Nguyễn Hoài Phương –CH0403014- Email: phuongnh@dsp.com.vn
THUẬT TOÁN DBSCAN
(Nguồn: A Density-Based Algorithm for Discovering Clusters
in Large Spatial Databases with Noise
Martin Ester, Hans-Peter Kriegel, Jörg Sander, Xiaowei Xu
Institute for Computer Science, University of Munich
Oettingenstr. 67, D-80538 München, Germany
{ester | kriegel | sander | xwxu}@informatik.uni-muenchen.de)
Thuật toán DBSCAN ((Density Based Spatial Clustering of Applications with Noise)
do Martin Ester và các tác giả khác đề xuất là thuật toán gom tụm dựa trên mật độ, hiệu
quả với cơ sở dữ liệu lớn, có khả năng xử lý nhiễu.
Ý tưởng chính của thuật toán là vùng lân cận mỗi đối tượng trong một cụm có số đối
tượng lớn hơn ngưỡng tối thiểu. Hình dạng vùng lân cận phụ thuộc vào hàm khoảng cách
giữa các đối tượng (nếu sử dụng khoảng cách Manhattan trong không gian 2 chiều thì
vùng lân cận có hình chữ nhật, nếu sử dụng khoảng cách Eucler trong không gian 2 chiều
thì vùng lân cận có hình tròn).
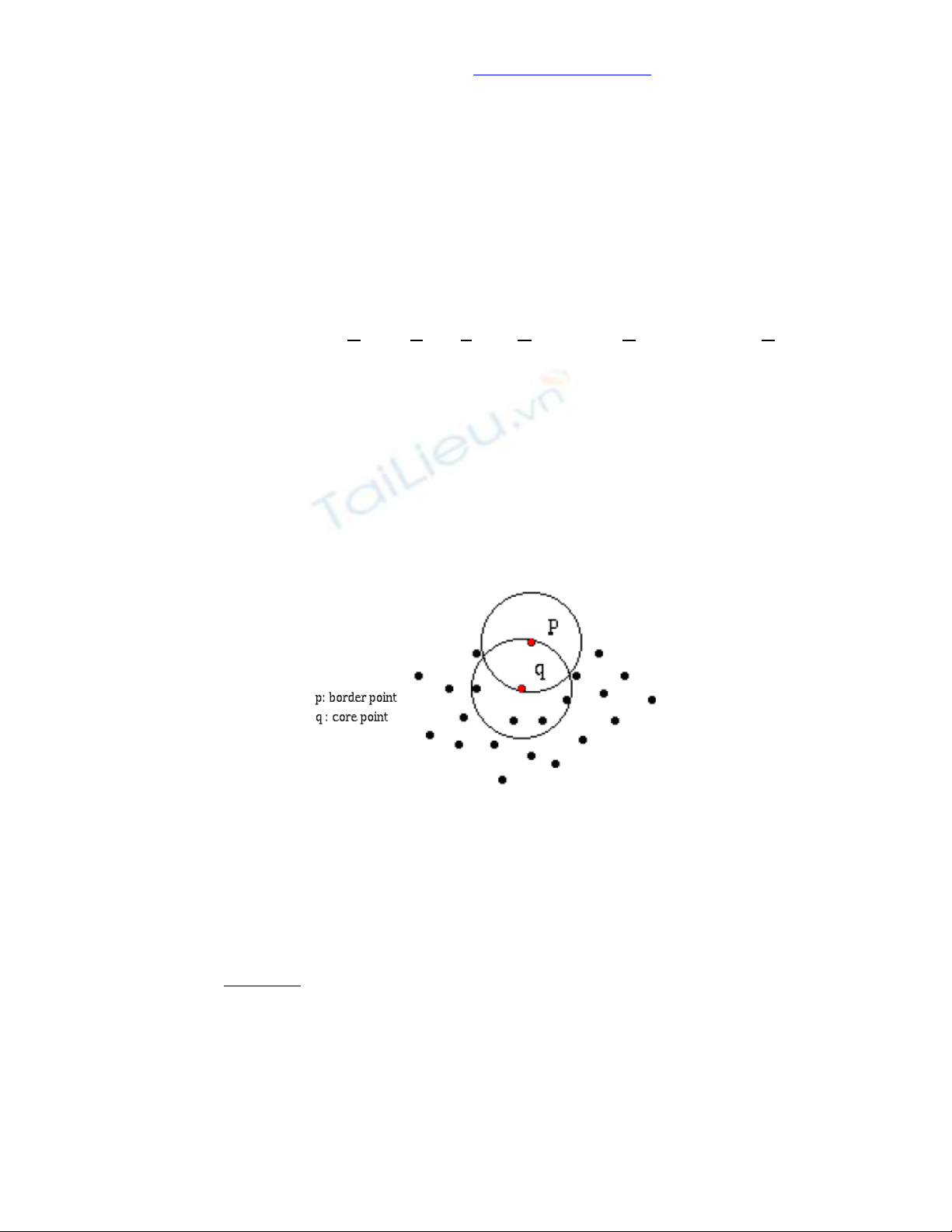
Các đối tượng trong mỗi cụm được phân làm 2 loại: đối tượng bên trong cụm (core
point: đối tượng lõi) và đối tượng nằm trên đường biên của cụm (border point: đối tượng
biên).
Hình 1. Đối tượng biên và đối tuợng lõi
I. Định nghĩa
Định nghĩa 1
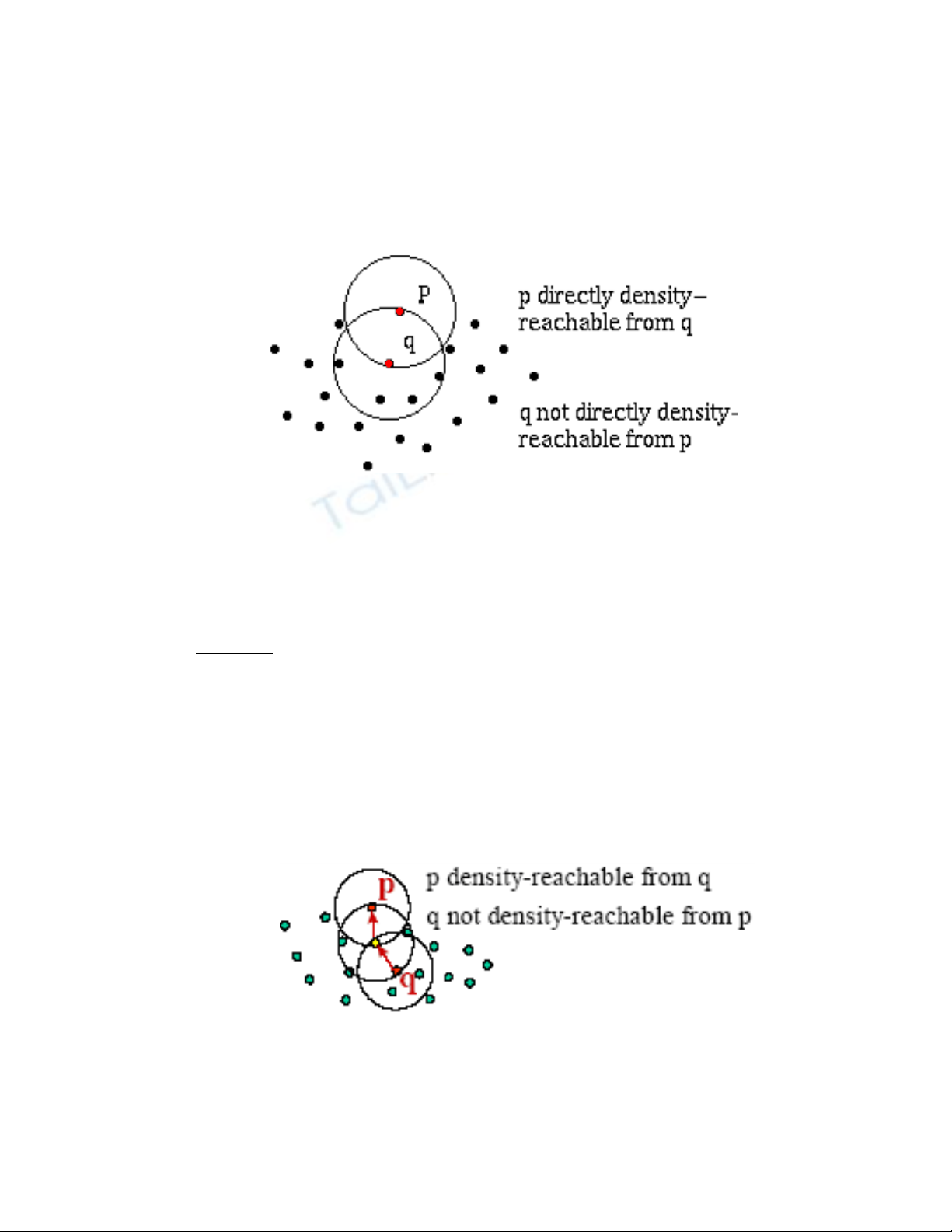
Vùng lân cận Eps của đối tượng p, ký hiệu NEps(p) là tập hợp các đối tượng q
sao cho khoảng cách giữa p và q dist(p,q) nhỏ hơn Eps.
NEps(p) = {q∈D | dist(p,q) ≤ Eps}.
Tính chất:
- Nói chung vùng lân cận của đối tượng biên có số đối tượng ít hơn đáng kể
so hơn đối tượng biên
Định nghĩa 2
Đối tượng p tới được trực tiếp theo mật độ (directly density-reachable) thỏa
Eps, MinPts từ đối tượng q nếu p∈NEps(q) và |NEps(q)| ≥ MinPts.
Data Minning –DBSCAN Trang 1/7