BÀI Gi NG KHAI PHÁ D LI U WEBẢ Ữ Ệ
CH NG 1. GI I THI U CHUNGƯƠ Ớ Ệ
PGS. TS. HÀ QUANG TH YỤ
HÀ N I 10-2010Ộ
TR NG Đ I H C CÔNG NGHƯỜ Ạ Ọ Ệ
Đ I H C QU C GIA HÀ N IẠ Ọ Ố Ộ
1
N i dungộ
1. Gi i thi u v khai phá textớ ệ ề
2. Gi i thi u v khai phá webớ ệ ề
2

1. Gi i thi u v khai phá textớ ệ ề
Khái ni mệ
S c n thi t c a khai phá textự ầ ế ủ
Đ c tr ng c a khai phá textặ ư ủ
Các bài toán c b n trong khai phá textơ ả
M t ví d v bài toán khai phá textộ ụ ề
Xu h ng nghiên c u khai phá Textướ ứ
3

Khái ni mệ
Ti p c n v khái ni m khai phá textế ậ ề ệ
Khai phá text là khai phá d li u đ i v i lo i d li u text.ữ ệ ố ớ ạ ữ ệ
Quá trình phát hi n tri th c m i, có giá tr , ti m n trong t p h p văn b n ệ ứ ớ ị ề ẩ ậ ợ ả
Mang tính đa d ng v phát bi u khái ni m khai phá d li uạ ề ể ệ ữ ệ
N i dungộ
Khai phá text = Khai phá d li u + X lý ngôn ng t nhiên - XLNNTN ữ ệ ử ữ ự
(Natural Language Processing: NLP)
Các bài toán chung v khai phá d li u cho d li u đ c thùề ữ ệ ữ ệ ặ
M t s bài toán riêng đi n hình cho khai phá textộ ố ể
M i quan h gi a Khai phá Text và XLNNTNố ệ ữ
XLNNTN cung c p tài nguyên, công c c s cho khai phá Textấ ụ ơ ở
Khai phá Text m r ng các bài toán c a XLNNTNở ộ ủ
Đan xen gi a Khai phá Text v i XLNNTN ữ ớ
4
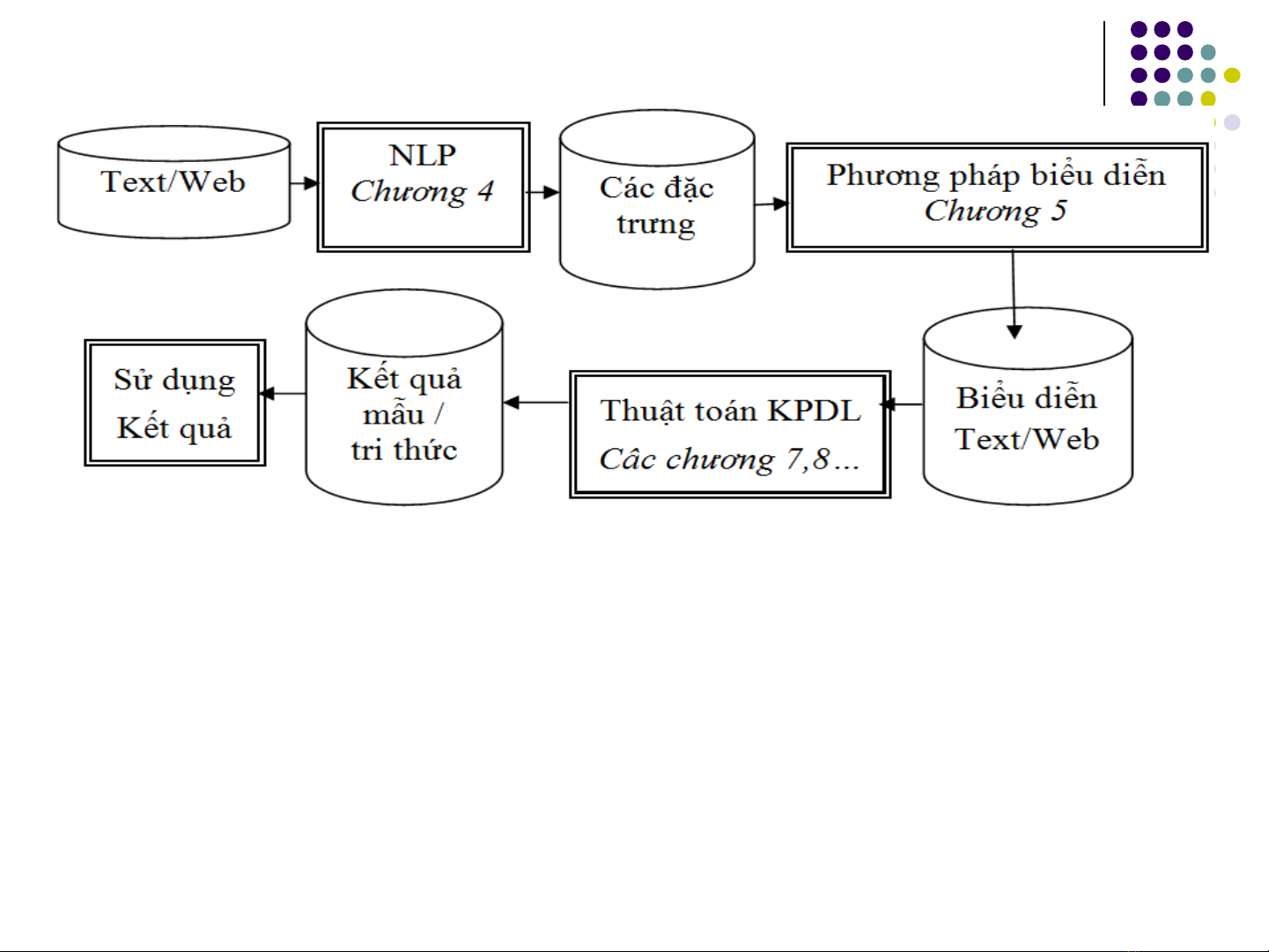
Quy trình khai phá text
Tuân theo quy trình chung c a khai phá d li uủ ữ ệ
Nh đã trình bày trong khai phá d li uư ữ ệ
Quy trình t i gi nố ả
Ti n x lýề ử
Công c c a X lý ngôn ng t nhiênụ ủ ử ữ ự
Mô hình c u trúc văn b nấ ả
Bi u di n văn b nể ễ ả
Phù h p v i thu t toánợ ớ ậ
X lý (khai phá) d li u theo d ng bi u di nử ữ ệ ạ ể ễ
Áp d ng khai phá d li uụ ữ ệ 5















![Tài liệu ôn tập môn Lập trình web 1 [mới nhất/chuẩn nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20251208/hongqua8@gmail.com/135x160/8251765185573.jpg)









