BÀI TOÁN SO SÁNH M R NGỞ Ộ
§ 1. SO SÁNH NHI U T L Ề Ỷ Ệ
Trong ch ng tr c chúng ta đã xét bài toán so sánh t l cáươ ướ ỷ ệ
th có đc tính A trong hai t p h p chính. b y gi chúng ta s mể ặ ậ ợ ấ ờ ẽ ở
r ng bài toán này b ng cách xét bài toán so sánh đng th i t l cáộ ằ ồ ờ ỷ ệ
th có đc tính A gi a nhi u t p h p chính.ể ặ ữ ề ậ ợ
Gi s ta có k t p h p chính Hả ử ậ ợ 1, H2,... Hk. M i cá th c aỗ ể ủ
chúng có th mang hay không mang đc tính A.ể ặ
G i pọ1 là t l có th mang đc tính A trong t p h p chínhỷ ệ ể ặ ậ ợ
Hi (i = 1, 2, ...k).
Các t l này đc g i là các t l lý thuy t mà chúng ta ch aỷ ệ ượ ọ ỷ ệ ế ư
bi t.ế
Ta mu n ki m đnh gi thi t sau:ố ể ị ả ế
Ho: p1 = p2 = ... = pk (t t c các t l này b ng nhau).ấ ả ỷ ệ ằ
T m i t p h p chính ừ ỗ ậ ợ Hi ta rút ra m t ng u nhiên có kíchộ ẫ
th c nướ i, trong đó chúng ta th y có mấi cá th mang đc tính A. các dể ặ ữ
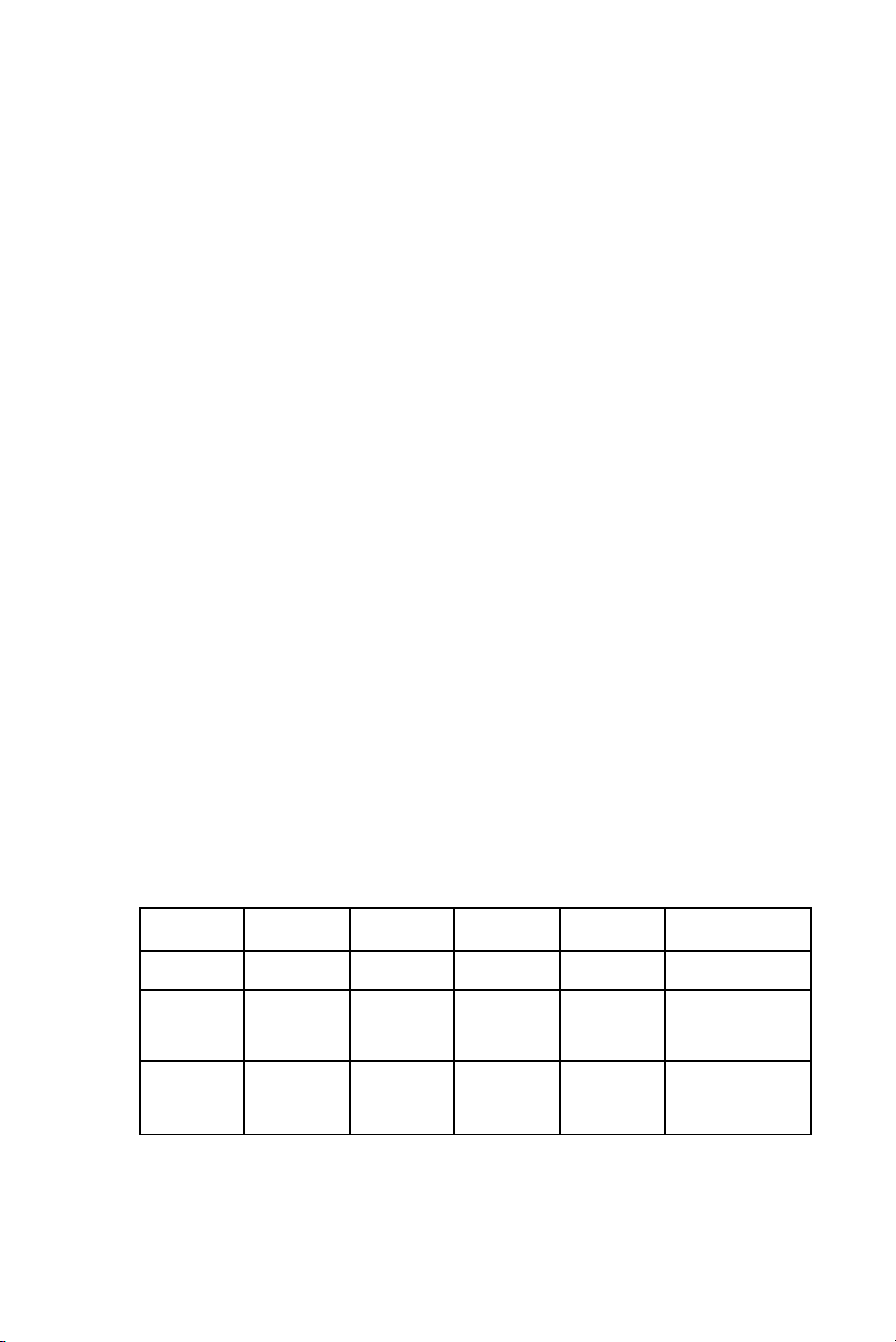
li u này đc trình bày trong b ng sau đây:ệ ượ ả
M uẫ1 2 ... k T ngổ
Có A m1m2... mkm
Không
A
l1l2... lkl
T ng ổn1n2... nkN = m + l =
ni
N u gi thi tế ả ế
Ho: p1 = p2 = ... = pk = p
1

Là đúng thì t l chung p đc c l ng b ng t s gi a sỷ ệ ượ ướ ượ ằ ỷ ố ữ ố
cá th đc tính A c a toàn b k m u g p l i trên t ng s cá th c aể ặ ủ ộ ẫ ộ ạ ổ ố ể ủ
k m u g p l i.ẫ ộ ạ
$
m
pN
=
T l cá th không có đc tính A đc c l ng b iỷ ệ ể ặ ượ ướ ượ ở
$ $
l
q 1 p N
= − =
Khi đó s cá th có đc tính A trong m u th i (m u rút t t pố ể ặ ẫ ứ ẫ ừ ậ
h p chính ợHi) s x p x b ngẽ ấ ỉ ằ
ᄉ
$
i
ii
n m
m n p N
= =
và s cá th không có đc tính A trong m u th i s x p x b ngố ể ặ ẫ ứ ẽ ấ ỉ ằ
$
ii i l
i n q n N
= =
$
Các s ố
ᄉ
i
m
và
i
i
$
đc g i là các t n s lý thuy t (TSLT), cònượ ọ ầ ố ế
các s mối, li đc g i là các t n s quan sát (TSQS).ượ ọ ầ ố
Ta quy t đnh bác b Hế ị ỏ o khi TSLT cách xa TSQS m t cáchộ
“b t th ng”. Kho ng cách gi a TSQS và TSLT đc đo b ng testấ ườ ả ữ ượ ằ
th ng kê sau đây:ố
ᄉ
( )
ᄉ
( )
22
k k
ii
ii
i
i
i 1 i 1
m m l l
Tl
m
= =
−−
= +
� � $
$
Ng i ta ch ng minh đc r ng n u Hườ ứ ượ ằ ế o đúng và các t n s lýầ ố
thuy t không nh thua 5 thì T s có phân b x p x phân b ế ỏ ẽ ố ấ ỉ ố
2
χ
v iớ
k – 1 b c t do. Thành th mi n bác b Hậ ự ử ề ỏ o có d ng {T > c}, đó cạ ở
đc tìm t đi u ki n P{T > c} = ượ ừ ề ệ . V y c chính là phân v m c ậ ị ứ
c a phân b ủ ố
2
χ
v i k – 1 b c t doớ ậ ự .
Chú ý. Test th ng kê T có th bi n đi nh sau.ố ể ế ổ ư
Ta có:
2
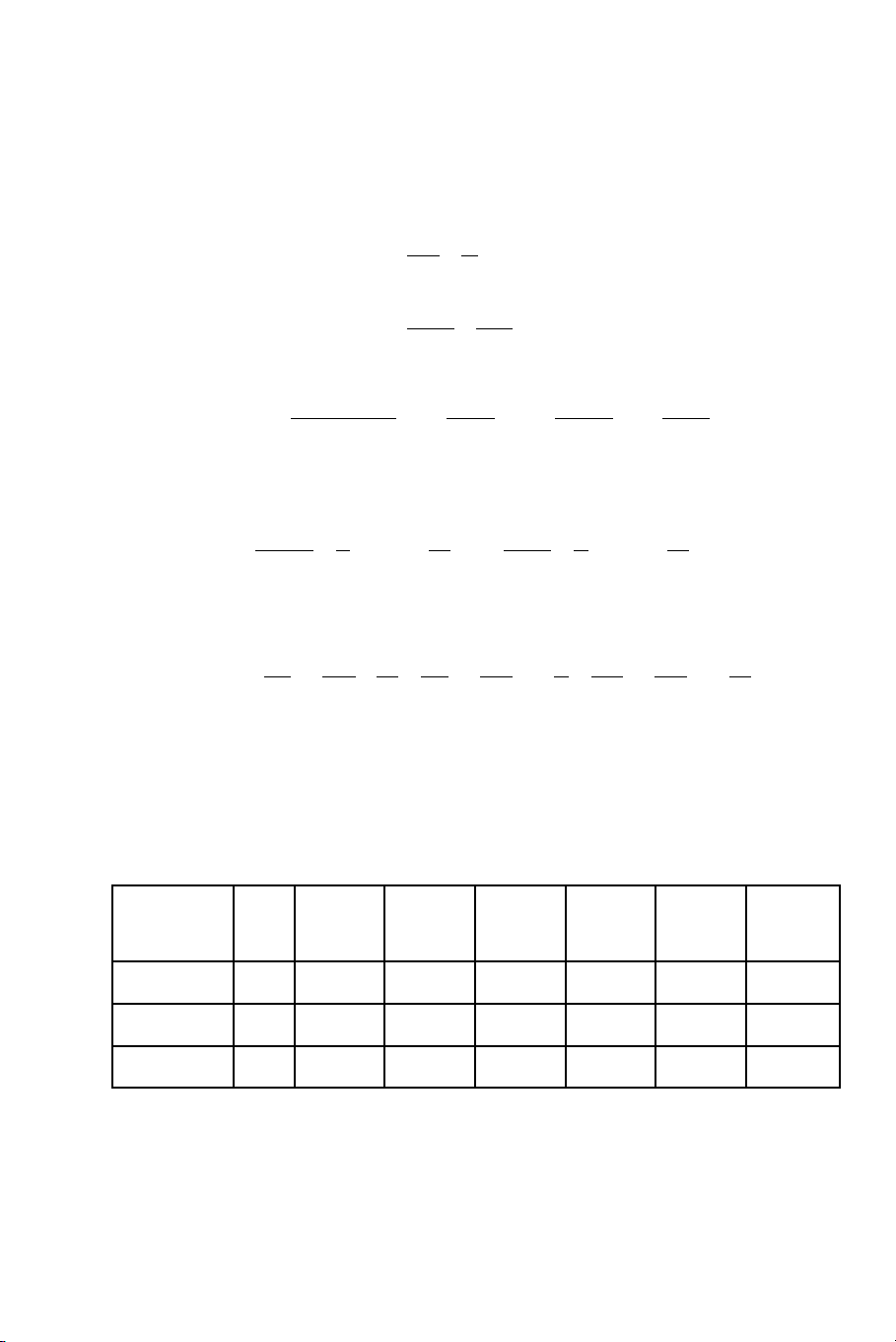
( )
$
( )
$
( )
ᄉ
( )
22
2 2
i i
i i i i i i i
l l n m n 1 p m n p m m
� �
− = − − − = − = −
� �
$
Do đó
ᄉ
( )
ᄉ
ᄉ
( )
$ $
ᄉ
( )
$ $
ᄉ
$
ᄉ
$
2
i
ii
1
2
i
ii i
1
22
k2
i
iio
i i
i 1 i i i i
1 1
T m m l
m
1 1
m m n p n q
m m m m m m
2
n pq n pq n pq n pq
=
� �
= − +
� �
� �
� �
= − +
� �
� �
� �
−
= = − +
� � � �
$
Chú ý r ng ằ
ᄉ
$ $ $
ᄉ
$ $
ᄉ
$
;
2
i1
ii
i
i i
m m 1 m m 1 m
m m
n pq q q n pq q q
= = = =
� � � �
V y ậ
$ $ $
$
$
2 2 2
2
i i i
i i i
m m m
1 m 1 p N m
T N N
n n ml n l
pq q pq q
= − = − = −
� � �
N u s d ng công th c này ta s không c n tính các t n s lýế ử ụ ứ ẽ ầ ầ ố
thuy t, do đó nó đc dùng trong th c hành.ế ượ ự
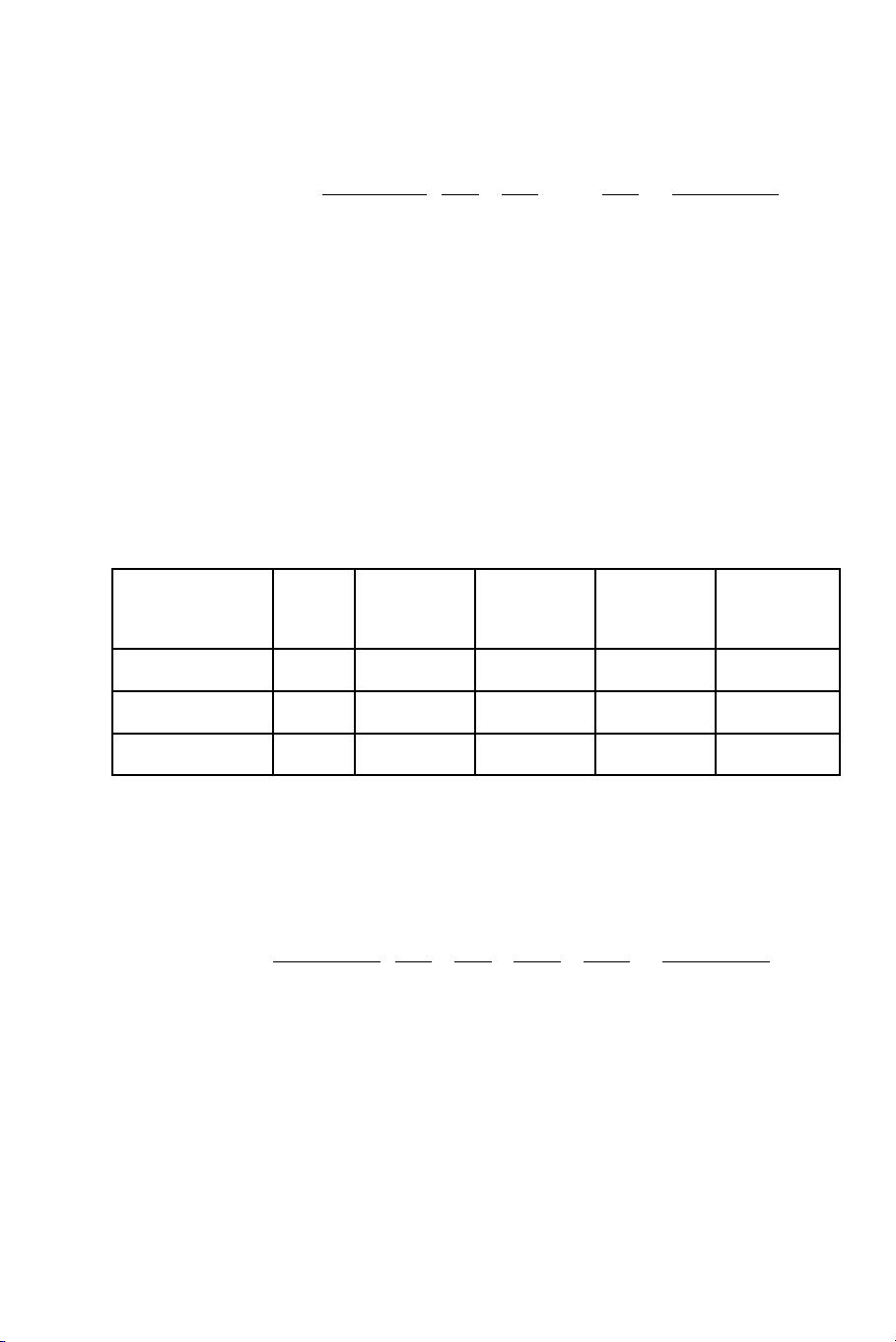
Ví d 1.ụ So sánh tác d ng c a 6 m u thu c th nghi m trên 6ụ ủ ẫ ố ử ệ
lô chu t, k t qu thu đc nh sau:ộ ế ả ượ ư
M uẫ
thu cố
1 2 3 4 5 6 T ngổ
S s ngố ố 79 82 77 83 76 81 478
S ch tố ế 21 18 23 17 24 19 122
T ng ổ100 100 100 100 100 100 600
Ta mu n ki m đnh gi thi tố ể ị ả ế
Ho: T l ch t trong 6 m u thu c là nh nhauỷ ệ ế ẫ ố ư
Đi thi tố ế H1: T l ch t trong 6 m u thu c là khác nhauỷ ệ ế ẫ ố
3
Gi i ả
Ta có
� �
= + + + −
� �
� �
L
2 2 2 2
600 79 82 81 (600)(478)
T(478)(122) 100 100 100 122
= − =2353,24 2350,81 2,42
V i m c ý nghĩa ớ ứ = 5%, tra b ng phân b ả ố
χ
2
v i 5 b c t do taớ ậ ự
có
χ =
2
0,05 11,07
Vì T < c nên ta ch p nh n Hấ ậ o. J
Ví d 2.ụ Có 4 th y giáo A, B, C, D cùng d y m t giáo trìnhầ ạ ộ
th ng kê. Ban ch nhi m khoa mu n tìm hi u ch t l ng d y c a 4ố ủ ệ ố ể ấ ượ ạ ủ
th y này nên đã làm m t cu c kh o sát. K t qu nh sau:ầ ộ ộ ả ế ả ư
Th y ầ
K t quế ả A B C D T ngổ
Đt ạ60 75 150 125 410
Không đtạ40 75 50 75 240
T ng ổ100 150 200 200 650
V i m c ý nghĩa ớ ứ = 0,01 có th cho r ng t l h c sinh để ằ ỷ ệ ọ ỗ
trong các h c sinh đã h c các th y trên là nh nhau hay không?ọ ọ ầ ư
Gi i.ả Ta có
� �
= + + + −
� �
� �
= − =
2 2 2 2 2
(650) 60 75 150 125 (650)(410)
T(410)(240) 100 150 200 200 240
1134,07 1110,41 23,65
S b c t do là 3 và ố ậ ự
χ =
2
0,01 11,343
. Vì T > c nên ta bác b giỏ ả
thuy t Hếo. T l h c sinh đ c a các th y A, B, C, D nh nhau.ỳ ệ ọ ỗ ủ ầ ư
§ 2. SO SÁNH CÁC PHÂN S Ố
Xét m t b ộ ộ A g m r tính tr ng, ồ ạ A = (A1, A2, ...Ar), trong đó m iỗ
cá th c a t p h p chính ể ủ ậ ợ H có và ch có m t trong các tính tr ngỉ ộ ạ
4

(hay ph m trù) Aại.
G i pọi (i = 1, 2, ... r) là t l cá th tính tr ng Aỷ ệ ể ạ i trong t pậ
h p chính H. Khi đó véct ợ ơ = (p1, p2, ...pr) đc g i là phân bượ ọ ố
c a ủA trong t p h p chính H.ậ ợ
Ch ng h n, m i ng i đi làm có th s d ng m t trong cácẳ ạ ọ ườ ể ử ụ ộ
ph ng ti n sau: đi b , đi xe đp, đi xe máy, đi xe buýt. Trongươ ệ ộ ạ
thành ph X có 18% đi b , 32% đi xe đp, 40% đi xe máy và 10%ố ộ ạ
đi xe buýt. Nh v y ư ậ = (0,18; 0,32; 0,4; 0,1) là phân b c a cáchố ủ
đi làm (A ) trong t p h p các dân c c a thành ph X.ậ ợ ư ủ ố
T ng t m i ng i có th đc x p vào 1 trong 3 ph mươ ự ỗ ườ ể ượ ế ạ
trù sau: r t h nh phúc, b t h nh, ho c có th đc x p vào 1ấ ạ ấ ạ ặ ể ượ ế
trong 3 l p sau: d i 25 tu i, trong kho ng t 25 đn 45 tu i,ớ ướ ổ ả ừ ế ổ
trên 45 tu i... có th d n ra r t nhi u ví d t ng t nh v y.ổ ể ẫ ấ ề ụ ươ ự ư ậ
Gi s (pả ử 1, p2,...pr) là phân b c a (Aố ủ 1, A2,...Ar) trong t pậ
h p chính H và (qợ1, q2,...qr) là phân b c a ố ủ A = (A1, A2,...Ar) trong
t p h p chính Y. Ta nói (Aậ ợ 1, A2...Ar) có phân b nh nhau trongố ư
X và Y n u (pế1, p2,...pr) = (q1, q2,...rr) p1 = q1,...pr = qr.
Chúng ta mu n ki m đnh xem ố ể ị A = (A1, A2,...Ar) có cùng
phân s trong X và Y hay không d a trên các m u ng u nhiên rútố ự ẫ ẫ
t X và Y.ừ
T ng quát h n, gi s ta có k t p h p chính Hổ ơ ả ử ậ ợ 1, H2,...Hk.
G i ọ
( )
π = K
i i i i
1 2 r
p ,p , p
là phân b c a ố ủ A = (A1, A2,...Ar) trong t pậ
h p chính Hợi.
Ta mu n ki m đnh gi thuy t sauố ể ị ả ế
π = π = = πK
1 2 k
o
H :
(Các phân b này là nh nhau trên cácố ư
t p h p chính Hậ ợ i).
Chú ý r ng Hằo t ng đng v i h đng th c sau:ươ ươ ớ ệ ẳ ứ
= = =
= = =
= = =
= = =
K
K
K
K
1 2 k
1 1 1
1 2 k
2 2 2
1 2 k
i i i
1 2 k
r r r
p p p
p p p
p p p
p p p
5


























%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23fff;%20}%20.st1%20{%20fill:%20%237800fa;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st1'%20d='M117.78,12.18H43.11c2.9,3.47,4.65,7.94,4.65,12.82,0,5.6-2.3,10.66-6.01,14.29h76.02l7.22-13.56-7.22-13.56Z'/%3e%3cg%3e%3cpath%20class='st0'%20d='M53.58,26.17h-.59v-1.46h.59v-4.96h2.83c1.78,0,2.67.94,2.67,2.82v5.76c0,1.87-.89,2.81-2.67,2.81h-2.83v-4.96ZM55.36,21.37v3.34h1.1v1.46h-1.1v3.34h1.01c.61,0,.91-.37.91-1.1v-5.93c0-.74-.3-1.1-.91-1.1h-1.01Z'/%3e%3cpath%20class='st0'%20d='M65.99,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM65.28,18.04c-.25.46-.51.77-.75.94-.21.15-.47.22-.79.22-.26,0-.57-.07-.92-.22l-.38-.15c-.14-.05-.26-.07-.37-.07-.3,0-.53.18-.71.54l-.91-.68c.25-.46.51-.77.75-.94.21-.14.48-.21.79-.21.26,0,.57.07.92.21l.38.15c.14.05.26.07.37.07.3,0,.53-.18.71-.54l.91.68ZM61.91,27.52h1.73l-.87-5.76-.87,5.76Z'/%3e%3cpath%20class='st0'%20d='M74.53,26.89v1.52c0,1.91-.89,2.86-2.67,2.86s-2.67-.95-2.67-2.86v-5.93c0-1.91.89-2.86,2.67-2.86s2.67.95,2.67,2.86v1.11h-1.69v-1.22c0-.75-.31-1.12-.93-1.12s-.93.37-.93,1.12v6.15c0,.74.31,1.11.93,1.11s.93-.37.93-1.11v-1.63h1.69Z'/%3e%3cpath%20class='st0'%20d='M81.4,31.14h-1.8l-.31-2.07h-2.19l-.31,2.07h-1.64l1.82-11.39h2.62l1.82,11.39ZM75.9,19.2l1.52-1.91h1.71l1.51,1.91h-1.61l-.76-.95-.75.95h-1.61ZM77.32,27.52h1.73l-.87-5.76-.87,5.76ZM83.1,15.99l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M84.86,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM84.01,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M93.51,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM92.66,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3cpath%20class='st0'%20d='M98.8,31.14h-1.79v-11.39h1.79v4.88h2.03v-4.88h1.83v11.39h-1.83v-4.88h-2.03v4.88Z'/%3e%3cpath%20class='st0'%20d='M105.36,24.55h2.46v1.62h-2.46v3.34h3.09v1.63h-4.88v-11.39h4.88v1.63h-3.09v3.18ZM108.17,17.29l-1.76,1.91h-1.26l1.17-1.91h1.86Z'/%3e%3cpath%20class='st0'%20d='M112.2,19.75c1.78,0,2.67.94,2.67,2.82v1.48c0,1.87-.89,2.81-2.67,2.81h-.85v4.28h-1.79v-11.39h2.64ZM111.35,21.37v3.86h.85c.58,0,.87-.36.87-1.08v-1.71c0-.71-.29-1.07-.87-1.07h-.85Z'/%3e%3c/g%3e%3ccircle%20class='st1'%20cx='25'%20cy='25'%20r='20'/%3e%3cpath%20class='st0'%20d='M32.78,19.27c2.92,0,4.43,2.55,5.28,5.33l.71,2.17c.14.38-.33.75-.71.75h-5.61c.19-.33.24-.71.09-1.08l-.75-2.45c-.43-1.32-.99-2.64-1.79-3.77.75-.57,1.65-.94,2.78-.94h0ZM25,18.38c3.25,0,4.9,2.78,5.89,5.89l.76,2.45c.14.42-.33.8-.8.8h-11.69c-.42,0-.94-.38-.8-.8l.75-2.45c.99-3.11,2.64-5.89,5.89-5.89h0ZM25,11.35c1.74,0,3.11,1.37,3.11,3.11s-1.37,3.11-3.11,3.11-3.11-1.41-3.11-3.11,1.41-3.11,3.11-3.11h0ZM17.27,19.27c1.08,0,1.98.38,2.73.94-.8,1.13-1.37,2.45-1.74,3.77l-.8,2.45c-.14.38-.05.75.09,1.08h-5.56c-.42,0-.9-.38-.75-.75l.71-2.17c.9-2.78,2.41-5.33,5.33-5.33h0ZM17.27,12.91c1.51,0,2.78,1.27,2.78,2.83s-1.27,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM32.78,12.91c1.56,0,2.78,1.27,2.78,2.83s-1.23,2.83-2.78,2.83-2.83-1.27-2.83-2.83,1.27-2.83,2.83-2.83h0ZM27.07,28.56v.09c0,.57-.24,1.08-.61,1.46h0v.05c-.38.33-.9.57-1.46.57s-1.08-.24-1.46-.61h0c-.38-.38-.61-.9-.61-1.46v-.09h1.41v.09c0,.19.05.38.19.47v.05c.09.09.28.19.47.19s.38-.09.47-.19v-.05c.14-.09.24-.28.24-.47t-.05-.09h1.41ZM30.99,28.56v.09c0,1.65-.66,3.16-1.74,4.24-1.08,1.08-2.59,1.79-4.24,1.79s-3.16-.71-4.24-1.79l-.05-.05c-1.04-1.08-1.7-2.55-1.7-4.2v-.09h1.41v.09c0,1.27.47,2.4,1.27,3.25h.05c.85.85,1.98,1.37,3.25,1.37s2.4-.52,3.25-1.37c.85-.8,1.37-1.98,1.37-3.25v-.09h1.37ZM34.99,28.56v.09c0,2.78-1.13,5.28-2.92,7.07-1.79,1.79-4.29,2.92-7.07,2.92s-5.23-1.13-7.07-2.92c-1.79-1.79-2.92-4.29-2.92-7.07v-.09h1.41v.09c0,2.4.94,4.53,2.5,6.08,1.56,1.56,3.72,2.5,6.08,2.5s4.52-.94,6.08-2.5c1.56-1.56,2.5-3.68,2.5-6.08v-.09h1.41Z'/%3e%3c/svg%3e)