác nhau để giải quyết các vấn đề trong phát hiện và nhận diện văn bản. Phần 3 trình bày tập
dữ liệu mà các tác giả đã thu thập và công cụ được sử dụng để chú thích dữ liệu. Phần 4 đề
cập các phương pháp các tác giả đã thử nghiệm cho việc phát hiện và nhận diện. Phần 5 trình
bày kết quả đạt được sau khi đào tạo các mô hình với dữ liệu Hán - Nôm thu thập được. Phần
6 nêu ra kết luận và dự định trong tương lai của các tác giả về vấn đề này.
2. CÁC CÔNG TRÌNH LIÊN QUAN
Để xây dựng tự động dữ liệu hình ảnh - văn bản cho chữ Hán-Nôm, thông thường sẽ
cần hai mô hình riêng biệt, một để phát hiện văn bản và một để nhận diện văn bản. Hình ảnh
đầu vào trước tiên sẽ sử dụng mô hình phát hiện để chú thích các vùng văn bản tiềm năng. Sau
đó, mô hình nhận diện sẽ nhận các vùng hình ảnh đó làm dữ liệu đầu vào để xuất ra tệp văn
bản chứa các ký tự nhận diện được trên vùng hình ảnh đó.
2.1. PHÁT HIỆN VĂN BẢN
Hầu hết các mô-đun phát hiện văn bản có thể được gắn nhãn là một trong hai loại: dựa
trên hồi quy và dựa trên phân đoạn. Các phương pháp dựa trên hồi quy đề xuất một tập hợp
các vùng chứa ảnh trong mỗi hình ảnh và sử dụng một thuật toán chọn lọc để loại bỏ các vùng
chồng lên nhau; Thông thường, thuật toán đó là một biến thể của non-maximum suppression
(NMS). EAST [1] đi theo cách tiếp cận đầu tiên, sử dụng một mạng nơ-ron duy nhất để trực
tiếp tạo ra các dự đoán ở cấp độ từ hoặc dòng văn bản. X. Zhou và các dồng tác giả đã phát
triển một hàm mất entropy chéo cân bằng theo lớp dựa trên bản đồ điểm được tạo ra từ tứ giác
và hộp có hướng bất kỳ; Hơn nữa, một thuật toán NMS nhận biết lân cận đã được thiết lập
trong công việc của họ, áp dụng cơ chế kết hợp thay vì bỏ phiếu như các thuật toán NMS khác.
Mặt khác, các phương pháp dựa trên phân đoạn tập trung vào các điểm ảnh của hình ảnh và
xem xét liệu mỗi điểm ảnh có được phân loại là một phần của văn bản hay không. Theo hướng
này, mô-đun DB [2] sử dụng phương pháp nhị phân hóa vào mạng phân đoạn để tối ưu hóa
tổng thể. Các tác giả đã đề xuất một hàm bước gần đúng và khả vi để tối ưu hóa nhị phân và
mạng lưới phân đoạn trong giai đoạn rèn luyện.
2.2. NHẬN DIỆN VĂN BẢN
Trong nhận diện văn bản ngoại cảnh, tất cả các mô hình có thể được chia thành hai
nhánh: nhận diện không theo ngữ cảnh và nhận diện phụ thuộc ngữ cảnh. Giống như tên gọi,
các kiến trúc không theo ngữ cảnh không dựa vào bất kỳ thông tin ngữ cảnh bên ngoài nào để
dự đoán các ký tự mà tập trung vào các đặc trưng trực quan của văn bản. Với chủ đề này,

NGÔN NGỮ HỌC TÍNH TOÁN: NHỮNG XU HƯỚNG MỚI, TRIỂN VỌNG VÀ THÁCH THỨC | 415
...................................................................................................................................................................................
Rosetta [3] sử dụng mô hình tích chập hoàn toàn nhận diện dựa trên ký tự được huấn luyện
với hàm mất mát CTC. Để xấp xỉ việc gán nhán tối ưu, các tác giả của hệ thống này đã chọn
một cách tiếp cận tham lam là lấy ký tự có khả năng nhất ở mọi vị trí của chuỗi, dẫn đến thời
gian tìm kiếm tuyến tính. Ở chiều ngược lại, các mô-đun nhận diện phụ thuộc ngữ cảnh sử
dụng thông tin ngữ cảnh để hỗ trợ nhiệm vụ nhận diện. SVTR [4] chia nhỏ văn bản hình ảnh
thành các patch nhỏ hai chiều; Các hình ảnh nhỏ này là các thành phần ký tự và có thể chỉ
chứa một phần của ký tự. Do đó, để thu được các gợi ý cho việc nhận diện giữa các thành phần
nhân vật, mã hóa hình ảnh theo patch cùng với self-attention đã được sử dụng.
3. BỘ DỮ LIỆU
Vì chữ Hán Nôm là ngôn ngữ cổ không còn được sử dụng trong xã hội Việt Nam hiện
nay nên dữ liệu chỉ có thể được thu thập từ các tài liệu cổ đã được số bởi nhiều học giả nghiên
cứu Hán - Nôm. Các tác giả thu thập các tài liệu này từ trang “Dữ liệu mở” [5] để xây dựng
tập dữ liệu.
Tập dữ liệu các tác giả thu thập được bao gồm các hình ảnh rõ ràng và không rõ ràng,
do ảnh hưởng của thời gian [Hình 1]. Một số trang hiển thị văn bản rõ ràng, trong khi những
trang khác bị mờ hoặc bị hỏng vì các tài liệu gốc đã cũ và bị ảnh hưởng bởi môi trường bảo
quản trong những năm qua, dẫn đến các tài liệu kỹ thuật số cũng bị ảnh hưởng. Điều này đặt
ra một thách thức cho các tác giả trong quá trình ghi nhãn dữ liệu thủ công và quá trình đào
tạo mô hình. Vì vậy, việc tiền xử lý dữ liệu cần phải được tiến hành cẩn thận để có được kết
quả tốt.
(a) Hình ảnh rõ ràng (b) Hình ảnh không rõ ràng
Hình 1: Ví dụ hình ảnh trong bộ dữ liệu (Nguồn: VNPF[13])
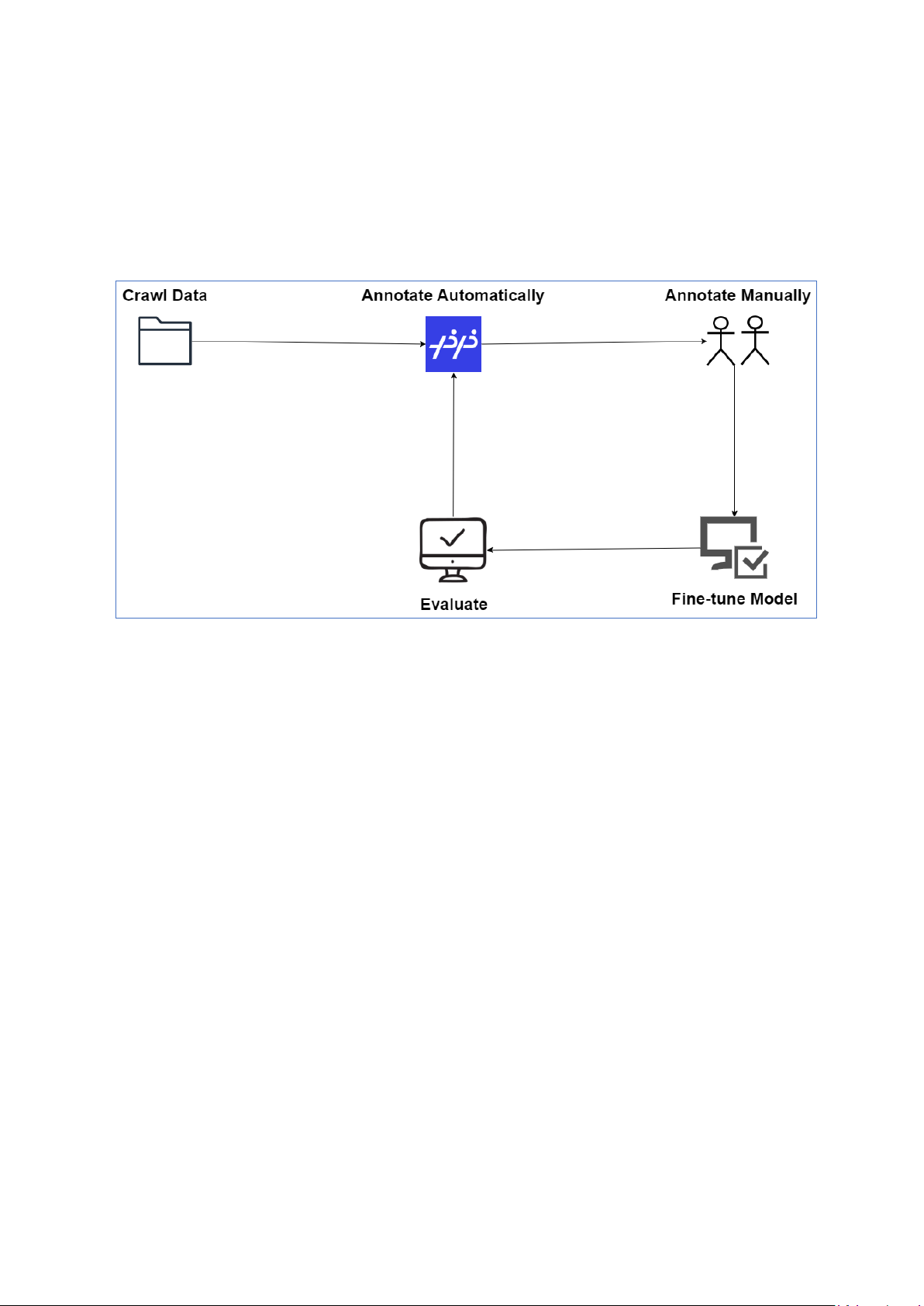
Để chú thích tập dữ liệu đã đề cập một cách hiệu quả, các tác giả sử dụng PPOCRLabel
[12], một công cụ được tạo bởi cộng đồng PaddleOCR để trợ giúp cho công việc. Công cụ
PPOCRLabel sử dụng mô hình để phát hiện các vùng hình ảnh chứa văn bản, do đó, chúng ta
có thể tận dụng PPOCRLabel cho quá trình chú thích vùng hình ảnh, biến thành quá trình bán
416 | KỶ YẾU HỘI THẢO KHOA HỌC QUỐC GIA 2024
...................................................................................................................................................................................
tự động. PPOCRLabel đầu tiên xử lý dữ liệu, sau đó các tác giả sẽ kiểm tra lại để đảm bảo
chất lượng của kết quả. Sau đó, những dữ liệu mới được xử lí này sẽ được sử dụng để tinh
chỉnh mô hình nhằm cải thiện độ chính xác trong các lần chạy trong tương lai. Quy trình làm
việc được minh họa bằng sơ đồ bên dưới [Hình 2].
Hình 2: Quy trình chú thích
Vì dữ liệu các tác giả thu thập được không có nhãn để huấn luyện mô hình, các tác giả
quyết định sử dụng tập dữ liệu NomNaOCR làm dữ liệu huấn luyện. Bộ dữ liệu bao gồm các
tài liệu với nền trắng và chữ viết màu đen, phù hợp với hầu hết các tác vụ OCR trong việc số
hóa tài liệu Nôm.
Sử dụng tập dữ liệu này làm nền tảng, các tác giả có thể tinh chỉnh mô hình với dữ liệu
được gán nhãn bổ sung. Quá trình lặp đi lặp lại này sẽ giúp đảm bảo rằng mô hình sẽ xử lí
được nhiều kiểu và chất lượng văn bản Hán-Nôm, cải thiện khả năng xử lí của mô hình với
các loại văn bản Hán-Nôm khác nhau. Đây sẽ là cơ sở cho một hệ thống OCR mạnh mẽ trong
tương lai, giảm thiểu công sức cho các nhà nghiên cứu và học giả.
Ngoài bộ dữ liệu NomNaOCR bao gồm hình ảnh của 38.318 câu thơ, văn, các tác giả
cũng sử dụng một phần của bộ dữ liệu SacPhongHCMUS gồm 620 hình ảnh sắc lệnh được
viết bởi các nhà nước phong kiến trong quá khứ. So với các dữ liệu trong bộ dữ liệu
NomNaOCR, những dữ liệu này có nền màu vàng và những hình ảnh rồng được vẽ có màu
tương tự như văn bản, đặt ra một thách thức trong việc chuẩn hóa nền, do chữ viết có thể bị
lẫn trong những hình vẽ.

NGÔN NGỮ HỌC TÍNH TOÁN: NHỮNG XU HƯỚNG MỚI, TRIỂN VỌNG VÀ THÁCH THỨC | 417
...................................................................................................................................................................................
4. PHƯƠNG PHÁP
4.1. PHÁT HIỆN
Vì Hán-Nôm là một ngôn ngữ cổ không còn được sử dụng ngày nay, việc phát hiện và
nhận diện các ký tự của chữ Hán-Nôm là một thách thức. Đối với tập dữ liệu mà các tác giả
thu thập được, các ký tự xuất hiện dưới nhiều hình dạng và điều kiện khác nhau. Một số có thể
được phát hiện dễ dàng, trong khi một số thì không, điều này có thể hiểu được vì các văn bản
này đều có từ hàng trăm năm trước. Do đó, để đạt được kết quả tốt hơn, các tác giả thử nghiệm
phương pháp dựa trên hồi quy và dựa trên phân đoạn để phát hiện văn bản, với các mô-đun
EAST và DB là các ví dụ tương ứng cho mỗi phương thức.
4.1.1. EAST
EAST là một phương pháp dựa trên hồi quy dự đoán trực tiếp các vùng chứa chữ hoặc
câu thông qua mạng tích chập hoàn toàn (FCN). Yếu tố thiết yếu của phương pháp này là một
mạng nơ-ron được huấn luyện để dự đoán các văn bản và hình dạng của vùng chứa văn từ
hình ảnh đầu vào một cách trực tiếp. EAST sử dụng những model nền tảng, như VGG-16 [7]
hoặc PVANET [8], để trích xuất bản đồ đặc trưng. Ngoài ra, để sử dụng hiệu quả các đặc trưng
khác nhau và duy trì chi phí tính toán tối thiểu, ý tưởng áp dụng U-Net [9] đã được sử dụng.
Các lớp tích chập kế tiếp hồi quy sẽ dự đoán hình dạng văn bản thông qua việc tạo ra
một bản đồ điểm số và nhiều bản đồ hình hình dạng. Bản đồ điểm được tạo bằng cách thu nhỏ
các cạnh của hình dạng ban đầu giúp cải thiện độ chính xác cho việc phát hiện. Trong khi đó,
khoảng cách đến 4 cạnh của vùng văn bản cũng được đo cho các bản đồ hình học, mà đầu ra
có thể là một hộp xoay hoặc một hình tứ giác. Vì văn bản Hán-Nôm có thể có nhiều hướng
khác nhau, khả năng dự đoán các vùng văn bản xoay của EAST giúp ích rất nhiều trong trường
hợp này.
Để có được kết quả cuối cùng, các vùng giới hạn được hợp nhất theo từng hàng lặp đi
lặp lại, với vùng hiện tại được hợp nhất với vùng được hợp nhất cuối cùng. Điều này giúp
giảm thời gian chạy xử lý hậu kỳ xuống O(n) trong các tình huống chỉ xuất hiện một vài dòng
văn bản so với thời gian chạy O(n2) của thuật toán NMS đơn giản.
4.1.2. DB
Các tác giả cũng đã thử nghiệm với Differentiable Binarization (DB), một phương pháp
dựa trên phân đoạn, tập trung vào phát hiện văn bản ở cấp độ điểm ảnh. Mô-đun này sử dụng
model xương sống có dạng kim tự tháp và có các đặc trưng được đưa về cùng một kích thước.
Sau đó, các đặc trưng đó được nối thành một đặc trưng duy nhất được sử dụng để dự đoán bản
đồ xác suất và bản đồ ngưỡng. DB phân loại từng điểm ảnh là một phần của văn bản hoặc nền,
cho phép dự đoán vùng văn bản có độ chi tiết cao. Cách tiếp cận này đặc biệt có lợi cho việc
phát hiện các ký tự phức tạp hoặc bố cục văn bản dày đặc được tìm thấy trong các tài liệu Hán
- Nôm.










![Bộ câu hỏi trắc nghiệm Văn bản tiếng Việt [chuẩn nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20251127/thuynhung051106@gmail.com/135x160/24021764296609.jpg)


![Bài giảng Ngôn ngữ học đối chiếu Nguyễn Ngọc Chinh [PDF]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20251101/vovu03/135x160/7471762139652.jpg)







![Ngân hàng câu hỏi môn Tiếng Việt thực hành [chuẩn nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20251003/kimphuong1001/135x160/21861759464951.jpg)
![Bài giảng Văn học phương Tây và Mỹ Latinh [Tập hợp]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20251003/kimphuong1001/135x160/31341759476045.jpg)


