
801
ỨNG DỤNG THUẬT TOÁN K-MEANS TRÊN SPARK
ĐỂ PHÂN KHÚC KHÁCH HÀNG
Nguyễn Văn Trọng 1
1. Lớp CH22HT01, Trường Đại học Thủ Dầu Một.
TÓM TẮT
Công ty bán lẻ trực tuyến nhưng chiến lược tiếp thị đến khách hàng chưa được tối ưu
hóa nên chưa thể tăng lượng giao dịch mua hàng. Vì vậy cần có chiến lược tiếp thị lấy khách
hàng làm trung tâm bằng cách triển khai quản lý quan hệ khách hàng. Một trong những
phương pháp có thể áp dụng là phân khúc khách hàng. Việc phân khúc khách hàng có thể
được thực hiện bằng cách triển khai quy trình khai thác dữ liệu được thực hiện bằng thuật
toán phân cụm K-mean trên Spark và dựa trên mô hình RFM (Recency: Lần truy cập gần đây,
Frequency: Tần suất, Money: Tiền tệ). Xác định số cụm trong quá trình phân cụm bằng
phương pháp khuỷu tay. Kết quả phân tích cụm dựa trên giá trị khách hàng sử dụng phương
pháp kết hợp RFM tạo ra 4 loại đặc điểm khách hàng là khách hàng mới, khách hàng bình
dân, khách hàng tiềm năng cao và khách hàng mất đi.
Từ khóa: K-means, Phân cụm, Phân khúc khách hàng, Spark, RFM.
1. GIỚI THIỆU
Sự phát triển nhanh chóng của thông tin và công nghệ có tác động đến việc lưu trữ dữ
liệu ngày càng lớn như kho dữ liệu. Hàng năm công ty bán lẻ trực tuyến tạo ra một khối lượng
lớn dữ liệu, tuy nhiên dữ liệu này sẽ chỉ chiếm bộ nhớ lưu trữ nếu không được xử lý cho mục
đích tiếp thị hoặc ra quyết định. Việc tận dụng kho dữ liệu chưa được khai thác tối đa nên dữ
liệu dùng để phân tích chỉ là tổng giá trị của các giao dịch thu được.
Để đảm bảo doanh số bán hàng cần có cách tiếp cận phân khúc dựa trên xu hướng thay
đổi của người tiêu dùng như hiểu sâu hơn về sở thích, thói quen của khách hàng để công ty tạo
ra nhiều ưu đãi và chiến dịch có mục tiêu hơn đáp ứng được nhu cầu của người tiêu dùng. Sự
hiểu biết về khách hàng trong quản lý quan hệ khách hàng, là một chiến lược toàn diện trong
quá trình thu hút, giữ chân và hợp tác với khách hàng. Vì vậy, một cách hiệu quả là phân khúc
khách hàng dựa trên dữ liệu giao dịch bán hàng của công ty bán lẻ trực tuyến, bộ dữ liệu “Online
Retail” [11]. Bộ dữ liệu này đã được giới thiệu từ kho lưu trữ máy học của Đại học California.
Bộ dữ liệu chứa hơn 540 nghìn mẫu lịch sử mua hàng trực tuyến của hơn 4,3 nghìn khách hàng.
Trong nghiên cứu này, quy trình phân khúc khách hàng được thực hiện bằng cách khám phá
dữ liệu lịch sử giao dịch của khách hàng tại công ty bán lẻ trực tuyến, triển khai thuật toán phân
cụm K-Means trên Spark cùng với việc áp dụng RFM (Recency: Lần truy cập gần đây, Frequency:
Tần suất, Money: Tiền tệ). Để xác định số cụm tối ưu đã sử dụng phương pháp Elbow Method.
2. NGHIÊN CỨU LIÊN QUAN
Nghiên cứu của Wei và cộng sự vào năm 2016 [1] đã thực hiện nghiên cứu triển khai mô
hình RFM để phân tích giá trị khách hàng tại một bệnh viện thú y ở Đài Loan. Mục đích của

802
nghiên cứu này là xác định những khách hàng có giá trị dựa trên mô hình phân tích RFM và
phát triển chiến lược tiếp thị với các nghiên cứu điển hình về khách hàng sở hữu chó. Nghiên
cứu này áp dụng phương pháp bản đồ tự tổ chức (SOM) và K-means cùng với việc áp dụng
RFM (recency, frequency, monetary).
Kết quả từ việc triển khai phân cụm cùng với việc áp dụng RFM, có 12 cụm được chia
thành 2 nhãn là Best Customer và Uncertain Customer. Best Customer bao gồm các cụm 1, 3,
5, 7, 8, 10 và 12; Những Uncertain Customer bao gồm các cụm 2, 4, 6, 9 và 11.
Nghiên cứu của Dursun và Caber vào năm 2016 [2] đã thực hiện nghiên cứu điều tra hồ
sơ khách hàng ưa thích tại các khách sạn nằm ở Antalya, Thổ Nhĩ Kỳ. Mục đích của nghiên
cứu này là xác định mô hình phân tích RFM dựa trên khách hàng phù hợp với quy trình phân
khúc liên quan đến các đặc điểm nhân khẩu học của khách hàng. Nghiên cứu này áp dụng
phương pháp bản đồ tự tổ chức (SOM) và K-mean cùng với việc áp dụng RFM (recency,
frequency, monetary).
Kết quả triển khai mô hình phân tích RFM dựa trên phân cụm khách hàng với quy trình
phân đoạn liên quan đến đặc điểm nhân khẩu học của khách hàng, có 8 cụm được chia thành 8
nhãn là Loyal Customers, Loyal Summer Season Customers, Collective Buying Customers,
Winter Season Customers, Lost Customers, High Potential Customers, New Customers, và
Winter Season High Potential Customers.
Nghiên cứu Tavakoli và cộng sự vào năm 2018 [3] đã thực hiện một nghiên cứu về việc
triển khai phân khúc khách hàng bằng cách sử dụng việc phát triển mô hình RFM có tên là
R+FM. Mục đích của nghiên cứu này là phân loại khách hàng thành nhiều nhóm dựa trên hành
vi mua hàng, thông tin nhân khẩu học và địa lý của họ cũng như nghiên cứu điển hình về thuộc
tính tâm lý tại công ty Digikala hoạt động trong lĩnh vực bán lẻ trực tuyến.
Kết quả từ việc triển khai phân cụm R+FM dựa trên khách hàng, có 2 phân đoạn, phân
đoạn thứ nhất theo lần truy cập gần đây và thứ hai, phân đoạn theo giá trị khách hàng bao gồm
frequency, monetary and weight frequency và monetary. Phân khúc gần đây tạo ra 3 đặc điểm
khách hàng là active, lapsing, và lapsed trong khi phân khúc giá trị khách hàng tạo ra 4 cụm là
High Value, Medium with High Monetary, Medium with High Frequency, và Low Value. Kết
quả kết hợp các phân đoạn dựa trên mô hình R+FM, có 11 phân đoạn nhãn là Active High
Value, Active Medium with High Monetary, Active Medium with High Frequency, Active Low
Value, Lapsing High Value, Lapsing Medium Value, Lapsing Low Value, Lapsed High Value,
Lapsed Medium Value, Lapsed Low Value, và Lapsed Low Value.
Nghiên cứu của Peker và cộng sự vào năm 2017 [4] đã thực hiện một nghiên cứu về việc
triển khai phân khúc khách hàng bằng mô hình RFM sửa đổi có tên là “the LRFMP model case
study in the wholesale retail industry in Antalya, Turkey”. Mục đích của nghiên cứu này là phân
loại khách hàng thành nhiều nhóm dựa trên mô hình LRFMP và mô hình phân cụm thuật toán
K-means. Sự khác biệt giữa mô hình LRFMP và mô hình RFM là việc bổ sung các biến L và
P. Biến P thể hiện tính tuần hoàn, là tính định kỳ của các chuyến thăm của khách hàng nhằm
mô tả hành vi của khách hàng và đo lường mức độ thường xuyên của khách hàng, trong khi
biến L hiển thị độ dài, tức là khoảng thời gian tính theo ngày giữa lần truy cập đầu tiên và lần
cuối cùng của khách hàng. Nghiên cứu này sử dụng xác thực 3 cụm bao gồm chỉ số Silhouette,
Chỉ số Calinski Harabasz và chỉ số Davies Bouldin dùng để tìm cụm số tối ưu.
Kết quả từ việc triển khai phân cụm LRFMP dựa trên khách hàng, được chia thành 5 cụm
khách hàng high contribution loyal customers, low-contribution loyal customers, uncertain
customers, high spending lost customers và low spending lost customers.
803
3. CƠ SỞ LÝ THUYẾT
3.1. Phân khúc khách hàng
Phân khúc khách hàng là quá trình chia khách hàng thành các nhóm riêng biệt và đồng
nhất để phát triển các chiến lược tiếp thị khác nhau tùy theo đặc điểm của khách hàng.
Có nhiều loại phân khúc khách hàng khác nhau tùy theo các tiêu chí đặc điểm cụ thể được
sử dụng để phân khúc khách hàng. Phân khúc khách hàng truyền thống được dựa trên nghiên
cứu thị trường và nhân khẩu học [5].
Mục đích của việc phân khúc là điều chỉnh sản phẩm, dịch vụ và thông điệp tiếp thị cho
từng phân khúc. Một lợi ích khác của việc phân khúc khách hàng quan trọng là nó cho phép
công ty quản lý hiểu hành vi, sở thích của khách hàng và thu thập thông tin về các nhóm khách
hàng khác nhau [6]. Với cơ hội này, tổ chức có thể nhắm mục tiêu vào các nhóm khách hàng
có giá trị cao.
3.2. Phân tích RFM
Phân tích RFM là một cách tiếp cận phổ biến để hiểu hành vi mua hàng của khách hàng.
Nó khá phổ biến, đặc biệt là trong ngành bán lẻ. Đúng như tên gọi của nó, nó liên quan đến việc
tính toán và kiểm tra ba KPI – lần truy cập gần đây, tần suất và tiền tệ để tóm tắt các khía cạnh
tương ứng của mối quan hệ khách hàng với tổ chức [6].
- Lần truy cập gần đây (R), giá trị lần truy cập gần đây hiển thị thời gian kể từ giao dịch
mua hàng cuối cùng của khách hàng. Phạm vi càng nhỏ thì giá trị R càng lớn.
- Tần số (F), giá trị tần số thể hiện số lượng giao dịch trong một khoảng thời gian. Tần số
càng nhiều thì giá trị F càng lớn.
- Tiền tệ (M), giá trị tiền tệ thể hiện giá trị của khách hàng dưới dạng số tiền chi ra trong
quá trình giao dịch.
3.3. Apache Spark
Spark là công cụ xử lý, phân tích dữ liệu lớn. Spark đạt được hiệu năng cao đối với dữ
liệu theo batch, streaming data, dữ liệu đồ thị và tối ưu hóa truy vấn. Hỗ trợ ngôn ngữ Java,
Scala, R, Python.
Spark được thiết kế với khả năng truy cập cao và cung cấp các API đơn giản trong Python,
Java, Scala và SQL, bên cạnh đó là các thư viện tích hợp đa dạng. Điều đặc biệt là Spark có thể
hoạt động trên các cụm Hadoop và truy cập vào mọi nguồn dữ liệu Hadoop, bao gồm cả
Cassandra [7].
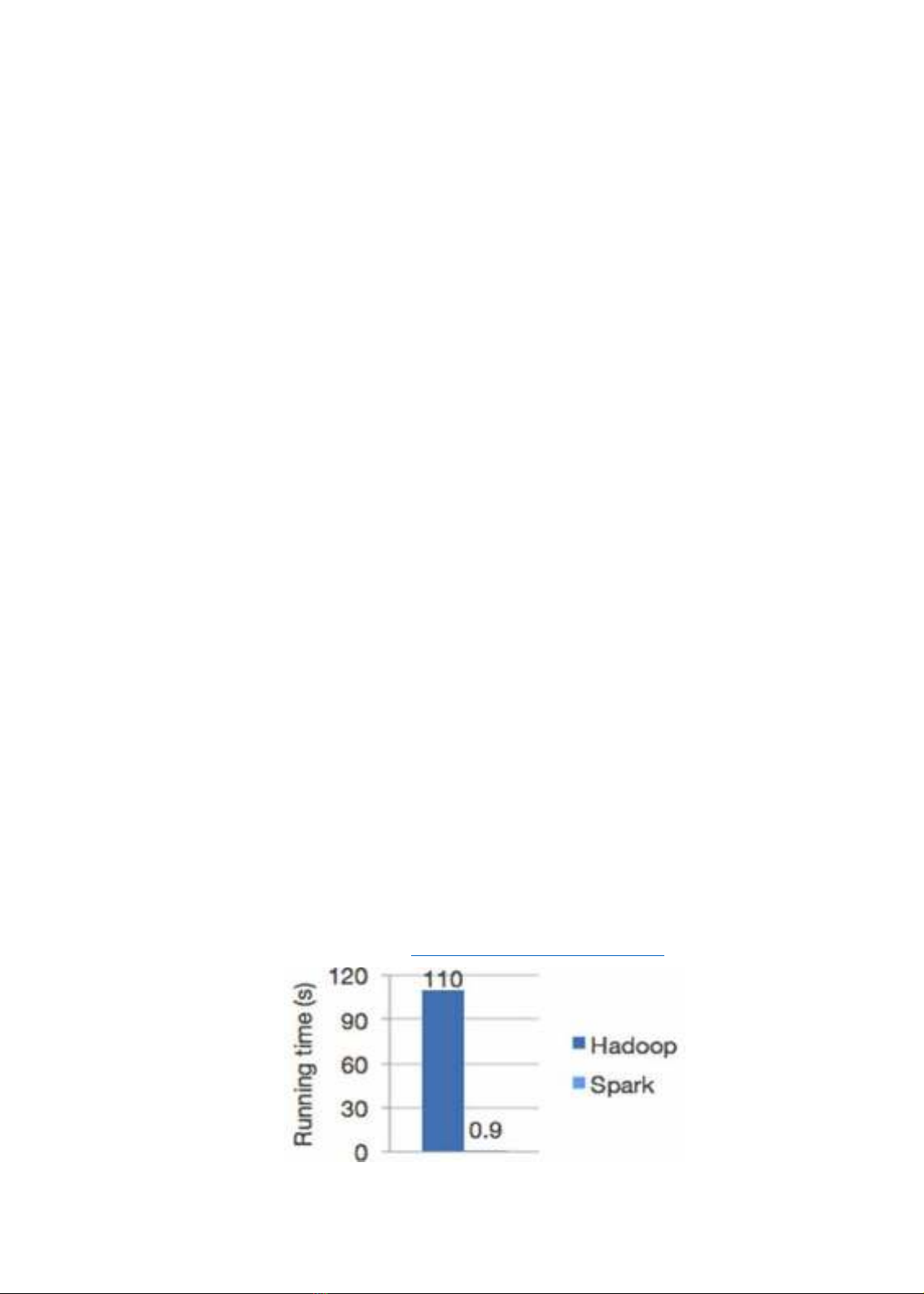
Tốc độ xử lý nhanh hơn hàng trăm lần Mapreduce của Hadoop. Hình 1 biểu thị tốc độ
tính toán trên Hadoop và Spark. (Nguồn https://spark.apache.org/mllib/).
Hình 1. Tốc độ tính toán trên Hadoop và Spark

804
Spark được phát triển sơ khởi vào năm 2009 như một dự án nghiên cứu trong phòng thí
nghiệm RAD của UC Berkeley, sau này trở thành AMPLab. Năm 2011, AMPLab bắt đầu phát
triển các thành phần cấp cao hơn trên Spark, chẳng hạn như Shark (Hive on Spark) và Spark
Streaming. Spark lần đầu tiên có nguồn mở vào tháng 3 năm 2010 và được chuyển giao cho
Apache Software Foundation vào tháng 6 năm 2013 [7].
Các thành phần của Apache Spark:
- Spark core: Là thành phần cốt lõi của Apache Spark.
- Spark Streaming: Xử lý dữ liệu streaming.
- Spark SQL: Xử lý dữ liệu bằng SQL/HQL.
- MLlib (machine learning): Xử lý dữ liệu bằng công cụ học máy.
- Graph X: Xử lý dữ liệu dựa trên lý thuyết đồ thị.
3.4. Thuật toán K-means
Thuật toán K-means là một thuật toán phân cụm dữ liệu không giám sát, được sử dụng
để phân các điểm dữ liệu trong một tập dữ liệu không được gắn nhãn vào các cụm khác nhau.
Kỹ thuật phân cụm K-mean rất đơn giản, chúng ta bắt đầu bằng việc mô tả thuật toán cơ
bản. Trước tiên, chọn K trọng tâm ban đầu, trong đó K là tham số do người dùng chỉ định, cụ thể
là số lượng cụm mong muốn. Sau đó, mỗi điểm được gán cho trọng tâm gần nhất và mỗi tập hợp
các điểm được gán cho trọng tâm sẽ là một cụm. Trọng tâm của mỗi cụm sau đó được cập nhật
dựa trên các điểm được gán cho cụm. Chúng tôi lặp lại các bước gán và cập nhật cho đến khi
không có điểm nào thay đổi cụm hoặc tương đương, cho đến khi các trọng tâm giữ nguyên [8].
Ta có thể tóm tắt thuật toán phân cụm K-means như sau [9]:
Input: Một ma trận dữ liệu và số lượng cụm cần phân loại.
Output: Ma trận chứa các tâm của các cụm và ma trận chứa các nhãn cho mỗi điểm dữ liệu.
Bước 1. Chọn ngẫu nhiên K điểm từ tập dữ liệu làm các tâm cụm ban đầu.
Bước 2. Gán mỗi điểm dữ liệu vào cụm có tâm gần nhất.
Bước 3. Nếu việc gán các điểm vào các cụm không thay đổi so với vòng lặp trước, kết
thúc thuật toán.
Bước 4. Cập nhật lại tâm của các cụm bằng cách tính trung bình của các điểm trong cụm.
Bước 5. Quay lại Bước 2.
4. PHƯƠNG PHÁP NGHIÊN CỨU
4.1. Đối tượng nghiên cứu
Đối tượng của nghiên cứu này là công ty bán lẻ trực tuyến thông qua các trang web. Công
ty đã có một kho dữ liệu đầy đủ.
Thời gian nghiên cứu từ ngày 25 tháng 01 năm 2024 đến ngày 25 tháng 03 năm 2024. Bộ
dữ liệu sử dụng là dữ liệu lịch sử giao dịch của khách hàng tại công ty bán lẻ trực tuyến.
4.2. Phương pháp nghiên cứu
4.2.1. Xác định vấn đề
Đơn vị được chọn làm đối tượng nghiên cứu trong giai đoạn nhận diện là công ty bán lẻ trực
tuyến. Kết quả của giai đoạn này là các vấn đề đặt ra, cụ thể là phân khúc khách hàng làm đầu vào
cho việc hoạch định chiến lược quản lý quan hệ khách hàng, đặc biệt là giữ chân khách hàng.

805
4.2.2. Thu thập dữ liệu
Việc thu thập dữ liệu là cần thiết để hỗ trợ chính trong quá trình phân khúc khách hàng.
Dữ liệu thu được ở định dạng excel (.xlsx) bao gồm 541909 dòng dữ liệu và 8 trường dữ liệu
là InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country
như trong Bảng 1.
Bảng 1. Biến dữ liệu thô của lịch sử giao dịch
Variable Name
Type
Description
InvoiceNo
Categorical
Mã đơn hàng, nếu mã này bắt đầu bằng chữ "C" thể hiện đơn
hàng đó bị hủy (Cancel)
StockCode
Categorical
Mã sản phẩm
Description
Categorical
Tên sản phẩm
Quantity
Integer
Số lượng sản phẩm trên đơn đặt hàng
InvoiceDate
Date
Ngày và giờ khi đơn hàng được tạo
UnitPrice
Continuous
Giá sản phẩm trên mỗi đơn vị
CustomerID
Categorical
Mã khách hàng
Country
Categorical
Quốc gia nơi khách hàng cư trú
4.2.3. Chuyển đổi dữ liệu
Dữ liệu thu thập được ở định dạng excel (.xlsx), mà việc phân tích dữ liệu sẽ thuật tiện
hơn khi dạng csv. Vì vậy, cần chuyển đổi sang .csv bằng python, thực hiện thông qua pandas
package.
4.2.4. Làm sạch dữ liệu
Quá trình làm sạch dữ liệu là loại bỏ dữ liệu trống hoặc không có giá trị và loại bỏ dữ liệu
ngoại lệ (đơn hàng bị hủy).
Sau khi lọc thì dữ liệu giảm đi đáng kể, số khách hàng giảm đi 33 người. Từ 541909 dòng
dữ liệu và 4373 khách hàng giảm xuống còn 532621 dòng dữ liệu và 4340 khách hàng.
4.2.5. Lựa chọn dữ liệu
Trong phần này, việc lựa chọn dữ liệu được thực hiện để điều chỉnh các thuộc tính được sử
dụng dựa trên nhu cầu trong quá trình phân cụm. Dữ liệu đã được thu thập sẽ được lựa chọn dựa
trên các biến có liên quan đến quá trình phân cụm và phân tích RFM. Chi tiết trong Bảng 2.
- Recency: Đo thời điểm mà khách hàng đã mua hàng lần cuối. Khách hàng mới mua
hàng gần đây được xem là có giá trị cao hơn so với khách hàng mua hàng lâu đến không mua
hàng nữa.
- Frequency: Đo tần suất mà khách hàng mua hàng trong một khoảng thời gian nhất định.
Khách hàng mua hàng thường xuyên được xem là có giá trị hơn so với những khách hàng mua
hàng ít lần.
- Monetary: Đo giá trị đặt hàng của khách hàng. Khách hàng đặt hàng có giá trị cao hơn
được xem là có giá trị cao hơn so với những khách hàng đặt hàng có giá trị thấp.
Bảng 2. Kết quả các biến RFM
Recency
Frequency
Monetary_value
CustomerID
97020
1
106.2
15070
362220
45
623.75
16718
91080
19
273.36
17850
111660
19
273.36
17850

















![Đề kiểm tra Quản trị logistics [mới nhất]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20251015/2221002303@sv.ufm.edu.vn/135x160/35151760580355.jpg)
![Bộ câu hỏi thi vấn đáp Quản trị Logistics [năm hiện tại]](https://cdn.tailieu.vn/images/document/thumbnail/2025/20251014/baopn2005@gmail.com/135x160/40361760495274.jpg)






